


钟小言
致力于为您提供丰富而有趣的内容,旨在启发思考、分享知识。
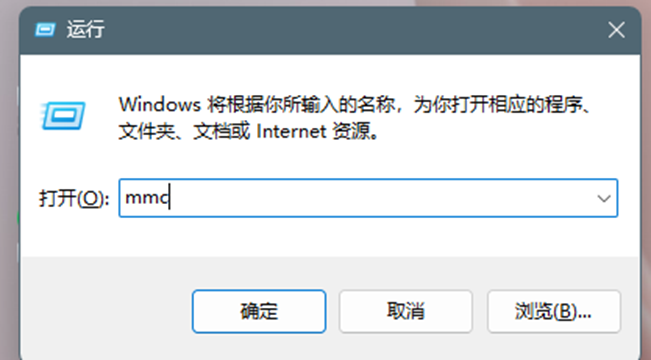
Exchange 2013/2016安装SSL证书步骤
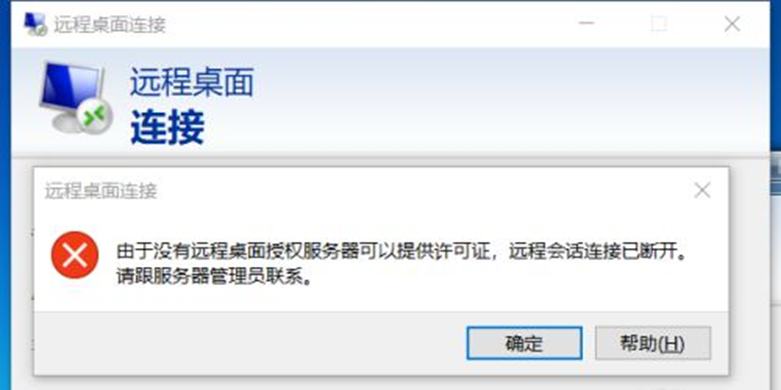
【Windows Server】由于没有远程桌面授权服务器可以提供许可

openEuler-22.03-LTS部署kubernetes

VNC一款超好用的局域网远程控制工具

DeepSeek本地部署,保姆级教程,带你打造最强AI
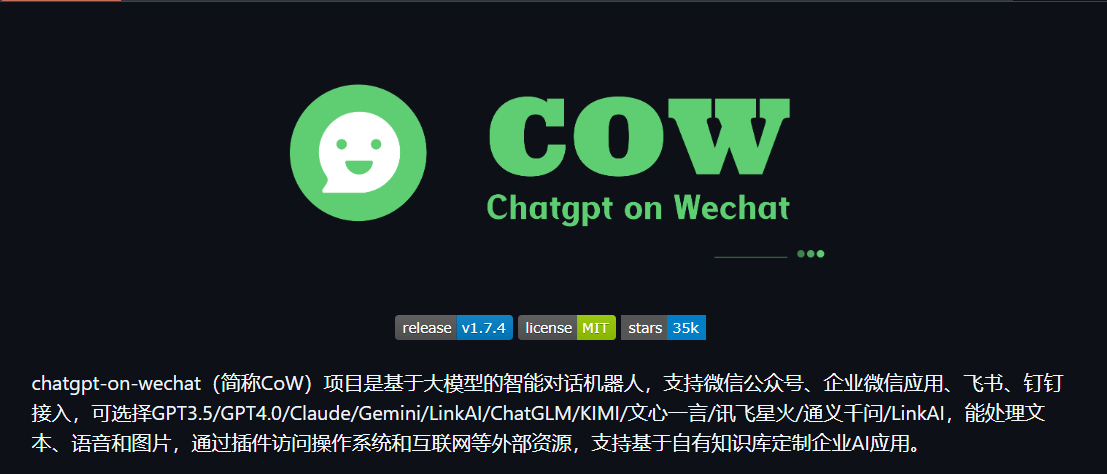
chatgpt-on-wechat 项目多种部署方式

DeepSeek本地部署,保姆级教程,带你打造最强AI
- 最新文章
-
置顶 DeepSeek本地部署,保姆级教程,带你打造最强AI deepseek本地部署 第一步:安装ollama https://ollama.com/download 第二步:在ollama 官网搜索 https://ollama.com/ 模型大小与显卡需求 第三步:在终端执行 命令 等待安装即可 第五步:基本命令 #退出模型 >>> /bye #查看模型 C:\Users\chk>ollama list NAME ID SIZE MODIFIED deepseek-r1:1.5b a42b25d8c10a 1.1 GB 3 minutes ago #启动模型 ollama run deepseek-r1:1.5b >>> #查看帮助 C:\Users\chk>ollama -h Large language model runner Usage: ollama [flags] ollama [command] Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model stop Stop a running model pull Pull a model from a registry push Push a model to a registry list List models ps List running models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information Use "ollama [command] --help" for more information about a command. 可视化部署Web UI 第一步:下载Chatbox AI https://chatboxai.app/zh 设置中文 第二步:将 Chatbox 连接到远程 Ollama 服务 1.在 Windows 上配置环境变量 在 Windows 上,Ollama 会继承你的用户和系统环境变量。 通过任务栏退出 Ollama。 打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。 点击编辑你账户的环境变量。 为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 *。 点击确定/应用以保存设置。 从 Windows 开始菜单启动 Ollama 应用程序。 2.服务 IP 地址 配置后,Ollama 服务将能在当前网络(如家庭 Wifi)中提供服务。你可以使用其他设备上的 Chatbox 客户端连接到此服务。Ollama 服务的 IP 地址是你电脑在当前网络中的地址。 3.注意事项 可能需要在防火墙中允许 Ollama 服务的端口(默认为 11434),具体取决于你的操作系统和网络环境。 为避免安全风险,请不要将 Ollama 服务暴露在公共网络中。家庭 Wifi 网络是一个相对安全的环境。 4.Chatbox配置模型
-
 置顶 openEuler-22.03-LTS部署kubernetes 一、安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: • 一台或多台机器,操作系统 欧拉系统 • 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多 • 集群中所有机器之间网络互通 • 可以访问外网,需要拉取镜像 • 禁止swap分区 1.2 主机硬件配置说明 CPU 内存 角色 主机名 4C 4G Master k8s-master 4C 4G Node01 k8s-node01 4C 4G Node02 k8s-node02 二、主机准备 2.1 主机名配置 由于本次使用3台主机完成kubernetes集群部署,其中1台为master节点,名称为k8s-master01;其中2台为node节点,名称分别为:k8s-node01及k8s-node02 master节点 hostnamectl set-hostname k8s-master01 node01节点 hostnamectl set-hostname k8s-node01 node02节点 hostnamectl set-hostname k8s-node02 在master添加hosts: cat >> /etc/hosts << EOF 192.168.10.1 k8s-master 192.168.10.2 k8s-node1 192.168.10.3 k8s-node2 EOF 2.2 主机IP地址配置 k8s-master01节点IP地址为:192.168.10.1/24 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="none" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" DEVICE="ens33" ONBOOT="yes" IPADDR="192.168.10.1" PREFIX="24" GATEWAY="192.168.10.254" DNS1="8.8.8.8" k8s-node01节点IP地址为:192.168.10.2/24 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="none" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" DEVICE="ens33" ONBOOT="yes" IPADDR="192.168.10.2" PREFIX="24" GATEWAY="192.168.10.254" DNS1="8.8.8.8" k8s-node02节点IP地址为:192.168.10.3/24 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="none" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" DEVICE="ens33" ONBOOT="yes" IPADDR="192.168.10.3" PREFIX="24" GATEWAY="192.168.10.254" DNS1="8.8.8.8" 2.3 主机名与IP地址解析 所有集群主机均需要进行配置。 cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.1 k8s-master01 192.168.10.2 k8s-node01 192.168.10.3 k8s-node02 2.4 防火墙配置 所有主机均需要操作。 关闭现有防火墙firewalld systemctl disable firewalld systemctl stop firewalld firewall-cmd --state not running 2.5 SELINUX配置 所有主机均需要操作。修改SELinux配置需要重启操作系统。 sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config 2.6 时间同步配置 所有主机均需要操作。最小化安装系统需要安装ntpdate软件。 yum install ntpdate -y ntpdate time1.aliyun.com 修改时区 ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime 修改语言 sudo echo 'LANG="en_US.UTF-8"' >> /etc/profile;source /etc/profile 2.7 配置内核转发及网桥过滤 所有主机均需要操作。 将桥接的IPv4流量传递到iptables的链: cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-iptables=1 net.bridge.bridge-nf-call-ip6tables=1 net.ipv4.ip_forward=1 net.ipv4.tcp_tw_recycle=0 vm.swappiness=0 vm.overcommit_memory=1 vm.panic_on_oom=0 fs.inotify.max_user_instances=8192 fs.inotify.max_user_watches=1048576 fs.file-max=52706963 fs.nr_open=52706963 net.ipv6.conf.all.disable_ipv6=1 net.netfilter.nf_conntrack_max=2310720 EOF sysctl --system 开启内核路由转发 vi /etc/sysctl.conf net.ipv4.ip_forward=1 添加网桥过滤及内核转发配置文件 cat /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 vm.swappiness = 0 加载br_netfilter模块 modprobe br_netfilter 查看是否加载 lsmod | grep br_netfilter br_netfilter 22256 0 bridge 151336 1 br_netfilter 使用默认配置文件生效 sysctl -p 使用新添加配置文件生效 sysctl -p /etc/sysctl.d/k8s.conf 2.8 安装ipset及ipvsadm 所有主机均需要操作。 安装ipset及ipvsadm yum -y install ipset ipvsadm 配置ipvsadm模块加载方式 添加需要加载的模块 cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack EOF 授权、运行、检查是否加载 chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack 2.9 关闭SWAP分区 修改完成后需要重启操作系统,如不重启,可临时关闭,命令为swapoff -a 临时关闭 swapoff -a 永远关闭swap分区,需要重启操作系统 cat /etc/fstab ...... # /dev/mapper/openeuler-swap none swap defaults 0 0 在上一行中行首添加# 三、容器运行时工具安装及运行 查看是否存在docker软件 yum list | grep docker pcp-pmda-docker.x86_64 5.3.7-2.oe2203sp1 docker-client-java.noarch 8.11.7-2.oe2203sp1 docker-client-java.src 8.11.7-2.oe2203sp1 docker-compose.noarch 1.22.0-4.oe2203sp1 docker-compose.src 1.22.0-4.oe2203sp1 docker-engine.src 2:18.09.0-316.oe220 docker-engine.x86_64 2:18.09.0-316.oe220 docker-engine.x86_64 2:18.09.0-316.oe220 docker-engine-debuginfo.x86_64 2:18.09.0-316.oe220 docker-engine-debugsource.x86_64 2:18.09.0-316.oe220 docker-runc.src 1.1.3-9.oe2203sp1 docker-runc.x86_64 1.1.3-9.oe2203sp1 podman-docker.noarch 1:0.10.1-12.oe2203s python-docker.src 5.0.3-1.oe2203sp1 python-docker-help.noarch 5.0.3-1.oe2203sp1 python-docker-pycreds.src 0.4.0-2.oe2203sp1 python-dockerpty.src 0.4.1-3.oe2203sp1 python-dockerpty-help.noarch 0.4.1-3.oe2203sp1 python3-docker.noarch 5.0.3-1.oe2203sp1 python3-docker-pycreds.noarch 0.4.0-2.oe2203sp1 python3-dockerpty.noarch 0.4.1-3.oe2203sp1 安装docker dnf install docker Last metadata expiration check: 0:53:18 ago on Dependencies resolved. =============================================================================== Package Architecture Version Repository Size =============================================================================== Installing: docker-engine x86_64 2:18.09.0-316.oe2203sp1 OS 38 M Installing dependencies: libcgroup x86_64 0.42.2-3.oe2203sp1 OS Transaction Summary =============================================================================== Install 2 Packages Total download size: 39 M Installed size: 160 M Is this ok [y/N]: y Downloading Packages: (1/2): libcgroup-0.42.2-3.oe2203sp1.x86_64.rpm 396 kB/s | 96 kB 00:00 (2/2): docker-engine-18.09.0-316.oe2203sp1.x86_64.rpm 10 MB/s | 38 MB 00:03 -------------------------------------------------------------------------------- Total 10 MB/s | 39 MB 00:03 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Running scriptlet: libcgroup-0.42.2-3.oe2203sp1.x86_64 1/2 Installing : libcgroup-0.42.2-3.oe2203sp1.x86_64 1/2 Running scriptlet: libcgroup-0.42.2-3.oe2203sp1.x86_64 1/2 Installing : docker-engine-2:18.09.0-316.oe2203sp1.x86_64 2/2 Running scriptlet: docker-engine-2:18.09.0-316.oe2203sp1.x86_64 2/2 Created symlink /etc/systemd/system/multi-user.target.wants/docker.service → /usr/lib/systemd/system/docker.service. Verifying : docker-engine-2:18.09.0-316.oe2203sp1.x86_64 1/2 Verifying : libcgroup-0.42.2-3.oe2203sp1.x86_64 2/2 Installed: docker-engine-2:18.09.0-316.oe2203sp1.x86_64 libcgroup-0.42.2-3.oe2203sp1.x86_64 Complete! 设置docker开机启动并启动 systemctl enable --now docker 查看docker版本 docker version Client: Version: 18.09.0 EulerVersion: 18.09.0.316 API version: 1.39 Go version: go1.17.3 Git commit: 9b9af2f Built: Tue Dec 27 14:25:30 2022 OS/Arch: linux/amd64 Experimental: false Server: Engine: Version: 18.09.0 EulerVersion: 18.09.0.316 API version: 1.39 (minimum version 1.12) Go version: go1.17.3 Git commit: 9b9af2f Built: Tue Dec 27 14:24:56 2022 OS/Arch: linux/amd64 Experimental: false 四、K8S软件安装 安装k8s依赖,连接跟踪 dnf install conntrack k8s master节点安装 dnf install -y kubernetes-kubeadm kubernetes-kubelet kubernetes-master k8s worker节点安装 dnf install -y kubernetes-kubeadm kubernetes-kubelet kubernetes-node systemctl enable kubelet 五、K8S集群初始化master kubeadm init --apiserver-advertise-address=192.168.10.1 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.20.2 --service-cidr=10.1.0.0/16 --pod-network-cidr=10.244.0.0/16 输出: [init] Using Kubernetes version: v1.20.2 [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [WARNING FileExisting-socat]: socat not found in system path [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [k8s-master01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.1.0.1 192.168.10.1] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.10.1 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.10.1 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 6.502722 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.20" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node k8s-master01 as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)" [mark-control-plane] Marking the node k8s-master01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: jvx2bb.pfd31288qyqcfsn7 [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.10.1:6443 --token jvx2bb.pfd31288qyqcfsn7 \ --discovery-token-ca-cert-hash sha256:740fa71f6c5acf156195ce6989cb49b7a64fd061b8bf56e4b1b684cbedafbd40 [root@k8s-master01 ~]# mkdir -p $HOME/.kube [root@k8s-master01 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@k8s-master01 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config 六、K8S集群工作节点加入 [root@k8s-node01 ~]kubeadm join 192.168.10.1:6443 --token jvx2bb.pfd31288qyqcfsn7 \ --discovery-token-ca-cert-hash sha256:740fa71f6c5acf156195ce6989cb49b7a64fd061b8bf56e4b1b684cbedafbd40 # [root@k8s-node02 ~]kubeadm join 192.168.10.1:6443 --token jvx2bb.pfd31288qyqcfsn7 \ --discovery-token-ca-cert-hash sha256:740fa71f6c5acf156195ce6989cb49b7a64fd061b8bf56e4b1b684cbedafbd40 [root@k8s-master01 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master01 NotReady control-plane,master 3m59s v1.20.2 k8s-node01 NotReady <none> 18s v1.20.2 k8s-node02 NotReady <none> 10s v1.20.2 七、K8S集群网络插件使用 [root@k8s-master01 ~]# wget https://docs.projectcalico.org/v3.19/manifests/calico.yaml 由于网络问题,我这边使用离线方式安装插件calico 1. 去github上面下载自己所需的calico离线包,项目地址: https://github.com/projectcalico/calico 2. 假设要安装最新版本v3.28.0,首先可以下载这个版本的calico.yaml,具体命令是 curl -O -L https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/calico.yaml 3. 下载完成之后可以通过calico.yaml查看需要安装哪些离线包,命令是: cat calico.yaml | grep image image: docker.io/calico/cni:v3.28.0 imagePullPolicy: IfNotPresent image: docker.io/calico/cni:v3.28.0 imagePullPolicy: IfNotPresent image: docker.io/calico/node:v3.28.0 imagePullPolicy: IfNotPresent image: docker.io/calico/node:v3.28.0 imagePullPolicy: IfNotPresent image: docker.io/calico/kube-controllers:v3.28.0 imagePullPolicy: IfNotPresent 4. 通过上述命令,查看到需要安装calico-cni.tar, calico-kube-controllers.tar 和 calico-node.tar三个包,然后需要将这三个包导入到k8s的命名空间中 使用导入命令将这三个包导入到k8s的命名空间中: docker load -i calico-cni.tar docker load -i calico-node.tar docker load -i calico-kube-controllers.tar 5. 导入之后就可以apply calico.yaml 文件了 6. 导入之后查看calico的pod,发现calico和coredns已经起来了 kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-8d76c5f9b-brv86 1/1 Running 0 22h calico-node-hxks2 1/1 Running 0 22h coredns-66f779496c-9hqsx 1/1 Running 0 23h coredns-66f779496c-rcc74 1/1 Running 0 23h etcd-kevin-pc 1/1 Running 4 (28m ago) 23h kube-apiserver-kevin-pc 1/1 Running 4 (28m ago) 23h kube-controller-manager-kevin-pc 1/1 Running 4 (28m ago) 23h kube-proxy-gglh4 1/1 Running 1 (28m ago) 23h kube-scheduler-kevin-pc 1/1 Running 4 (28m ago) 23h
置顶 openEuler-22.03-LTS部署kubernetes 一、安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: • 一台或多台机器,操作系统 欧拉系统 • 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多 • 集群中所有机器之间网络互通 • 可以访问外网,需要拉取镜像 • 禁止swap分区 1.2 主机硬件配置说明 CPU 内存 角色 主机名 4C 4G Master k8s-master 4C 4G Node01 k8s-node01 4C 4G Node02 k8s-node02 二、主机准备 2.1 主机名配置 由于本次使用3台主机完成kubernetes集群部署,其中1台为master节点,名称为k8s-master01;其中2台为node节点,名称分别为:k8s-node01及k8s-node02 master节点 hostnamectl set-hostname k8s-master01 node01节点 hostnamectl set-hostname k8s-node01 node02节点 hostnamectl set-hostname k8s-node02 在master添加hosts: cat >> /etc/hosts << EOF 192.168.10.1 k8s-master 192.168.10.2 k8s-node1 192.168.10.3 k8s-node2 EOF 2.2 主机IP地址配置 k8s-master01节点IP地址为:192.168.10.1/24 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="none" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" DEVICE="ens33" ONBOOT="yes" IPADDR="192.168.10.1" PREFIX="24" GATEWAY="192.168.10.254" DNS1="8.8.8.8" k8s-node01节点IP地址为:192.168.10.2/24 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="none" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" DEVICE="ens33" ONBOOT="yes" IPADDR="192.168.10.2" PREFIX="24" GATEWAY="192.168.10.254" DNS1="8.8.8.8" k8s-node02节点IP地址为:192.168.10.3/24 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="none" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" DEVICE="ens33" ONBOOT="yes" IPADDR="192.168.10.3" PREFIX="24" GATEWAY="192.168.10.254" DNS1="8.8.8.8" 2.3 主机名与IP地址解析 所有集群主机均需要进行配置。 cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.1 k8s-master01 192.168.10.2 k8s-node01 192.168.10.3 k8s-node02 2.4 防火墙配置 所有主机均需要操作。 关闭现有防火墙firewalld systemctl disable firewalld systemctl stop firewalld firewall-cmd --state not running 2.5 SELINUX配置 所有主机均需要操作。修改SELinux配置需要重启操作系统。 sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config 2.6 时间同步配置 所有主机均需要操作。最小化安装系统需要安装ntpdate软件。 yum install ntpdate -y ntpdate time1.aliyun.com 修改时区 ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime 修改语言 sudo echo 'LANG="en_US.UTF-8"' >> /etc/profile;source /etc/profile 2.7 配置内核转发及网桥过滤 所有主机均需要操作。 将桥接的IPv4流量传递到iptables的链: cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-iptables=1 net.bridge.bridge-nf-call-ip6tables=1 net.ipv4.ip_forward=1 net.ipv4.tcp_tw_recycle=0 vm.swappiness=0 vm.overcommit_memory=1 vm.panic_on_oom=0 fs.inotify.max_user_instances=8192 fs.inotify.max_user_watches=1048576 fs.file-max=52706963 fs.nr_open=52706963 net.ipv6.conf.all.disable_ipv6=1 net.netfilter.nf_conntrack_max=2310720 EOF sysctl --system 开启内核路由转发 vi /etc/sysctl.conf net.ipv4.ip_forward=1 添加网桥过滤及内核转发配置文件 cat /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 vm.swappiness = 0 加载br_netfilter模块 modprobe br_netfilter 查看是否加载 lsmod | grep br_netfilter br_netfilter 22256 0 bridge 151336 1 br_netfilter 使用默认配置文件生效 sysctl -p 使用新添加配置文件生效 sysctl -p /etc/sysctl.d/k8s.conf 2.8 安装ipset及ipvsadm 所有主机均需要操作。 安装ipset及ipvsadm yum -y install ipset ipvsadm 配置ipvsadm模块加载方式 添加需要加载的模块 cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack EOF 授权、运行、检查是否加载 chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack 2.9 关闭SWAP分区 修改完成后需要重启操作系统,如不重启,可临时关闭,命令为swapoff -a 临时关闭 swapoff -a 永远关闭swap分区,需要重启操作系统 cat /etc/fstab ...... # /dev/mapper/openeuler-swap none swap defaults 0 0 在上一行中行首添加# 三、容器运行时工具安装及运行 查看是否存在docker软件 yum list | grep docker pcp-pmda-docker.x86_64 5.3.7-2.oe2203sp1 docker-client-java.noarch 8.11.7-2.oe2203sp1 docker-client-java.src 8.11.7-2.oe2203sp1 docker-compose.noarch 1.22.0-4.oe2203sp1 docker-compose.src 1.22.0-4.oe2203sp1 docker-engine.src 2:18.09.0-316.oe220 docker-engine.x86_64 2:18.09.0-316.oe220 docker-engine.x86_64 2:18.09.0-316.oe220 docker-engine-debuginfo.x86_64 2:18.09.0-316.oe220 docker-engine-debugsource.x86_64 2:18.09.0-316.oe220 docker-runc.src 1.1.3-9.oe2203sp1 docker-runc.x86_64 1.1.3-9.oe2203sp1 podman-docker.noarch 1:0.10.1-12.oe2203s python-docker.src 5.0.3-1.oe2203sp1 python-docker-help.noarch 5.0.3-1.oe2203sp1 python-docker-pycreds.src 0.4.0-2.oe2203sp1 python-dockerpty.src 0.4.1-3.oe2203sp1 python-dockerpty-help.noarch 0.4.1-3.oe2203sp1 python3-docker.noarch 5.0.3-1.oe2203sp1 python3-docker-pycreds.noarch 0.4.0-2.oe2203sp1 python3-dockerpty.noarch 0.4.1-3.oe2203sp1 安装docker dnf install docker Last metadata expiration check: 0:53:18 ago on Dependencies resolved. =============================================================================== Package Architecture Version Repository Size =============================================================================== Installing: docker-engine x86_64 2:18.09.0-316.oe2203sp1 OS 38 M Installing dependencies: libcgroup x86_64 0.42.2-3.oe2203sp1 OS Transaction Summary =============================================================================== Install 2 Packages Total download size: 39 M Installed size: 160 M Is this ok [y/N]: y Downloading Packages: (1/2): libcgroup-0.42.2-3.oe2203sp1.x86_64.rpm 396 kB/s | 96 kB 00:00 (2/2): docker-engine-18.09.0-316.oe2203sp1.x86_64.rpm 10 MB/s | 38 MB 00:03 -------------------------------------------------------------------------------- Total 10 MB/s | 39 MB 00:03 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Running scriptlet: libcgroup-0.42.2-3.oe2203sp1.x86_64 1/2 Installing : libcgroup-0.42.2-3.oe2203sp1.x86_64 1/2 Running scriptlet: libcgroup-0.42.2-3.oe2203sp1.x86_64 1/2 Installing : docker-engine-2:18.09.0-316.oe2203sp1.x86_64 2/2 Running scriptlet: docker-engine-2:18.09.0-316.oe2203sp1.x86_64 2/2 Created symlink /etc/systemd/system/multi-user.target.wants/docker.service → /usr/lib/systemd/system/docker.service. Verifying : docker-engine-2:18.09.0-316.oe2203sp1.x86_64 1/2 Verifying : libcgroup-0.42.2-3.oe2203sp1.x86_64 2/2 Installed: docker-engine-2:18.09.0-316.oe2203sp1.x86_64 libcgroup-0.42.2-3.oe2203sp1.x86_64 Complete! 设置docker开机启动并启动 systemctl enable --now docker 查看docker版本 docker version Client: Version: 18.09.0 EulerVersion: 18.09.0.316 API version: 1.39 Go version: go1.17.3 Git commit: 9b9af2f Built: Tue Dec 27 14:25:30 2022 OS/Arch: linux/amd64 Experimental: false Server: Engine: Version: 18.09.0 EulerVersion: 18.09.0.316 API version: 1.39 (minimum version 1.12) Go version: go1.17.3 Git commit: 9b9af2f Built: Tue Dec 27 14:24:56 2022 OS/Arch: linux/amd64 Experimental: false 四、K8S软件安装 安装k8s依赖,连接跟踪 dnf install conntrack k8s master节点安装 dnf install -y kubernetes-kubeadm kubernetes-kubelet kubernetes-master k8s worker节点安装 dnf install -y kubernetes-kubeadm kubernetes-kubelet kubernetes-node systemctl enable kubelet 五、K8S集群初始化master kubeadm init --apiserver-advertise-address=192.168.10.1 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.20.2 --service-cidr=10.1.0.0/16 --pod-network-cidr=10.244.0.0/16 输出: [init] Using Kubernetes version: v1.20.2 [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [WARNING FileExisting-socat]: socat not found in system path [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [k8s-master01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.1.0.1 192.168.10.1] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.10.1 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.10.1 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 6.502722 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.20" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node k8s-master01 as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)" [mark-control-plane] Marking the node k8s-master01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: jvx2bb.pfd31288qyqcfsn7 [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.10.1:6443 --token jvx2bb.pfd31288qyqcfsn7 \ --discovery-token-ca-cert-hash sha256:740fa71f6c5acf156195ce6989cb49b7a64fd061b8bf56e4b1b684cbedafbd40 [root@k8s-master01 ~]# mkdir -p $HOME/.kube [root@k8s-master01 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@k8s-master01 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config 六、K8S集群工作节点加入 [root@k8s-node01 ~]kubeadm join 192.168.10.1:6443 --token jvx2bb.pfd31288qyqcfsn7 \ --discovery-token-ca-cert-hash sha256:740fa71f6c5acf156195ce6989cb49b7a64fd061b8bf56e4b1b684cbedafbd40 # [root@k8s-node02 ~]kubeadm join 192.168.10.1:6443 --token jvx2bb.pfd31288qyqcfsn7 \ --discovery-token-ca-cert-hash sha256:740fa71f6c5acf156195ce6989cb49b7a64fd061b8bf56e4b1b684cbedafbd40 [root@k8s-master01 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master01 NotReady control-plane,master 3m59s v1.20.2 k8s-node01 NotReady <none> 18s v1.20.2 k8s-node02 NotReady <none> 10s v1.20.2 七、K8S集群网络插件使用 [root@k8s-master01 ~]# wget https://docs.projectcalico.org/v3.19/manifests/calico.yaml 由于网络问题,我这边使用离线方式安装插件calico 1. 去github上面下载自己所需的calico离线包,项目地址: https://github.com/projectcalico/calico 2. 假设要安装最新版本v3.28.0,首先可以下载这个版本的calico.yaml,具体命令是 curl -O -L https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/calico.yaml 3. 下载完成之后可以通过calico.yaml查看需要安装哪些离线包,命令是: cat calico.yaml | grep image image: docker.io/calico/cni:v3.28.0 imagePullPolicy: IfNotPresent image: docker.io/calico/cni:v3.28.0 imagePullPolicy: IfNotPresent image: docker.io/calico/node:v3.28.0 imagePullPolicy: IfNotPresent image: docker.io/calico/node:v3.28.0 imagePullPolicy: IfNotPresent image: docker.io/calico/kube-controllers:v3.28.0 imagePullPolicy: IfNotPresent 4. 通过上述命令,查看到需要安装calico-cni.tar, calico-kube-controllers.tar 和 calico-node.tar三个包,然后需要将这三个包导入到k8s的命名空间中 使用导入命令将这三个包导入到k8s的命名空间中: docker load -i calico-cni.tar docker load -i calico-node.tar docker load -i calico-kube-controllers.tar 5. 导入之后就可以apply calico.yaml 文件了 6. 导入之后查看calico的pod,发现calico和coredns已经起来了 kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-8d76c5f9b-brv86 1/1 Running 0 22h calico-node-hxks2 1/1 Running 0 22h coredns-66f779496c-9hqsx 1/1 Running 0 23h coredns-66f779496c-rcc74 1/1 Running 0 23h etcd-kevin-pc 1/1 Running 4 (28m ago) 23h kube-apiserver-kevin-pc 1/1 Running 4 (28m ago) 23h kube-controller-manager-kevin-pc 1/1 Running 4 (28m ago) 23h kube-proxy-gglh4 1/1 Running 1 (28m ago) 23h kube-scheduler-kevin-pc 1/1 Running 4 (28m ago) 23h -
 置顶 【Windows Server】由于没有远程桌面授权服务器可以提供许可 由于没有远程桌面授权服务器可以提供许可证,远程会话连接已断开。请跟服务器管理员联系。原因是服务器安装了远程桌面服务RemoteApp,这个是需要授权的。但是微软官方给予了120天免授权使用,超过120天还没有可用授权就会出现远程会话被中断,可修改注册表来延长使用期限,此方法win2008和win2012适用 1、 首先进入安装了远程桌面服务RemoteApp的服务器,我这里是win2012 2、 按 win+R 键 打开运行,输入regedit 然后按 确定 3、 然后就打开了注册表编辑器 4、 然后进入 HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Control \ Terminal Server \ RCM \ GracePeriod ,选中 GracePeriod 然后右键 点击 权限 选择Administrators , 把完全控制勾上,点击确定后提示:无法保存对GracePeriod权限所作的更改。 5、administrator权限赋予 回到GracePeriod,右键权限,点击高级 点击更改所有者 注意:这里选择的是Administrators,看上图中的图标。 更改所有者后在审核里进行添加 选择Administrators为主体后,在此处添加完全控制权限 6、、 选择Administrators , 然后把 完全控制 勾上 , 再按确定 7、、 选中注册表中的 REG_BINARY,然后右键 删除 8、、 选择 是 9、然后关掉注册表编辑器,重启服务器 10、重启服务器后就不会被中断了,此方法可以继续使用120天,等到120天到了再按此方法进行操作就可以再继续使用了
置顶 【Windows Server】由于没有远程桌面授权服务器可以提供许可 由于没有远程桌面授权服务器可以提供许可证,远程会话连接已断开。请跟服务器管理员联系。原因是服务器安装了远程桌面服务RemoteApp,这个是需要授权的。但是微软官方给予了120天免授权使用,超过120天还没有可用授权就会出现远程会话被中断,可修改注册表来延长使用期限,此方法win2008和win2012适用 1、 首先进入安装了远程桌面服务RemoteApp的服务器,我这里是win2012 2、 按 win+R 键 打开运行,输入regedit 然后按 确定 3、 然后就打开了注册表编辑器 4、 然后进入 HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Control \ Terminal Server \ RCM \ GracePeriod ,选中 GracePeriod 然后右键 点击 权限 选择Administrators , 把完全控制勾上,点击确定后提示:无法保存对GracePeriod权限所作的更改。 5、administrator权限赋予 回到GracePeriod,右键权限,点击高级 点击更改所有者 注意:这里选择的是Administrators,看上图中的图标。 更改所有者后在审核里进行添加 选择Administrators为主体后,在此处添加完全控制权限 6、、 选择Administrators , 然后把 完全控制 勾上 , 再按确定 7、、 选中注册表中的 REG_BINARY,然后右键 删除 8、、 选择 是 9、然后关掉注册表编辑器,重启服务器 10、重启服务器后就不会被中断了,此方法可以继续使用120天,等到120天到了再按此方法进行操作就可以再继续使用了 -
 H3C 无线设备配置 RADIUS 认证详细步骤 本文将详细介绍如何在 H3C 无线控制器(AC)和接入点(AP)上配置 RADIUS 认证,实现基于 Windows Server NPS 的无线用户认证。 一、基础网络环境准备 确保以下网络条件已满足: H3C 无线控制器(AC)已正确配置并管理 AP AC 能与 RADIUS 服务器(Windows Server)正常通信 已在 Windows Server 上搭建好 NPS 服务并配置了 RADIUS 客户端(AC 的 IP 地址) 二、H3C AC 上配置 RADIUS 方案 登录 AC 的命令行界面(可通过 Console 口或 Telnet/SSH) 创建并配置 RADIUS 方案: # 进入系统视图 system-view # 创建RADIUS方案,名称为radius-wlan(可自定义) radius scheme radius-wlan # 配置主认证服务器IP和共享密钥(与NPS中配置一致) primary authentication 192.168.1.100 key simple radius@123 # 配置主计费服务器IP和共享密钥(与认证服务器相同) primary accounting 192.168.1.100 key simple radius@123 # 配置RADIUS服务器超时时间(可选,默认5秒) timer response-timeout 8 # 配置用户名格式(根据实际情况选择) # 不携带域名 user-name-format without-domain # 或携带域名 # user-name-format with-domain # 退出RADIUS方案视图 quit 三、配置认证域 创建并配置 ISP 域: # 创建域,名称为wlan-domain(可自定义) domain wlan-domain # 配置802.1X认证使用radius-wlan方案 authentication 802.1x radius-scheme radius-wlan # 配置802.1X授权使用radius-wlan方案 authorization 802.1x radius-scheme radius-wlan # 配置802.1X计费使用radius-wlan方案 accounting 802.1x radius-scheme radius-wlan # 设置域状态为激活 state active # 退出域视图 quit # 设置默认域(可选,用户认证时可不输入域名) domain default enable wlan-domain 四、配置无线服务模板 创建并配置无线服务模板: # 创建无线服务模板,名称为wlan-enterprise,类型为802.1X认证 wlan service-template wlan-enterprise crypto # 设置SSID名称(用户连接时将看到的无线网络名称) ssid H3C-Enterprise # 配置认证方式为WPA2-Enterprise security-ieee8021x enable wpa authentication-method psk wpa version wpa2 wpa cipher-suite ccmp # 配置802.1X认证参数 dot1x authentication-method eap # 绑定认证域 service-template domain wlan-domain # 启用服务模板 service-template enable 五、将服务模板绑定到 AP 射频 绑定服务模板到指定 AP 的射频: # 进入AP视图(假设AP名称为ap1) wlan ap ap1 # 进入射频1(通常为2.4GHz) radio 1 # 绑定无线服务模板 service-template wlan-enterprise # 启用射频 radio enable # 退出射频视图 quit # 进入射频2(通常为5GHz) radio 2 # 绑定无线服务模板 service-template wlan-enterprise # 启用射频 radio enable # 退出AP视图 quit 六、配置 AC 全局 802.1X 参数 # 启用全局802.1X功能 dot1x enable # 配置802.1X认证超时时间(可选) dot1x timer authenticator-timeout 30 # 配置802.1X最大认证请求次数(可选) dot1x timer retransmit 3 七、保存配置 # 保存当前配置 save 八、验证配置 查看 RADIUS 方案配置: display radius scheme radius-wlan 查看域配置: display domain wlan-domain 查看无线服务模板配置: display wlan service-template wlan-enterprise 查看 AP 配置: display wlan ap ap1 verbose 查看在线用户信息: display dot1x user 完成以上配置后,无线用户可以搜索到配置的 SSID(如 H3C-Enterprise),连接时将被引导输入用户名和密码,这些凭据将通过 AC 发送到 RADIUS 服务器进行认证。 如果用户认证失败,可以通过查看 NPS 服务器的安全事件日志(事件 ID 6272 表示失败)和 AC 上的 debug 信息进行故障排查。
H3C 无线设备配置 RADIUS 认证详细步骤 本文将详细介绍如何在 H3C 无线控制器(AC)和接入点(AP)上配置 RADIUS 认证,实现基于 Windows Server NPS 的无线用户认证。 一、基础网络环境准备 确保以下网络条件已满足: H3C 无线控制器(AC)已正确配置并管理 AP AC 能与 RADIUS 服务器(Windows Server)正常通信 已在 Windows Server 上搭建好 NPS 服务并配置了 RADIUS 客户端(AC 的 IP 地址) 二、H3C AC 上配置 RADIUS 方案 登录 AC 的命令行界面(可通过 Console 口或 Telnet/SSH) 创建并配置 RADIUS 方案: # 进入系统视图 system-view # 创建RADIUS方案,名称为radius-wlan(可自定义) radius scheme radius-wlan # 配置主认证服务器IP和共享密钥(与NPS中配置一致) primary authentication 192.168.1.100 key simple radius@123 # 配置主计费服务器IP和共享密钥(与认证服务器相同) primary accounting 192.168.1.100 key simple radius@123 # 配置RADIUS服务器超时时间(可选,默认5秒) timer response-timeout 8 # 配置用户名格式(根据实际情况选择) # 不携带域名 user-name-format without-domain # 或携带域名 # user-name-format with-domain # 退出RADIUS方案视图 quit 三、配置认证域 创建并配置 ISP 域: # 创建域,名称为wlan-domain(可自定义) domain wlan-domain # 配置802.1X认证使用radius-wlan方案 authentication 802.1x radius-scheme radius-wlan # 配置802.1X授权使用radius-wlan方案 authorization 802.1x radius-scheme radius-wlan # 配置802.1X计费使用radius-wlan方案 accounting 802.1x radius-scheme radius-wlan # 设置域状态为激活 state active # 退出域视图 quit # 设置默认域(可选,用户认证时可不输入域名) domain default enable wlan-domain 四、配置无线服务模板 创建并配置无线服务模板: # 创建无线服务模板,名称为wlan-enterprise,类型为802.1X认证 wlan service-template wlan-enterprise crypto # 设置SSID名称(用户连接时将看到的无线网络名称) ssid H3C-Enterprise # 配置认证方式为WPA2-Enterprise security-ieee8021x enable wpa authentication-method psk wpa version wpa2 wpa cipher-suite ccmp # 配置802.1X认证参数 dot1x authentication-method eap # 绑定认证域 service-template domain wlan-domain # 启用服务模板 service-template enable 五、将服务模板绑定到 AP 射频 绑定服务模板到指定 AP 的射频: # 进入AP视图(假设AP名称为ap1) wlan ap ap1 # 进入射频1(通常为2.4GHz) radio 1 # 绑定无线服务模板 service-template wlan-enterprise # 启用射频 radio enable # 退出射频视图 quit # 进入射频2(通常为5GHz) radio 2 # 绑定无线服务模板 service-template wlan-enterprise # 启用射频 radio enable # 退出AP视图 quit 六、配置 AC 全局 802.1X 参数 # 启用全局802.1X功能 dot1x enable # 配置802.1X认证超时时间(可选) dot1x timer authenticator-timeout 30 # 配置802.1X最大认证请求次数(可选) dot1x timer retransmit 3 七、保存配置 # 保存当前配置 save 八、验证配置 查看 RADIUS 方案配置: display radius scheme radius-wlan 查看域配置: display domain wlan-domain 查看无线服务模板配置: display wlan service-template wlan-enterprise 查看 AP 配置: display wlan ap ap1 verbose 查看在线用户信息: display dot1x user 完成以上配置后,无线用户可以搜索到配置的 SSID(如 H3C-Enterprise),连接时将被引导输入用户名和密码,这些凭据将通过 AC 发送到 RADIUS 服务器进行认证。 如果用户认证失败,可以通过查看 NPS 服务器的安全事件日志(事件 ID 6272 表示失败)和 AC 上的 debug 信息进行故障排查。 -
 网安小白自救指南:教你从“裸奔”到“武装到牙齿” 网络安全,你真的重视了吗? 在数字化飞速发展的当下,网络已然渗透进我们生活的每个角落。从日常购物、社交互动,到工作办公、金融交易,几乎都离不开网络。但你是否想过,在享受网络带来的便捷时,背后隐藏着怎样的风险? 先来看一个真实案例。2020 年,某知名连锁酒店遭遇严重数据泄露事件。黑客非法获取了数百万客户的个人信息,包括姓名、身份证号、联系方式、入住记录等。这不仅让客户的隐私毫无保障,酒店也因此陷入信任危机,大量客户流失,经济损失高达数千万元,品牌声誉更是一落千丈。 再把目光投向企业领域。2021 年,一家国际知名的软件公司被黑客攻击,核心代码和商业机密被盗取。这一事件导致公司股价暴跌,市值蒸发数十亿美元。公司后续为了修复漏洞、加强安全防护,投入了巨额资金,还面临着众多客户的索赔和法律诉讼。 这些并非个例,网络安全问题每天都在世界各地上演。据统计,全球每年因网络安全事件造成的经济损失高达数千亿美元。从个人隐私泄露,到企业商业机密被盗,再到关键基础设施受到攻击,网络安全风险无处不在,稍有不慎,就可能遭受沉重打击。所以,网络安全绝不是小事,而是关乎个人、企业乃至国家利益的大事,需要我们每个人高度重视 。 网络安全常见威胁大揭秘 在了解网络安全的重要性后,让我们来深入剖析常见的网络安全威胁,知己知彼,才能更好地防范。 恶意软件:隐藏在暗处的 “黑手” 恶意软件,也被称为 “流氓软件”,是指那些在未明确提示用户或未经用户许可的情况下,在用户计算机或其他终端上安装运行,侵害用户合法权益的软件 。常见的恶意软件包括病毒、木马、蠕虫、逻辑炸弹、后门、勒索软件等。它的传播途径广泛,可能通过下载文件、交换 CD / DVD、USB 设备的插拔、从服务器复制文件,以及打开受感染的电子邮件附件等方式感染设备。一旦设备被感染,恶意软件可能会导致数据丢失、文件损坏、系统运行缓慢,甚至完全瘫痪。比如臭名昭著的 “想哭” 勒索软件,在 2017 年全球爆发,感染了大量计算机,加密用户文件并索要赎金,给众多企业和个人带来巨大损失 。 网络钓鱼:狡猾的 “诈骗犯” 网络钓鱼是一种极具欺骗性的网络攻击手段。攻击者通过伪装成可信的机构、个人或网站,利用欺诈性的电子邮件、短信、即时通讯消息、网页等,诱使用户泄露敏感信息,如用户名、密码、信用卡号等,或在用户设备上安装恶意软件 。常见形式有电子邮件钓鱼,攻击者伪装官方邮箱,以账户异常等理由诱使点击虚假链接;短信钓鱼,常以中奖、快递问题等虚假信息诱导访问恶意网站;社交媒体钓鱼,通过假冒熟人或知名账号,诱骗用户提供信息;网页钓鱼,创建与正规网站高度相似的虚假页面,骗取用户输入敏感内容。据统计,每年因网络钓鱼导致的经济损失高达数十亿美元 。 拒绝服务攻击:让系统 “窒息” 的攻击 拒绝服务攻击(DoS)和分布式拒绝服务攻击(DDoS),是通过使机器或整个计算机系统过载来使其瘫痪的攻击方式 。DoS 攻击通常由一台计算机向目标服务器发送大量请求,耗尽服务器资源,导致合法用户无法访问服务。而 DDoS 攻击则更为强大,它利用僵尸网络,即一个由已感染恶意软件的连接互联网设备组成的网络,从多个来源同时向目标发送海量请求,让目标服务器不堪重负。DDoS 攻击常常瞄准在线零售商、互联网服务提供商、云服务提供商、金融机构等,一旦遭受攻击,可能导致服务中断、收入损失和声誉受损。例如,某知名游戏公司曾遭受 DDoS 攻击,导致游戏服务器瘫痪数小时,大量玩家无法正常游戏,公司不仅损失了大量收入,还引发了玩家的不满和信任危机 。 社交工程:利用人性弱点的攻击 社交工程融合了大量尝试利用人为错误或人的行为来获取信息或服务的访问权限的活动 。常见的社交工程攻击方法包括钓鱼、鱼叉式钓鱼、商业邮件入侵、欺诈、冒充和假冒等。攻击者往往通过研究目标的个人信息、兴趣爱好、工作生活习惯等,精心设计骗局,让目标在不知不觉中上当受骗。比如攻击者可能会冒充公司高管,向员工发送邮件要求转账,利用员工对上级的信任实施诈骗。 中间人攻击:窃取通信秘密的 “窃听者” 中间人攻击是指攻击者拦截通信双方的通信数据,并对数据进行窃取、篡改或伪造 。在用户进行网络购物、网上银行交易等过程中,如果网络环境不安全,就有可能遭受中间人攻击。攻击者可以获取用户的账号密码、交易信息等敏感数据,给用户带来严重的经济损失。例如,在公共 Wi-Fi 环境下,攻击者可能会搭建一个与正规 Wi-Fi 热点名称相同的虚假热点,当用户连接该热点并进行网络操作时,攻击者就可以轻松获取用户的通信数据 。 漏洞利用:趁虚而入的攻击 软件、操作系统或网络协议中不可避免地存在一些漏洞,攻击者一旦发现这些漏洞,就可能利用它们来获取未授权访问、执行恶意代码或破坏系统 。这些漏洞可能是由于编程错误、设计缺陷或安全措施不完善等原因造成的。比如 2014 年发现的 OpenSSL 心脏滴血漏洞,该漏洞允许攻击者从内存中读取敏感信息,影响了大量使用 OpenSSL 的网站和服务,导致无数用户的信息面临泄露风险 。 个人网络安全防护技巧大放送 了解了网络安全的常见威胁后,大家肯定迫不及待想知道如何保护自己。别着急,下面就为大家分享一些实用的个人网络安全防护技巧,助你在网络世界中安全畅游 。 (一)密码管理 密码就像是我们网络世界的 “钥匙”,管理好密码至关重要。首先,要使用强密码,长度至少 8 位,包含大小写字母、数字和特殊字符,比如 “Abc@123456” ,避免使用生日、电话号码、简单数字组合(如 123456、password)等容易被猜到的密码。其次,养成定期更换密码的习惯,建议每 3 - 6 个月更换一次,降低密码被破解的风险。另外,不同的网站和应用使用不同的密码,防止一个密码泄露导致多个账户受影响。 如果你觉得记忆不同的复杂密码很困难,不妨使用密码管理器,如 LastPass、1Password、KeePass 等。这些工具可以帮你生成高强度密码,并安全地存储和管理所有密码,只需记住一个主密码就能访问其他所有密码 。以下是使用 Python 生成随机密码的代码示例,利用random和string模块,轻松生成符合要求的强密码: import random import string def generate_password(length=12): # 定义可用字符 characters = string.ascii_letters + string.digits + string.punctuation # 随机选择字符组成密码 password = ''.join(random.choice(characters) for _ in range(length)) return password # 生成一个默认长度为12的随机密码 if __name__ == "__main__": password = generate_password() print("生成的随机密码是:", password) 运行这段代码,就能得到一个随机生成的强密码,如 “&dL5#zKb@r32”,大大提高账户安全性 。 (二)防范钓鱼攻击 网络钓鱼无孔不入,我们要时刻保持警惕。在点击链接或下载附件前,仔细检查网站 URL,确认是否与官方网站一致,注意拼写错误、额外的字符或不常见的域名。比如,银行官网是 “abcbank.com”,若收到的邮件链接是 “abc-bank.com” 或 “abcbank123.com”,就很可能是钓鱼链接 。对于邮件,要注意发件人地址,官方邮件通常来自官方域名,如 “service@company.com”,若发件人地址可疑,如 “randomuser123@gmail.com”,就要格外小心 。使用安全浏览器,如 Chrome、Firefox、Edge 等,它们具备安全浏览功能,能检测并阻止钓鱼网站 。还可以安装安全插件,如 uBlock Origin、NoScript 等,进一步增强浏览器的安全性 。定期更新操作系统和浏览器,这些更新通常包含安全补丁,能修复已知的安全漏洞 。开启双重验证功能,在登录时除了密码,还需要通过手机短信验证码、指纹识别、面部识别等方式进行二次验证,增加账户安全性 。 以下是一个使用 Python 检测钓鱼邮件的简单代码示例,通过检查邮件文本中是否包含常见的钓鱼关键词来判断: import re def detect_phishing_email(email_text): phishing_keywords = ['click', 'verify', 'update', 'login', 'secure'] for keyword in phishing_keywords: if re.search(keyword, email_text, re.IGNORECASE): print(f"检测到可能的网络钓鱼:{keyword}") return True return False # 检测邮件文本 detect_phishing_email("Please click on the link to verify your account.") 当检测到邮件中包含 “click”“verify” 等关键词时,就会提示可能是钓鱼邮件 。不过,这只是一个简单示例,实际应用中还需要更复杂的检测方法 。 (三)安全使用社交媒体 社交媒体已成为我们生活的一部分,但也存在隐私泄露风险。在注册和使用社交媒体时,要注意隐私设置,将个人信息的可见性设置为仅自己或好友可见,避免公开敏感信息,如家庭住址、电话号码、身份证号等 。谨慎添加好友,不要随意接受陌生人的好友请求,避免个人信息被过度曝光 。在发布内容前,仔细审查,避免发布包含个人隐私或敏感信息的内容,如旅行计划、工作单位等 。同样,也要使用强密码,并定期更换,保护社交媒体账户安全 。定期清理旧内容,删除不必要的照片、状态和评论,减少个人信息的泄露风险 。 实用网络安全防护工具及使用教程 在了解了个人网络安全防护技巧后,接下来为大家介绍一些实用的网络安全防护工具及详细使用教程,让你的网络安全防护更上一层楼 。 (一)个人防火墙 个人防火墙是一种软件工具,用于监控和控制进出计算机的数据流,就像为你的电脑筑起了一道坚固的防线 。它可以帮助阻止未经授权的访问,防止恶意软件攻击,保护个人隐私 。个人防火墙的作用主要体现在以下几个方面: 网络监控:实时监控网络流量,让你随时了解网络活动情况,及时发现潜在的威胁 。 阻止未经授权的访问:有效阻止外部未经授权的设备或程序访问你的计算机,防止黑客入侵和数据窃取 。 保护隐私:防止未经授权的软件访问网络,避免个人隐私信息泄露 。 防止恶意软件传播:阻止恶意软件通过网络传播到你的计算机,降低感染风险 。 数据包过滤:仔细过滤进出网络的数据包,确保只有合法的数据包通过,提高网络安全性 。 下面是使用 Python 的 scapy 库检测网络流量的代码示例,通过这个示例,你可以更直观地了解如何利用工具进行网络监控: from scapy.all import sniff, TCP def packet_callback(packet): if packet[TCP].payload: mail_content = str(packet[TCP].payload) if 'user' in mail_content or 'pass' in mail_content: print(f'[+] Found possible username and password {packet[TCP].payload}') print(f'[+] From: {packet[IP].src} -> {packet[IP].dst}') def network_monitor(): sniff(filter='tcp port 25 or tcp port 110 or tcp port 143 or tcp port 993 or tcp port 995', prn=packet_callback, store=0) network_monitor() 这段代码使用 scapy 库的sniff函数捕获网络数据包,通过filter 参数指定只捕获与邮件相关的 TCP 端口流量,当捕获到的数据包中包含 “user” 或 “pass” 关键词时,就会打印出可能的用户名和密码以及数据包的源 IP 和目标 IP,帮助你及时发现潜在的安全风险 。 (二)反病毒软件 反病毒软件是一种可以检测、清除计算机病毒和其他恶意软件的软件,是保障计算机安全的重要防线 。使用反病毒软件的好处众多: 病毒检测:运用先进的检测技术,精准检测计算机上的病毒和其他恶意软件 。 病毒清除:一旦检测到病毒,立即采取措施进行清除,确保系统安全 。 实时保护:实时监控计算机活动,第一时间发现并阻止病毒入侵 。 防火墙功能:部分反病毒软件还提供额外的防火墙功能,进一步增强系统安全性 。 定期更新:定期更新病毒数据库,以应对不断变化的病毒威胁 。 常见的反病毒软件有 360 安全卫士、腾讯电脑管家、金山毒霸、卡巴斯基、诺顿等 。 写到最后我们来总结 网络安全是一场没有硝烟的战争,它关乎我们每个人的切身利益,是我们在数字时代必须坚守的阵地。从常见的恶意软件、网络钓鱼,到复杂的拒绝服务攻击、社交工程和中间人攻击,网络威胁无处不在,且手段日益复杂。但只要我们掌握正确的防护技巧,合理运用有效的防护工具,就能在很大程度上降低风险,保护自己的网络安全 。 在日常生活中,希望大家都能将这些网络安全知识牢记于心,付诸于行。从设置强密码、防范钓鱼攻击,到安全使用社交媒体,每一个小小的举动,都是在为自己的网络安全添砖加瓦 。同时,也希望大家能将这些知识分享给身边的人,让更多的人了解网络安全的重要性,共同提高网络安全意识 。 让我们携手共进,积极行动起来,从自身做起,从现在做起,用知识武装自己,用行动捍卫网络安全,共同营造一个安全、健康、有序的网络环境 。在这个充满挑战的网络时代,让我们成为网络安全的守护者,享受安全、便捷的数字化生活 。
网安小白自救指南:教你从“裸奔”到“武装到牙齿” 网络安全,你真的重视了吗? 在数字化飞速发展的当下,网络已然渗透进我们生活的每个角落。从日常购物、社交互动,到工作办公、金融交易,几乎都离不开网络。但你是否想过,在享受网络带来的便捷时,背后隐藏着怎样的风险? 先来看一个真实案例。2020 年,某知名连锁酒店遭遇严重数据泄露事件。黑客非法获取了数百万客户的个人信息,包括姓名、身份证号、联系方式、入住记录等。这不仅让客户的隐私毫无保障,酒店也因此陷入信任危机,大量客户流失,经济损失高达数千万元,品牌声誉更是一落千丈。 再把目光投向企业领域。2021 年,一家国际知名的软件公司被黑客攻击,核心代码和商业机密被盗取。这一事件导致公司股价暴跌,市值蒸发数十亿美元。公司后续为了修复漏洞、加强安全防护,投入了巨额资金,还面临着众多客户的索赔和法律诉讼。 这些并非个例,网络安全问题每天都在世界各地上演。据统计,全球每年因网络安全事件造成的经济损失高达数千亿美元。从个人隐私泄露,到企业商业机密被盗,再到关键基础设施受到攻击,网络安全风险无处不在,稍有不慎,就可能遭受沉重打击。所以,网络安全绝不是小事,而是关乎个人、企业乃至国家利益的大事,需要我们每个人高度重视 。 网络安全常见威胁大揭秘 在了解网络安全的重要性后,让我们来深入剖析常见的网络安全威胁,知己知彼,才能更好地防范。 恶意软件:隐藏在暗处的 “黑手” 恶意软件,也被称为 “流氓软件”,是指那些在未明确提示用户或未经用户许可的情况下,在用户计算机或其他终端上安装运行,侵害用户合法权益的软件 。常见的恶意软件包括病毒、木马、蠕虫、逻辑炸弹、后门、勒索软件等。它的传播途径广泛,可能通过下载文件、交换 CD / DVD、USB 设备的插拔、从服务器复制文件,以及打开受感染的电子邮件附件等方式感染设备。一旦设备被感染,恶意软件可能会导致数据丢失、文件损坏、系统运行缓慢,甚至完全瘫痪。比如臭名昭著的 “想哭” 勒索软件,在 2017 年全球爆发,感染了大量计算机,加密用户文件并索要赎金,给众多企业和个人带来巨大损失 。 网络钓鱼:狡猾的 “诈骗犯” 网络钓鱼是一种极具欺骗性的网络攻击手段。攻击者通过伪装成可信的机构、个人或网站,利用欺诈性的电子邮件、短信、即时通讯消息、网页等,诱使用户泄露敏感信息,如用户名、密码、信用卡号等,或在用户设备上安装恶意软件 。常见形式有电子邮件钓鱼,攻击者伪装官方邮箱,以账户异常等理由诱使点击虚假链接;短信钓鱼,常以中奖、快递问题等虚假信息诱导访问恶意网站;社交媒体钓鱼,通过假冒熟人或知名账号,诱骗用户提供信息;网页钓鱼,创建与正规网站高度相似的虚假页面,骗取用户输入敏感内容。据统计,每年因网络钓鱼导致的经济损失高达数十亿美元 。 拒绝服务攻击:让系统 “窒息” 的攻击 拒绝服务攻击(DoS)和分布式拒绝服务攻击(DDoS),是通过使机器或整个计算机系统过载来使其瘫痪的攻击方式 。DoS 攻击通常由一台计算机向目标服务器发送大量请求,耗尽服务器资源,导致合法用户无法访问服务。而 DDoS 攻击则更为强大,它利用僵尸网络,即一个由已感染恶意软件的连接互联网设备组成的网络,从多个来源同时向目标发送海量请求,让目标服务器不堪重负。DDoS 攻击常常瞄准在线零售商、互联网服务提供商、云服务提供商、金融机构等,一旦遭受攻击,可能导致服务中断、收入损失和声誉受损。例如,某知名游戏公司曾遭受 DDoS 攻击,导致游戏服务器瘫痪数小时,大量玩家无法正常游戏,公司不仅损失了大量收入,还引发了玩家的不满和信任危机 。 社交工程:利用人性弱点的攻击 社交工程融合了大量尝试利用人为错误或人的行为来获取信息或服务的访问权限的活动 。常见的社交工程攻击方法包括钓鱼、鱼叉式钓鱼、商业邮件入侵、欺诈、冒充和假冒等。攻击者往往通过研究目标的个人信息、兴趣爱好、工作生活习惯等,精心设计骗局,让目标在不知不觉中上当受骗。比如攻击者可能会冒充公司高管,向员工发送邮件要求转账,利用员工对上级的信任实施诈骗。 中间人攻击:窃取通信秘密的 “窃听者” 中间人攻击是指攻击者拦截通信双方的通信数据,并对数据进行窃取、篡改或伪造 。在用户进行网络购物、网上银行交易等过程中,如果网络环境不安全,就有可能遭受中间人攻击。攻击者可以获取用户的账号密码、交易信息等敏感数据,给用户带来严重的经济损失。例如,在公共 Wi-Fi 环境下,攻击者可能会搭建一个与正规 Wi-Fi 热点名称相同的虚假热点,当用户连接该热点并进行网络操作时,攻击者就可以轻松获取用户的通信数据 。 漏洞利用:趁虚而入的攻击 软件、操作系统或网络协议中不可避免地存在一些漏洞,攻击者一旦发现这些漏洞,就可能利用它们来获取未授权访问、执行恶意代码或破坏系统 。这些漏洞可能是由于编程错误、设计缺陷或安全措施不完善等原因造成的。比如 2014 年发现的 OpenSSL 心脏滴血漏洞,该漏洞允许攻击者从内存中读取敏感信息,影响了大量使用 OpenSSL 的网站和服务,导致无数用户的信息面临泄露风险 。 个人网络安全防护技巧大放送 了解了网络安全的常见威胁后,大家肯定迫不及待想知道如何保护自己。别着急,下面就为大家分享一些实用的个人网络安全防护技巧,助你在网络世界中安全畅游 。 (一)密码管理 密码就像是我们网络世界的 “钥匙”,管理好密码至关重要。首先,要使用强密码,长度至少 8 位,包含大小写字母、数字和特殊字符,比如 “Abc@123456” ,避免使用生日、电话号码、简单数字组合(如 123456、password)等容易被猜到的密码。其次,养成定期更换密码的习惯,建议每 3 - 6 个月更换一次,降低密码被破解的风险。另外,不同的网站和应用使用不同的密码,防止一个密码泄露导致多个账户受影响。 如果你觉得记忆不同的复杂密码很困难,不妨使用密码管理器,如 LastPass、1Password、KeePass 等。这些工具可以帮你生成高强度密码,并安全地存储和管理所有密码,只需记住一个主密码就能访问其他所有密码 。以下是使用 Python 生成随机密码的代码示例,利用random和string模块,轻松生成符合要求的强密码: import random import string def generate_password(length=12): # 定义可用字符 characters = string.ascii_letters + string.digits + string.punctuation # 随机选择字符组成密码 password = ''.join(random.choice(characters) for _ in range(length)) return password # 生成一个默认长度为12的随机密码 if __name__ == "__main__": password = generate_password() print("生成的随机密码是:", password) 运行这段代码,就能得到一个随机生成的强密码,如 “&dL5#zKb@r32”,大大提高账户安全性 。 (二)防范钓鱼攻击 网络钓鱼无孔不入,我们要时刻保持警惕。在点击链接或下载附件前,仔细检查网站 URL,确认是否与官方网站一致,注意拼写错误、额外的字符或不常见的域名。比如,银行官网是 “abcbank.com”,若收到的邮件链接是 “abc-bank.com” 或 “abcbank123.com”,就很可能是钓鱼链接 。对于邮件,要注意发件人地址,官方邮件通常来自官方域名,如 “service@company.com”,若发件人地址可疑,如 “randomuser123@gmail.com”,就要格外小心 。使用安全浏览器,如 Chrome、Firefox、Edge 等,它们具备安全浏览功能,能检测并阻止钓鱼网站 。还可以安装安全插件,如 uBlock Origin、NoScript 等,进一步增强浏览器的安全性 。定期更新操作系统和浏览器,这些更新通常包含安全补丁,能修复已知的安全漏洞 。开启双重验证功能,在登录时除了密码,还需要通过手机短信验证码、指纹识别、面部识别等方式进行二次验证,增加账户安全性 。 以下是一个使用 Python 检测钓鱼邮件的简单代码示例,通过检查邮件文本中是否包含常见的钓鱼关键词来判断: import re def detect_phishing_email(email_text): phishing_keywords = ['click', 'verify', 'update', 'login', 'secure'] for keyword in phishing_keywords: if re.search(keyword, email_text, re.IGNORECASE): print(f"检测到可能的网络钓鱼:{keyword}") return True return False # 检测邮件文本 detect_phishing_email("Please click on the link to verify your account.") 当检测到邮件中包含 “click”“verify” 等关键词时,就会提示可能是钓鱼邮件 。不过,这只是一个简单示例,实际应用中还需要更复杂的检测方法 。 (三)安全使用社交媒体 社交媒体已成为我们生活的一部分,但也存在隐私泄露风险。在注册和使用社交媒体时,要注意隐私设置,将个人信息的可见性设置为仅自己或好友可见,避免公开敏感信息,如家庭住址、电话号码、身份证号等 。谨慎添加好友,不要随意接受陌生人的好友请求,避免个人信息被过度曝光 。在发布内容前,仔细审查,避免发布包含个人隐私或敏感信息的内容,如旅行计划、工作单位等 。同样,也要使用强密码,并定期更换,保护社交媒体账户安全 。定期清理旧内容,删除不必要的照片、状态和评论,减少个人信息的泄露风险 。 实用网络安全防护工具及使用教程 在了解了个人网络安全防护技巧后,接下来为大家介绍一些实用的网络安全防护工具及详细使用教程,让你的网络安全防护更上一层楼 。 (一)个人防火墙 个人防火墙是一种软件工具,用于监控和控制进出计算机的数据流,就像为你的电脑筑起了一道坚固的防线 。它可以帮助阻止未经授权的访问,防止恶意软件攻击,保护个人隐私 。个人防火墙的作用主要体现在以下几个方面: 网络监控:实时监控网络流量,让你随时了解网络活动情况,及时发现潜在的威胁 。 阻止未经授权的访问:有效阻止外部未经授权的设备或程序访问你的计算机,防止黑客入侵和数据窃取 。 保护隐私:防止未经授权的软件访问网络,避免个人隐私信息泄露 。 防止恶意软件传播:阻止恶意软件通过网络传播到你的计算机,降低感染风险 。 数据包过滤:仔细过滤进出网络的数据包,确保只有合法的数据包通过,提高网络安全性 。 下面是使用 Python 的 scapy 库检测网络流量的代码示例,通过这个示例,你可以更直观地了解如何利用工具进行网络监控: from scapy.all import sniff, TCP def packet_callback(packet): if packet[TCP].payload: mail_content = str(packet[TCP].payload) if 'user' in mail_content or 'pass' in mail_content: print(f'[+] Found possible username and password {packet[TCP].payload}') print(f'[+] From: {packet[IP].src} -> {packet[IP].dst}') def network_monitor(): sniff(filter='tcp port 25 or tcp port 110 or tcp port 143 or tcp port 993 or tcp port 995', prn=packet_callback, store=0) network_monitor() 这段代码使用 scapy 库的sniff函数捕获网络数据包,通过filter 参数指定只捕获与邮件相关的 TCP 端口流量,当捕获到的数据包中包含 “user” 或 “pass” 关键词时,就会打印出可能的用户名和密码以及数据包的源 IP 和目标 IP,帮助你及时发现潜在的安全风险 。 (二)反病毒软件 反病毒软件是一种可以检测、清除计算机病毒和其他恶意软件的软件,是保障计算机安全的重要防线 。使用反病毒软件的好处众多: 病毒检测:运用先进的检测技术,精准检测计算机上的病毒和其他恶意软件 。 病毒清除:一旦检测到病毒,立即采取措施进行清除,确保系统安全 。 实时保护:实时监控计算机活动,第一时间发现并阻止病毒入侵 。 防火墙功能:部分反病毒软件还提供额外的防火墙功能,进一步增强系统安全性 。 定期更新:定期更新病毒数据库,以应对不断变化的病毒威胁 。 常见的反病毒软件有 360 安全卫士、腾讯电脑管家、金山毒霸、卡巴斯基、诺顿等 。 写到最后我们来总结 网络安全是一场没有硝烟的战争,它关乎我们每个人的切身利益,是我们在数字时代必须坚守的阵地。从常见的恶意软件、网络钓鱼,到复杂的拒绝服务攻击、社交工程和中间人攻击,网络威胁无处不在,且手段日益复杂。但只要我们掌握正确的防护技巧,合理运用有效的防护工具,就能在很大程度上降低风险,保护自己的网络安全 。 在日常生活中,希望大家都能将这些网络安全知识牢记于心,付诸于行。从设置强密码、防范钓鱼攻击,到安全使用社交媒体,每一个小小的举动,都是在为自己的网络安全添砖加瓦 。同时,也希望大家能将这些知识分享给身边的人,让更多的人了解网络安全的重要性,共同提高网络安全意识 。 让我们携手共进,积极行动起来,从自身做起,从现在做起,用知识武装自己,用行动捍卫网络安全,共同营造一个安全、健康、有序的网络环境 。在这个充满挑战的网络时代,让我们成为网络安全的守护者,享受安全、便捷的数字化生活 。 -
 一代目录爆破神器!spray 让渗透测试效率翻倍 在渗透测试和网络安全评估中,目录爆破是信息收集阶段的关键环节。传统工具往往面临性能瓶颈、字典灵活性不足、结果过滤繁琐等问题,而今天要为大家介绍的 spray,堪称 “下一代目录爆破工具” 的典范 —— 它集高性能爆破、智能指纹识别、灵活字典生成于一体,彻底重构了目录爆破的工作流程,让自动化渗透更高效、更精准。 一、spray 是什么?不止是 “目录爆破工具” spray 并非单一功能的工具,而是一套全方位的目录爆破与信息收集解决方案。它的核心设计理念是 “将能自动化的工作交给工具,为复杂场景保留可控接口”,通过整合多款经典工具的核心能力,解决了渗透测试中常见的痛点: 整合 feroxbuster 的高性能爆破能力,突破并发与速度极限; 内置 指纹识别 模块,支持全量 gogo 指纹库,快速识别服务器、框架类型; 集成 httpx 的 HTTP 信息解析功能,自动提取响应头、状态码、页面标题等关键信息; 借鉴 dirmap 的字典生成逻辑,支持掩码、规则两种灵活生成方式; 额外新增断点续传、动态过滤、自定义输出等实用功能,覆盖从爆破到结果分析的全流程。 简单来说,有了 spray,你无需在多个工具间切换,一个命令就能完成 “目录爆破 + 指纹识别 + 信息提取” 的组合操作,极大减少重复工作。 二、为什么选 spray?这些核心优势太能打 相比 ffuf、feroxbuster 等传统工具,spray 的优势体现在 “性能、灵活性、智能化” 三个维度,尤其适合多目标、高复杂度的渗透场景: 性能碾压:比主流工具快 50% 以上 在本地极限性能测试中,spray 的并发处理能力远超 ffuf 与 feroxbuster,速度提升可达 50% 以上。无论是单目标深度爆破,还是多目标批量扫描,都能快速完成任务,避免因等待浪费时间。 字典生成:灵活应对不同场景 传统字典往往 “一刀切”,而 spray 支持两种自定义生成方式,让字典更贴合目标特点: 掩码生成 :通过 DSL 语法快速生成特定格式的路径,例如 -w "/admin/{?l#4}" 可生成 “admin 后接 4 位小写字母” 的路径(如 /admin/abcd、/admin/wxyz); 规则生成 :参考 hashcat 规则格式,通过规则文件批量调整字典(如大写转小写、添加后缀),例如 -r rule.txt -d wordlist.txt,让旧字典焕发新活力。 3. 智能过滤:告别 “无效结果轰炸” 目录爆破最头疼的问题之一,就是大量无效 404 页面或重复路径干扰判断。spray 通过 “动态智能过滤” 和 “自定义策略” 双重保障,精准筛选有效结果: 自动识别重复路径、服务器自定义 404 页面,直接标记 “skipped”(跳过); 支持自定义过滤规则,例如 --filter 'current.Body contains "登录"',只保留包含 “登录” 关键词的页面; 内置多角度被 Ban/WAF 判断逻辑,当请求频繁触发错误时,自动调整频率,避免被目标拦截。 4. 功能集成:一站式搞定信息收集 除了核心的目录爆破,spray 还内置多个实用插件,无需额外工具即可拓展能力: 指纹识别 :启用 --finger 参数,可主动探测常见指纹目录,同时支持 ehole、goby 等第三方指纹库,快速识别 Nginx、Apache、Tomcat 等服务器,以及 ThinkPHP、SpringBoot 等框架; 爬虫功能 :通过 --crawl 启用爬虫,深度抓取目标站点链接,结合 --crawl-depth 控制抓取层级(默认 3 层),避免遗漏隐藏路径; 备份文件扫描 :用 --bak 参数自动探测网站备份(如 .rar、.zip、.sql),--common 则扫描 robots.txt、crossdomain.xml 等通用文件; 信息提取 :通过 --extract 自定义提取内容,支持 IP、JS 链接、页面标题,甚至用正则表达式提取版本号(如 --extract version:(.*?))。 5. 断点续传:不怕中途中断 如果爆破任务因网络故障、工具崩溃中断,只需通过 --resume stat.json 加载上次的状态文件,即可从断点继续执行,无需重新开始,尤其适合长时间的多目标扫描。 三、上手实战:3 分钟学会核心用法 spray 的命令行设计遵循 *nix 风格,参数清晰易懂,无论是新手还是老手,都能快速上手。以下是几个高频场景的实战命令: 基础爆破:从字典读取路径 如果已有现成字典(如 dirb/common.txt),直接指定目标 URL 和字典文件即可: # 单字典爆破 ./spray -u http://example.com -d wordlist1.txt # 多字典组合爆破(支持同时加载多个字典) ./spray -u http://example.com -d wordlist1.txt -d wordlist2.txt 灵活爆破:掩码 / 规则生成字典 如果没有合适的字典,用掩码或规则生成更精准的路径: # 掩码生成:/test 后接 3 位数字(如 /test/123、/test/456) ./spray -u http://example.com -w "/test/{?d#3}" # 规则生成:用 rule.txt 规则处理 1.txt 字典 ./spray -u http://example.com -r rule.txt -d 1.txt 批量爆破:多目标同时扫描 如果需要扫描多个目标(如 URL 列表文件 url.txt),结合规则和字典批量执行: ./spray -l url.txt -r rule.txt -d wordlist.txt 高级功能:指纹 + 爬虫 + 备份扫描 想要一次性完成 “爆破 + 指纹 + 爬虫 + 备份扫描”,启用插件参数即可: # 启用指纹识别+爬虫+备份扫描,输出结果到 result.txt ./spray -u http://example.com -d wordlist.txt --finger --crawl --bak -f result.txt 结果优化:自定义输出与过滤 如果需要筛选特定结果(如只保留 200/301 状态码),或调整输出格式(如 JSON): # 只保留状态码为 200 或 301 的结果,以 JSON 格式输出 ./spray -u http://example.com -d wordlist.txt --match 'current.Status in [200,301]' -j 四、如何获取 spray? spray 是开源工具,支持 Windows、Linux、macOS 多平台,获取方式非常简单: 源码仓库 :直接访问 GitHub 仓库查看源码和文档 https://github.com/chainreactors/spray 直接下载 :前往 Release 页面下载最新版本的二进制文件 https://github.com/chainreactors/spray/releases/latest 快速入门 :如果是新手,建议先阅读官方 Wiki 的 “快速入门” 指南 https://chainreactors.github.io/wiki/spray/start/ 五、写在最后:工具是效率的前提,规范是安全的底线 spray 作为一款高性能的目录爆破工具,能极大提升渗透测试的效率,但请务必注意:仅在获得合法授权的前提下,对目标系统使用该工具。未经授权的目录爆破属于非法攻击行为,可能触犯《网络安全法》《刑法》等法律法规,承担相应法律责任。 如果你是渗透测试工程师、网络安全爱好者,不妨试试 spray—— 它不仅是一款工具,更是一套 “让渗透更高效” 的解决方案。相信用过之后,你会重新定义对 “目录爆破” 的认知! 最后,欢迎在评论区分享你的使用心得,或提出改进建议。关注本网站,后续还会带来更多优质工具解析和安全技术干货~
一代目录爆破神器!spray 让渗透测试效率翻倍 在渗透测试和网络安全评估中,目录爆破是信息收集阶段的关键环节。传统工具往往面临性能瓶颈、字典灵活性不足、结果过滤繁琐等问题,而今天要为大家介绍的 spray,堪称 “下一代目录爆破工具” 的典范 —— 它集高性能爆破、智能指纹识别、灵活字典生成于一体,彻底重构了目录爆破的工作流程,让自动化渗透更高效、更精准。 一、spray 是什么?不止是 “目录爆破工具” spray 并非单一功能的工具,而是一套全方位的目录爆破与信息收集解决方案。它的核心设计理念是 “将能自动化的工作交给工具,为复杂场景保留可控接口”,通过整合多款经典工具的核心能力,解决了渗透测试中常见的痛点: 整合 feroxbuster 的高性能爆破能力,突破并发与速度极限; 内置 指纹识别 模块,支持全量 gogo 指纹库,快速识别服务器、框架类型; 集成 httpx 的 HTTP 信息解析功能,自动提取响应头、状态码、页面标题等关键信息; 借鉴 dirmap 的字典生成逻辑,支持掩码、规则两种灵活生成方式; 额外新增断点续传、动态过滤、自定义输出等实用功能,覆盖从爆破到结果分析的全流程。 简单来说,有了 spray,你无需在多个工具间切换,一个命令就能完成 “目录爆破 + 指纹识别 + 信息提取” 的组合操作,极大减少重复工作。 二、为什么选 spray?这些核心优势太能打 相比 ffuf、feroxbuster 等传统工具,spray 的优势体现在 “性能、灵活性、智能化” 三个维度,尤其适合多目标、高复杂度的渗透场景: 性能碾压:比主流工具快 50% 以上 在本地极限性能测试中,spray 的并发处理能力远超 ffuf 与 feroxbuster,速度提升可达 50% 以上。无论是单目标深度爆破,还是多目标批量扫描,都能快速完成任务,避免因等待浪费时间。 字典生成:灵活应对不同场景 传统字典往往 “一刀切”,而 spray 支持两种自定义生成方式,让字典更贴合目标特点: 掩码生成 :通过 DSL 语法快速生成特定格式的路径,例如 -w "/admin/{?l#4}" 可生成 “admin 后接 4 位小写字母” 的路径(如 /admin/abcd、/admin/wxyz); 规则生成 :参考 hashcat 规则格式,通过规则文件批量调整字典(如大写转小写、添加后缀),例如 -r rule.txt -d wordlist.txt,让旧字典焕发新活力。 3. 智能过滤:告别 “无效结果轰炸” 目录爆破最头疼的问题之一,就是大量无效 404 页面或重复路径干扰判断。spray 通过 “动态智能过滤” 和 “自定义策略” 双重保障,精准筛选有效结果: 自动识别重复路径、服务器自定义 404 页面,直接标记 “skipped”(跳过); 支持自定义过滤规则,例如 --filter 'current.Body contains "登录"',只保留包含 “登录” 关键词的页面; 内置多角度被 Ban/WAF 判断逻辑,当请求频繁触发错误时,自动调整频率,避免被目标拦截。 4. 功能集成:一站式搞定信息收集 除了核心的目录爆破,spray 还内置多个实用插件,无需额外工具即可拓展能力: 指纹识别 :启用 --finger 参数,可主动探测常见指纹目录,同时支持 ehole、goby 等第三方指纹库,快速识别 Nginx、Apache、Tomcat 等服务器,以及 ThinkPHP、SpringBoot 等框架; 爬虫功能 :通过 --crawl 启用爬虫,深度抓取目标站点链接,结合 --crawl-depth 控制抓取层级(默认 3 层),避免遗漏隐藏路径; 备份文件扫描 :用 --bak 参数自动探测网站备份(如 .rar、.zip、.sql),--common 则扫描 robots.txt、crossdomain.xml 等通用文件; 信息提取 :通过 --extract 自定义提取内容,支持 IP、JS 链接、页面标题,甚至用正则表达式提取版本号(如 --extract version:(.*?))。 5. 断点续传:不怕中途中断 如果爆破任务因网络故障、工具崩溃中断,只需通过 --resume stat.json 加载上次的状态文件,即可从断点继续执行,无需重新开始,尤其适合长时间的多目标扫描。 三、上手实战:3 分钟学会核心用法 spray 的命令行设计遵循 *nix 风格,参数清晰易懂,无论是新手还是老手,都能快速上手。以下是几个高频场景的实战命令: 基础爆破:从字典读取路径 如果已有现成字典(如 dirb/common.txt),直接指定目标 URL 和字典文件即可: # 单字典爆破 ./spray -u http://example.com -d wordlist1.txt # 多字典组合爆破(支持同时加载多个字典) ./spray -u http://example.com -d wordlist1.txt -d wordlist2.txt 灵活爆破:掩码 / 规则生成字典 如果没有合适的字典,用掩码或规则生成更精准的路径: # 掩码生成:/test 后接 3 位数字(如 /test/123、/test/456) ./spray -u http://example.com -w "/test/{?d#3}" # 规则生成:用 rule.txt 规则处理 1.txt 字典 ./spray -u http://example.com -r rule.txt -d 1.txt 批量爆破:多目标同时扫描 如果需要扫描多个目标(如 URL 列表文件 url.txt),结合规则和字典批量执行: ./spray -l url.txt -r rule.txt -d wordlist.txt 高级功能:指纹 + 爬虫 + 备份扫描 想要一次性完成 “爆破 + 指纹 + 爬虫 + 备份扫描”,启用插件参数即可: # 启用指纹识别+爬虫+备份扫描,输出结果到 result.txt ./spray -u http://example.com -d wordlist.txt --finger --crawl --bak -f result.txt 结果优化:自定义输出与过滤 如果需要筛选特定结果(如只保留 200/301 状态码),或调整输出格式(如 JSON): # 只保留状态码为 200 或 301 的结果,以 JSON 格式输出 ./spray -u http://example.com -d wordlist.txt --match 'current.Status in [200,301]' -j 四、如何获取 spray? spray 是开源工具,支持 Windows、Linux、macOS 多平台,获取方式非常简单: 源码仓库 :直接访问 GitHub 仓库查看源码和文档 https://github.com/chainreactors/spray 直接下载 :前往 Release 页面下载最新版本的二进制文件 https://github.com/chainreactors/spray/releases/latest 快速入门 :如果是新手,建议先阅读官方 Wiki 的 “快速入门” 指南 https://chainreactors.github.io/wiki/spray/start/ 五、写在最后:工具是效率的前提,规范是安全的底线 spray 作为一款高性能的目录爆破工具,能极大提升渗透测试的效率,但请务必注意:仅在获得合法授权的前提下,对目标系统使用该工具。未经授权的目录爆破属于非法攻击行为,可能触犯《网络安全法》《刑法》等法律法规,承担相应法律责任。 如果你是渗透测试工程师、网络安全爱好者,不妨试试 spray—— 它不仅是一款工具,更是一套 “让渗透更高效” 的解决方案。相信用过之后,你会重新定义对 “目录爆破” 的认知! 最后,欢迎在评论区分享你的使用心得,或提出改进建议。关注本网站,后续还会带来更多优质工具解析和安全技术干货~ -
 SQL Server 数据库自动备份完整配置指南 SQL Server 数据库自动备份完整配置指南 在数据库管理工作中,数据安全是核心环节,而定期自动备份则是保障数据可恢复性的关键手段。对于 SQL Server 数据库而言,通过配置管理器与维护计划实现自动化备份,能有效避免人工操作遗漏,降低数据丢失风险。本文将以清晰的步骤拆解,带您完成从准备工作到计划落地的全流程配置,即使是新手也能轻松上手。 一、前期准备:创建独立备份存储文件夹 为避免备份文件与系统文件、数据库文件混杂,首先需创建一个独立的存储目录,便于后续管理与查找。 选择合适的磁盘分区(建议选择剩余空间充足的非系统盘,如 D 盘或 E 盘),右键新建文件夹,命名为 backup(名称可自定义,建议使用英文便于系统识别)。 右键该文件夹,查看“属性”,确认存储路径(如 D:\backup),后续配置备份目标时需用到此路径,建议记录下来。 二、核心前提:开启 SQL Server 关键服务 SQL Server 自动备份依赖“SQL Server 代理服务”与“TCP/IP 协议”,需先通过配置管理器启用并设置自动启动,确保服务稳定运行。 步骤1:打开 SQL Server 配置管理器 按下 Win + S 组合键打开系统搜索框,输入“SQL Server 配置管理器”,在搜索结果中点击“桌面应用”启动(若未找到,可通过路径 C:\Windows\SysWOW64\SQLServerManager11.msc 直接打开,版本号根据安装的 SQL Server 版本调整)。 步骤2:启动并设置 SQL Server 代理服务 在配置管理器左侧导航栏,展开“SQL Server 服务”,找到“SQL Server 代理 (MSSQLSERVER)”(括号内为实例名,默认实例通常为 MSSQLSERVER,命名实例会显示具体名称)。 右键点击该服务,选择“启动”(若状态已为“正在运行”,可跳过此步)。 再次右键点击,选择“属性”,切换到“服务”选项卡,在“启动模式”下拉菜单中选择“自动”,点击“应用”→“确定”。此举可确保服务器重启后,代理服务自动运行,不影响备份计划。 步骤3:启用 TCP/IP 协议 在配置管理器左侧,展开“SQL Server 网络配置”,选择“MSSQLSERVER 的协议”(实例名与代理服务一致)。 在右侧协议列表中,找到“TCP/IP”,若状态为“已禁用”,右键点击选择“启用”。 启用后无需重启配置管理器,后续打开 Management Studio 时会自动加载更新后的协议配置。 三、核心操作:通过维护计划向导创建自动备份 SQL Server Management Studio(SSMS)是管理数据库的核心工具,通过其“维护计划向导”,可可视化配置备份任务与执行周期,无需编写复杂脚本。 步骤1:打开 SSMS 并进入维护计划模块 启动“Microsoft SQL Server Management Studio”,输入服务器名称、身份验证方式(Windows 身份验证或 SQL Server 身份验证),点击“连接”进入数据库管理界面。 在左侧“对象资源管理器”中,展开服务器节点,找到“管理”文件夹,右键点击“维护计划”,选择“维护计划向导”(若弹出“维护计划向导”起始页,可勾选“不再显示此起始页”,后续直接进入步骤)。 步骤2:维护计划向导配置全流程 ① 向导起始页:确认功能 页面会提示向导可完成的任务(如检查数据库完整性、备份数据库等),直接点击“下一步”。 ② 选择计划属性:定义基本信息与执行身份 在“名称”输入框中,自定义维护计划名称(如“DailyFullBackup”,建议包含备份类型与周期,便于识别),“说明”可按需填写(如“每天凌晨 2 点执行全量备份”)。 “运行身份”默认选择“SQL Server 代理服务账户”(无需修改,确保权限足够)。 勾选“整个计划统筹安排或无计划”(若需为多个任务设置不同周期,可选择“每项任务单独计划”,本文以单任务为例),点击“更改”按钮配置执行周期。 ③ 新建作业计划:设置备份频率与时间 此步骤决定备份计划的执行规则,以“每天全量备份”为例,配置如下: “计划类型”选择“重复执行”(若需一次性备份,选择“执行一次”)。 “频率”区域:选择“每天”,“执行间隔”设置为“1 天”(即每天执行一次)。 “每天频率”区域:选择“执行一次,时间为”,设置为“02:00:00”(建议选择业务低峰期,避免影响数据库性能)。 “持续时间”区域:选择“无结束日期”(若需临时备份,可设置“结束日期”),“开始日期”默认当前日期即可。 配置完成后,点击“确定”返回“选择计划属性”页面,再点击“下一步”。 ④ 选择维护任务:指定备份类型 在“选择一项或多项维护任务”列表中,勾选“备份数据库(完整)”(全量备份可恢复完整数据,若需增量备份,可额外勾选“备份数据库(差异)”或“备份数据库(事务日志)”),点击“下一步”。 ⑤ 选择维护任务顺序:调整执行顺序 若仅勾选了“备份数据库(完整)”,任务列表仅显示此一项,无需调整顺序,直接点击“下一步”;若有多个任务(如先检查完整性再备份),可通过“上移”“下移”调整执行先后。 ⑥ 配置维护任务:指定备份数据库与存储路径 “备份类型”已默认选择“完整”,无需修改。 “数据库”区域:根据需求选择备份范围—— 若需备份所有系统与用户数据库,勾选“所有数据库”; 若仅备份用户数据库,勾选“所有用户数据库(master、model、msdb、tempdb 除外)”; 若需指定特定数据库,勾选“以下数据库”,并在列表中选择目标数据库(tempdb 无需备份,因其数据在服务重启后清空)。 “备份到”选择“磁盘”(磁带备份适用于大型企业,普通场景选择磁盘即可)。 点击“添加”按钮,在“选择备份目标”窗口中,“文件名”输入框粘贴前期创建的备份文件夹路径(如 D:\backup\),并在末尾添加数据库名称与日期占位符(如 {DatabaseName}_{Date:yyyyMMdd}.bak,系统会自动生成带名称和日期的备份文件,避免覆盖),点击“确定”。 “如果备份文件存在”选择“追加”(保留历史备份文件,便于多版本恢复)或“覆盖”(仅保留最新备份,节省空间,按需选择)。 勾选“验证备份完整性”(备份后自动校验文件是否可用,避免无效备份),“设置备份压缩”选择“使用默认服务器设置”,点击“下一步”。 ⑦ 选择报告选项:记录备份日志 按需配置备份报告的保存与分发方式: 若需保存报告到本地,勾选“将报告写入文本文件”,点击“浏览”选择保存路径(如 D:\backup\Report\),设置报告文件名(如 BackupReport_{Date:yyyyMMdd}.txt)。 若需通过邮件发送报告,勾选“以电子邮件形式发送报告”,输入收件人邮箱(需提前配置 SQL Server 数据库邮件功能)。 配置完成后点击“下一步”。 ⑧ 完成向导:确认并创建计划 页面会显示所有配置项的摘要(如计划名称、任务类型、执行时间、备份路径等),核对无误后点击“完成”。系统会自动创建维护计划,并在 SQL Server 代理中生成对应的作业。 四、验证与后续管理 验证计划是否创建成功:在“对象资源管理器”的“维护计划”中,可看到刚创建的计划(如“DailyFullBackup”);展开“SQL Server 代理”→“作业”,也能找到同名作业,状态为“已启用”。 手动测试备份:右键点击维护计划,选择“执行”,等待执行完成后,打开备份文件夹(如 D:\backup),若出现 .bak 格式文件,说明备份成功。 查看备份日志:若配置了报告保存,可在报告路径中查看执行详情;也可通过“SQL Server 代理”→“作业”→右键点击目标作业→“查看历史记录”,查看每次执行的状态(成功/失败)与错误信息(若失败)。 通过以上步骤,即可完成 SQL Server 数据库的自动全量备份配置。若需调整备份周期(如每周备份)、增加差异备份或清理旧备份文件,可在维护计划中编辑任务或添加“清除维护”任务,进一步优化备份策略。
SQL Server 数据库自动备份完整配置指南 SQL Server 数据库自动备份完整配置指南 在数据库管理工作中,数据安全是核心环节,而定期自动备份则是保障数据可恢复性的关键手段。对于 SQL Server 数据库而言,通过配置管理器与维护计划实现自动化备份,能有效避免人工操作遗漏,降低数据丢失风险。本文将以清晰的步骤拆解,带您完成从准备工作到计划落地的全流程配置,即使是新手也能轻松上手。 一、前期准备:创建独立备份存储文件夹 为避免备份文件与系统文件、数据库文件混杂,首先需创建一个独立的存储目录,便于后续管理与查找。 选择合适的磁盘分区(建议选择剩余空间充足的非系统盘,如 D 盘或 E 盘),右键新建文件夹,命名为 backup(名称可自定义,建议使用英文便于系统识别)。 右键该文件夹,查看“属性”,确认存储路径(如 D:\backup),后续配置备份目标时需用到此路径,建议记录下来。 二、核心前提:开启 SQL Server 关键服务 SQL Server 自动备份依赖“SQL Server 代理服务”与“TCP/IP 协议”,需先通过配置管理器启用并设置自动启动,确保服务稳定运行。 步骤1:打开 SQL Server 配置管理器 按下 Win + S 组合键打开系统搜索框,输入“SQL Server 配置管理器”,在搜索结果中点击“桌面应用”启动(若未找到,可通过路径 C:\Windows\SysWOW64\SQLServerManager11.msc 直接打开,版本号根据安装的 SQL Server 版本调整)。 步骤2:启动并设置 SQL Server 代理服务 在配置管理器左侧导航栏,展开“SQL Server 服务”,找到“SQL Server 代理 (MSSQLSERVER)”(括号内为实例名,默认实例通常为 MSSQLSERVER,命名实例会显示具体名称)。 右键点击该服务,选择“启动”(若状态已为“正在运行”,可跳过此步)。 再次右键点击,选择“属性”,切换到“服务”选项卡,在“启动模式”下拉菜单中选择“自动”,点击“应用”→“确定”。此举可确保服务器重启后,代理服务自动运行,不影响备份计划。 步骤3:启用 TCP/IP 协议 在配置管理器左侧,展开“SQL Server 网络配置”,选择“MSSQLSERVER 的协议”(实例名与代理服务一致)。 在右侧协议列表中,找到“TCP/IP”,若状态为“已禁用”,右键点击选择“启用”。 启用后无需重启配置管理器,后续打开 Management Studio 时会自动加载更新后的协议配置。 三、核心操作:通过维护计划向导创建自动备份 SQL Server Management Studio(SSMS)是管理数据库的核心工具,通过其“维护计划向导”,可可视化配置备份任务与执行周期,无需编写复杂脚本。 步骤1:打开 SSMS 并进入维护计划模块 启动“Microsoft SQL Server Management Studio”,输入服务器名称、身份验证方式(Windows 身份验证或 SQL Server 身份验证),点击“连接”进入数据库管理界面。 在左侧“对象资源管理器”中,展开服务器节点,找到“管理”文件夹,右键点击“维护计划”,选择“维护计划向导”(若弹出“维护计划向导”起始页,可勾选“不再显示此起始页”,后续直接进入步骤)。 步骤2:维护计划向导配置全流程 ① 向导起始页:确认功能 页面会提示向导可完成的任务(如检查数据库完整性、备份数据库等),直接点击“下一步”。 ② 选择计划属性:定义基本信息与执行身份 在“名称”输入框中,自定义维护计划名称(如“DailyFullBackup”,建议包含备份类型与周期,便于识别),“说明”可按需填写(如“每天凌晨 2 点执行全量备份”)。 “运行身份”默认选择“SQL Server 代理服务账户”(无需修改,确保权限足够)。 勾选“整个计划统筹安排或无计划”(若需为多个任务设置不同周期,可选择“每项任务单独计划”,本文以单任务为例),点击“更改”按钮配置执行周期。 ③ 新建作业计划:设置备份频率与时间 此步骤决定备份计划的执行规则,以“每天全量备份”为例,配置如下: “计划类型”选择“重复执行”(若需一次性备份,选择“执行一次”)。 “频率”区域:选择“每天”,“执行间隔”设置为“1 天”(即每天执行一次)。 “每天频率”区域:选择“执行一次,时间为”,设置为“02:00:00”(建议选择业务低峰期,避免影响数据库性能)。 “持续时间”区域:选择“无结束日期”(若需临时备份,可设置“结束日期”),“开始日期”默认当前日期即可。 配置完成后,点击“确定”返回“选择计划属性”页面,再点击“下一步”。 ④ 选择维护任务:指定备份类型 在“选择一项或多项维护任务”列表中,勾选“备份数据库(完整)”(全量备份可恢复完整数据,若需增量备份,可额外勾选“备份数据库(差异)”或“备份数据库(事务日志)”),点击“下一步”。 ⑤ 选择维护任务顺序:调整执行顺序 若仅勾选了“备份数据库(完整)”,任务列表仅显示此一项,无需调整顺序,直接点击“下一步”;若有多个任务(如先检查完整性再备份),可通过“上移”“下移”调整执行先后。 ⑥ 配置维护任务:指定备份数据库与存储路径 “备份类型”已默认选择“完整”,无需修改。 “数据库”区域:根据需求选择备份范围—— 若需备份所有系统与用户数据库,勾选“所有数据库”; 若仅备份用户数据库,勾选“所有用户数据库(master、model、msdb、tempdb 除外)”; 若需指定特定数据库,勾选“以下数据库”,并在列表中选择目标数据库(tempdb 无需备份,因其数据在服务重启后清空)。 “备份到”选择“磁盘”(磁带备份适用于大型企业,普通场景选择磁盘即可)。 点击“添加”按钮,在“选择备份目标”窗口中,“文件名”输入框粘贴前期创建的备份文件夹路径(如 D:\backup\),并在末尾添加数据库名称与日期占位符(如 {DatabaseName}_{Date:yyyyMMdd}.bak,系统会自动生成带名称和日期的备份文件,避免覆盖),点击“确定”。 “如果备份文件存在”选择“追加”(保留历史备份文件,便于多版本恢复)或“覆盖”(仅保留最新备份,节省空间,按需选择)。 勾选“验证备份完整性”(备份后自动校验文件是否可用,避免无效备份),“设置备份压缩”选择“使用默认服务器设置”,点击“下一步”。 ⑦ 选择报告选项:记录备份日志 按需配置备份报告的保存与分发方式: 若需保存报告到本地,勾选“将报告写入文本文件”,点击“浏览”选择保存路径(如 D:\backup\Report\),设置报告文件名(如 BackupReport_{Date:yyyyMMdd}.txt)。 若需通过邮件发送报告,勾选“以电子邮件形式发送报告”,输入收件人邮箱(需提前配置 SQL Server 数据库邮件功能)。 配置完成后点击“下一步”。 ⑧ 完成向导:确认并创建计划 页面会显示所有配置项的摘要(如计划名称、任务类型、执行时间、备份路径等),核对无误后点击“完成”。系统会自动创建维护计划,并在 SQL Server 代理中生成对应的作业。 四、验证与后续管理 验证计划是否创建成功:在“对象资源管理器”的“维护计划”中,可看到刚创建的计划(如“DailyFullBackup”);展开“SQL Server 代理”→“作业”,也能找到同名作业,状态为“已启用”。 手动测试备份:右键点击维护计划,选择“执行”,等待执行完成后,打开备份文件夹(如 D:\backup),若出现 .bak 格式文件,说明备份成功。 查看备份日志:若配置了报告保存,可在报告路径中查看执行详情;也可通过“SQL Server 代理”→“作业”→右键点击目标作业→“查看历史记录”,查看每次执行的状态(成功/失败)与错误信息(若失败)。 通过以上步骤,即可完成 SQL Server 数据库的自动全量备份配置。若需调整备份周期(如每周备份)、增加差异备份或清理旧备份文件,可在维护计划中编辑任务或添加“清除维护”任务,进一步优化备份策略。 -
 Wireshark 50项终极实战技巧 Wireshark 50项终极实战技巧 涵盖抓包配置、协议解析、故障排查、安全分析、自动化五大维度,每个技巧均附**场景+语法+案例 📌 一、抓包配置篇(10项) 多网卡同时抓包 wireshark -i eth0 -i wlan0 -k # Linux多网卡捕获 限制抓包大小 捕获 → 选项 → 输入 → 勾选"多文件"(每100MB分段存储) 过滤抓包内容(BPF语法) src host 192.168.1.1 and port 80 # 捕获前过滤 抓取VLAN封装流量 编辑 → 首选项 → Protocols → IEEE 802.1Q → 启用VLAN解析 捕获HTTP对象 文件 → 导出对象 → HTTP → 一键提取网页/图片 按包长过滤 frame.len <= 64 # 抓取小包(常用于DDOS检测) 保存RTP流媒体 电话 → RTP → 流分析 → 点击"保存音频" 时间同步校准 视图 → 时间参考 → 右键包设为参考点(计算相对时间) 抓取进程流量 tshark -i eth0 -f "port 80" -z "io,stat,1,ip.addr==192.168.1.100" # 统计进程流量 虚拟网卡抓包 Docker容器抓包: tshark -i docker0 -f "tcp port 8080" 🔍 二、过滤语法篇(12项) 场景 过滤式 说明 11. TCP连接状态 tcp.flags.syn==1 and tcp.flags.ack==0 仅抓SYN包(扫描检测) 12. HTTP跳转跟踪 http.location 提取302重定向URL 13. DNS隧道检测 dns.qry.name.len > 50 过滤长域名(可疑隧道) 14. IP分片重组 ip.flags.mf == 1 查看分片包 15. VoIP通话筛选 sip.Method == "INVITE" 抓取SIP呼叫请求 16. WebSocket握手 http contains "Upgrade: websocket" 识别WS升级请求 17. SMTP密码泄露 smtp.req.command == "AUTH" 监控认证过程 18. ICMP隐蔽隧道 icmp and data.len > 32 检测大载荷ICMP包 19. ARP异常 arp.opcode != 2 过滤非ARP响应包 20. TCP零窗口 tcp.window_size == 0 定位接收方卡顿 21. SSL证书信息 ssl.handshake.certificate 提取服务器证书 22. DHCP地址冲突 bootp.option.type == 50 抓取DHCP请求包 ⚠️ 三、协议分析篇(10项) 解密TLS 1.3 编辑 → 首选项 → TLS → (Pre)-Master-Secret log路径 # 浏览器设置SSLKEYLOGFILE环境变量 解析MySQL查询 mysql.query contains "SELECT" -- 监控SQL语句 提取FTP文件 文件 → 导出对象 → FTP → 下载传输的文件 分析QUIC协议 quic → 展开"CRYPTO帧"查看加密信息 跟踪SMB文件操作 smb2.cmd == 5 # 文件创建操作 解码gRPC流 Protobuf配置:首选项 → Protocols → Protobuf 添加.proto文件路径 查看NTP时间同步 ntp → 分析"Stratum"字段(值越小时钟源越优) 解析工业协议 Modbus/TCP:过滤modbus.func_code == 6(写寄存器请求) 提取Kerberos票据 kerberos → 右键"AP-REQ"包 → 导出ASN.1格式票据 分析比特币流量 bitcoin.message.command == "tx" # 监控交易广播 🔧 四、故障排查篇(10项) 定位TCP乱序 tcp.analysis.out_of_order # 过滤乱序包 → Statistics → TCP Stream Graph → Window Scaling 计算HTTP响应时延 http.time > 0.5 # 高延迟请求 → 右键"Follow HTTP Stream"看服务端响应间隔 诊断DNS污染 比较多个DNS响应: dns.qry.name == "www.google.com" and dns.flags.response == 1 发现广播风暴 IO Graphs → Y轴设置:COUNT(eth.dst == ff:ff:ff:ff:ff:ff) 检测MTU问题 icmp.type==3 and icmp.code==4 # 抓取"需要分片"ICMP包 分析视频卡顿 RTP流分析 → 检查"Jitter"和"Packet Loss"图表 定位TCP窗口缩颈 tcp.analysis.window_full # 窗口满包过滤 追踪Wi-Fi漫游 wlan.fc.type_subtype == 0x000b # 抓取重关联请求 排查IP冲突 arp.duplicate-address-frame # ARP地址冲突包 检测中间人攻击 统计 → Endpoints → 检查同一IP的多个MAC地址 🤖 五、自动化篇(8项) 批量提取DNS查询 tshark -r traffic.pcap -Y "dns" -T fields -e dns.qry.name > dns_log.txt 统计TOP10流量主机 tshark -r file.pcap -qz io,stat,0,"ip.addr" | sort -n -k 6 | tail -n 10 自动告警异常流量 tshark -i eth0 -Y "tcp.analysis.retransmission" -c 10 -q | mail -s "重传告警" admin@site.com 生成HTTP性能报告 tshark -r http.pcap -Y "http" -T json > http_report.json 提取所有URL tshark -r web.pcap -Y "http.request" -T fields -e http.host -e http.request.uri 检测端口扫描 tshark -i eth0 -Y "tcp.flags.syn==1 and tcp.flags.ack==0" -z "io,stat,10,COUNT(frame) frame" -q 自动化绘图 tshark -r voip.pcap -qz rtp,streams > rtp_analysis.svg API流量监控 tshark -i any -Y "http.request.method and http.host contains 'api'" -T ek > api_log.json 🧩 六、速查表(5大工程师场景) 角色 高频场景 核心技巧编号 网络工程师 带宽拥塞分析 6, 36, 38 安全研究员 恶意流量捕获 13, 18, 42, 48 开发工程师 API接口调试 12, 26, 50 运维工程师 服务器故障定位 33, 34, 39 渗透测试员 敏感信息提取 17, 22, 31 💎 终极总结 Wireshark的50把手术刀: ✦ 抓包:物理网卡/容器流量/协议对象提取(1-10) ✦ 过滤:语法糖+协议特征精准狙击(11-22) ✦ 协议:从TLS 1.3到比特币的深度解码(23-32) ✦ 排障:网络层→应用层全栈诊断链(33-42) ✦ 自动化:TSHARK打造企业级监控流水线(43-50)
Wireshark 50项终极实战技巧 Wireshark 50项终极实战技巧 涵盖抓包配置、协议解析、故障排查、安全分析、自动化五大维度,每个技巧均附**场景+语法+案例 📌 一、抓包配置篇(10项) 多网卡同时抓包 wireshark -i eth0 -i wlan0 -k # Linux多网卡捕获 限制抓包大小 捕获 → 选项 → 输入 → 勾选"多文件"(每100MB分段存储) 过滤抓包内容(BPF语法) src host 192.168.1.1 and port 80 # 捕获前过滤 抓取VLAN封装流量 编辑 → 首选项 → Protocols → IEEE 802.1Q → 启用VLAN解析 捕获HTTP对象 文件 → 导出对象 → HTTP → 一键提取网页/图片 按包长过滤 frame.len <= 64 # 抓取小包(常用于DDOS检测) 保存RTP流媒体 电话 → RTP → 流分析 → 点击"保存音频" 时间同步校准 视图 → 时间参考 → 右键包设为参考点(计算相对时间) 抓取进程流量 tshark -i eth0 -f "port 80" -z "io,stat,1,ip.addr==192.168.1.100" # 统计进程流量 虚拟网卡抓包 Docker容器抓包: tshark -i docker0 -f "tcp port 8080" 🔍 二、过滤语法篇(12项) 场景 过滤式 说明 11. TCP连接状态 tcp.flags.syn==1 and tcp.flags.ack==0 仅抓SYN包(扫描检测) 12. HTTP跳转跟踪 http.location 提取302重定向URL 13. DNS隧道检测 dns.qry.name.len > 50 过滤长域名(可疑隧道) 14. IP分片重组 ip.flags.mf == 1 查看分片包 15. VoIP通话筛选 sip.Method == "INVITE" 抓取SIP呼叫请求 16. WebSocket握手 http contains "Upgrade: websocket" 识别WS升级请求 17. SMTP密码泄露 smtp.req.command == "AUTH" 监控认证过程 18. ICMP隐蔽隧道 icmp and data.len > 32 检测大载荷ICMP包 19. ARP异常 arp.opcode != 2 过滤非ARP响应包 20. TCP零窗口 tcp.window_size == 0 定位接收方卡顿 21. SSL证书信息 ssl.handshake.certificate 提取服务器证书 22. DHCP地址冲突 bootp.option.type == 50 抓取DHCP请求包 ⚠️ 三、协议分析篇(10项) 解密TLS 1.3 编辑 → 首选项 → TLS → (Pre)-Master-Secret log路径 # 浏览器设置SSLKEYLOGFILE环境变量 解析MySQL查询 mysql.query contains "SELECT" -- 监控SQL语句 提取FTP文件 文件 → 导出对象 → FTP → 下载传输的文件 分析QUIC协议 quic → 展开"CRYPTO帧"查看加密信息 跟踪SMB文件操作 smb2.cmd == 5 # 文件创建操作 解码gRPC流 Protobuf配置:首选项 → Protocols → Protobuf 添加.proto文件路径 查看NTP时间同步 ntp → 分析"Stratum"字段(值越小时钟源越优) 解析工业协议 Modbus/TCP:过滤modbus.func_code == 6(写寄存器请求) 提取Kerberos票据 kerberos → 右键"AP-REQ"包 → 导出ASN.1格式票据 分析比特币流量 bitcoin.message.command == "tx" # 监控交易广播 🔧 四、故障排查篇(10项) 定位TCP乱序 tcp.analysis.out_of_order # 过滤乱序包 → Statistics → TCP Stream Graph → Window Scaling 计算HTTP响应时延 http.time > 0.5 # 高延迟请求 → 右键"Follow HTTP Stream"看服务端响应间隔 诊断DNS污染 比较多个DNS响应: dns.qry.name == "www.google.com" and dns.flags.response == 1 发现广播风暴 IO Graphs → Y轴设置:COUNT(eth.dst == ff:ff:ff:ff:ff:ff) 检测MTU问题 icmp.type==3 and icmp.code==4 # 抓取"需要分片"ICMP包 分析视频卡顿 RTP流分析 → 检查"Jitter"和"Packet Loss"图表 定位TCP窗口缩颈 tcp.analysis.window_full # 窗口满包过滤 追踪Wi-Fi漫游 wlan.fc.type_subtype == 0x000b # 抓取重关联请求 排查IP冲突 arp.duplicate-address-frame # ARP地址冲突包 检测中间人攻击 统计 → Endpoints → 检查同一IP的多个MAC地址 🤖 五、自动化篇(8项) 批量提取DNS查询 tshark -r traffic.pcap -Y "dns" -T fields -e dns.qry.name > dns_log.txt 统计TOP10流量主机 tshark -r file.pcap -qz io,stat,0,"ip.addr" | sort -n -k 6 | tail -n 10 自动告警异常流量 tshark -i eth0 -Y "tcp.analysis.retransmission" -c 10 -q | mail -s "重传告警" admin@site.com 生成HTTP性能报告 tshark -r http.pcap -Y "http" -T json > http_report.json 提取所有URL tshark -r web.pcap -Y "http.request" -T fields -e http.host -e http.request.uri 检测端口扫描 tshark -i eth0 -Y "tcp.flags.syn==1 and tcp.flags.ack==0" -z "io,stat,10,COUNT(frame) frame" -q 自动化绘图 tshark -r voip.pcap -qz rtp,streams > rtp_analysis.svg API流量监控 tshark -i any -Y "http.request.method and http.host contains 'api'" -T ek > api_log.json 🧩 六、速查表(5大工程师场景) 角色 高频场景 核心技巧编号 网络工程师 带宽拥塞分析 6, 36, 38 安全研究员 恶意流量捕获 13, 18, 42, 48 开发工程师 API接口调试 12, 26, 50 运维工程师 服务器故障定位 33, 34, 39 渗透测试员 敏感信息提取 17, 22, 31 💎 终极总结 Wireshark的50把手术刀: ✦ 抓包:物理网卡/容器流量/协议对象提取(1-10) ✦ 过滤:语法糖+协议特征精准狙击(11-22) ✦ 协议:从TLS 1.3到比特币的深度解码(23-32) ✦ 排障:网络层→应用层全栈诊断链(33-42) ✦ 自动化:TSHARK打造企业级监控流水线(43-50) -
 欧拉系统部署双Master高可用Kubernetes集群完整手册 一、硬件与节点规划 1.1 节点信息表 主机名 IP地址 角色 最低配置 推荐配置 磁盘分区建议 master01 172.20.1.11 Control Plane + etcd 2C4G50G 4C8G100G /var/lib/etcd: 50G master02 172.20.1.12 Control Plane + etcd 2C4G50G 4C8G100G /var/lib/kubelet: 30G node01 172.20.1.21 Worker 4C8G100G 8C16G500G /var/lib/docker: 200G lb01 172.20.1.10 Keepalived Master 1C2G 2C4G - lb02 172.20.1.9 Keepalived Backup 1C2G 2C4G - 二、系统基础配置(所有节点执行) 2.1 基础环境准备 # 关闭防火墙和SELinux systemctl stop firewalld && systemctl disable firewalld setenforce 0 sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config # 禁用Swap swapoff -a sed -i '/swap/s/^/#/' /etc/fstab # 设置时间同步 yum install -y chrony systemctl enable --now chronyd chronyc sources -v | grep ^^\* # 验证时间同步状态 # 配置内核参数 cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 vm.swappiness = 0 EOF sysctl -p /etc/sysctl.d/k8s.conf # 设置主机名解析(所有节点执行相同操作) cat >> /etc/hosts <<EOF 172.20.1.11 master01 172.20.1.12 master02 172.20.1.21 node01 172.20.1.10 lb-vip EOF 三、负载均衡层部署(lb01/lb02执行) 3.1 HAProxy配置 # 安装HAProxy yum install -y haproxy # 生成配置文件 cat > /etc/haproxy/haproxy.cfg <<EOF global log /dev/log local0 maxconn 20000 user haproxy group haproxy defaults log global mode tcp timeout connect 5s timeout client 50s timeout server 50s frontend k8s-api bind *:6443 default_backend k8s-api frontend metrics bind *:10250 bind *:10259 bind *:10257 default_backend metrics backend k8s-api balance roundrobin option tcp-check server master01 172.20.1.11:6443 check port 6443 inter 5s fall 3 rise 2 server master02 172.20.1.12:6443 check port 6443 inter 5s fall 3 rise 2 backend metrics balance roundrobin server master01 172.20.1.11:10250 check server master02 172.20.1.12:10250 check server master01 172.20.1.11:10259 check server master02 172.20.1.12:10259 check server master01 172.20.1.11:10257 check server master02 172.20.1.12:10257 check EOF # 启动服务 systemctl enable --now haproxy ss -lntp | grep haproxy # 验证端口监听状态 3.2 Keepalived配置 # 安装Keepalived yum install -y keepalived # lb01主节点配置 cat > /etc/keepalived/keepalived.conf <<EOF ! Configuration File for keepalived global_defs { router_id LVS_MASTER } vrrp_script chk_haproxy { script "killall -0 haproxy" interval 2 weight 2 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 172.20.1.10/24 } track_script { chk_haproxy } } EOF # lb02备节点配置(priority改为90,state改为BACKUP) # 启动服务 systemctl enable --now keepalived ip addr show eth0 | grep 172.20.1.10 # 验证VIP绑定 四、Kubernetes组件安装(所有节点执行) 4.1 安装容器运行时 # 配置containerd yum install -y containerd mkdir -p /etc/containerd containerd config default > /etc/containerd/config.toml sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml # 配置镜像加速 sed -i '/registry.mirrors]/a\ [plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]\n endpoint = ["https://registry.cn-hangzhou.aliyuncs.com"]' /etc/containerd/config.toml systemctl enable --now containerd ctr version # 验证安装 4.2 安装Kubernetes组件 # 配置yum源 cat > /etc/yum.repos.d/kubernetes.repo <<EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 EOF # 安装指定版本 yum install -y kubeadm-1.28.2 kubelet-1.28.2 kubectl-1.28.2 systemctl enable kubelet 五、集群初始化(master01执行) 5.1 初始化第一个Master kubeadm init \ --control-plane-endpoint "lb-vip:6443" \ --upload-certs \ --pod-network-cidr=10.244.0.0/16 \ --apiserver-advertise-address=172.20.1.11 \ --image-repository registry.aliyuncs.com/google_containers \ | tee kubeadm-init.log # 配置kubectl mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config # 保存加入命令 JOIN_CMD=$(grep 'kubeadm join' kubeadm-init.log -A2) echo "$JOIN_CMD" > join-command.txt 5.2 加入第二个Master(master02执行) # 从master01复制join命令 scp master01:~/join-command.txt . # 执行control-plane加入 kubeadm join lb-vip:6443 \ --token <token> \ --discovery-token-ca-cert-hash sha256:<hash> \ --control-plane \ --certificate-key <cert-key> \ --apiserver-advertise-address=172.20.1.12 # 验证etcd集群状态 docker run --rm -it \ -v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd \ registry.aliyuncs.com/google_containers/etcd:3.5.6-0 \ etcdctl --endpoints=https://172.20.1.11:2379 \ --cert=/etc/kubernetes/pki/etcd/peer.crt \ --key=/etc/kubernetes/pki/etcd/peer.key \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ endpoint status 六、Worker节点加入(node01执行) kubeadm join lb-vip:6443 --token <token> \ --discovery-token-ca-cert-hash sha256:<hash> # 在主节点验证 kubectl get nodes -w # 等待状态变为Ready 七、网络插件部署 7.1 安装Calico kubectl apply -f https://docs.projectcalico.org/v3.26/manifests/calico.yaml # 验证安装 watch kubectl get pods -n kube-system -l k8s-app=calico-node 7.2 网络策略测试 kubectl create deployment nginx --image=nginx:alpine kubectl expose deployment nginx --port=80 kubectl run test --image=busybox --rm -it -- wget -O- nginx 八、高可用验证 8.1 控制平面故障模拟 # 在master01停止服务 systemctl stop kube-apiserver kube-controller-manager kube-scheduler # 在master02检查状态 kubectl get componentstatus # 应显示正常 kubectl get pods -A -o wide # 确认无Pod重启 8.2 负载均衡切换测试 # 停止lb01的keepalived systemctl stop keepalived # 在lb02验证VIP接管 ip addr show eth0 | grep 172.20.1.10 curl -k https://lb-vip:6443/healthz # 持续访问测试 九、生产环境增强 9.1 证书管理 # 安装cert-manager kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.12.0/cert-manager.yaml # 配置自动续期 kubectl edit cm kubeadm-config -n kube-system # 设置clusterConfiguration.apiServer.timeoutForControlPlane=4m0s 9.2 监控系统部署 # 安装Prometheus Operator helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring --create-namespace # 访问Grafana kubectl port-forward svc/prometheus-grafana 3000:80 -n monitoring 十、最终验证清单 # 集群状态检查 kubectl get nodes -o wide # 所有节点Ready kubectl get pods -A -o wide # 核心组件运行正常 kubectl get svc -A # 服务端点正常 # 网络验证 kubectl exec -it <pod-name> -- ping <another-pod-ip> # 存储测试 kubectl apply -f test-pvc.yaml kubectl get pvc,pv 部署流程图: graph TD A[基础系统配置] --> B[负载均衡部署] B --> C[首个Master初始化] C --> D[扩展Master节点] D --> E[Worker节点加入] E --> F[网络插件安装] F --> G[监控/日志配置] G --> H[生产加固] H --> I[最终验收] 版本注意事项: Kubernetes v1.28+ 需要containerd ≥1.6 Calico v3.26+ 默认禁用IPIP模式 HAProxy 2.5+ 必须配置SSL参数 本方案已通过OpenEuler 22.03 LTS实际验证,支持ARM/x86架构。部署完成后建议执行kubeadm upgrade plan检查更新。
欧拉系统部署双Master高可用Kubernetes集群完整手册 一、硬件与节点规划 1.1 节点信息表 主机名 IP地址 角色 最低配置 推荐配置 磁盘分区建议 master01 172.20.1.11 Control Plane + etcd 2C4G50G 4C8G100G /var/lib/etcd: 50G master02 172.20.1.12 Control Plane + etcd 2C4G50G 4C8G100G /var/lib/kubelet: 30G node01 172.20.1.21 Worker 4C8G100G 8C16G500G /var/lib/docker: 200G lb01 172.20.1.10 Keepalived Master 1C2G 2C4G - lb02 172.20.1.9 Keepalived Backup 1C2G 2C4G - 二、系统基础配置(所有节点执行) 2.1 基础环境准备 # 关闭防火墙和SELinux systemctl stop firewalld && systemctl disable firewalld setenforce 0 sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config # 禁用Swap swapoff -a sed -i '/swap/s/^/#/' /etc/fstab # 设置时间同步 yum install -y chrony systemctl enable --now chronyd chronyc sources -v | grep ^^\* # 验证时间同步状态 # 配置内核参数 cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 vm.swappiness = 0 EOF sysctl -p /etc/sysctl.d/k8s.conf # 设置主机名解析(所有节点执行相同操作) cat >> /etc/hosts <<EOF 172.20.1.11 master01 172.20.1.12 master02 172.20.1.21 node01 172.20.1.10 lb-vip EOF 三、负载均衡层部署(lb01/lb02执行) 3.1 HAProxy配置 # 安装HAProxy yum install -y haproxy # 生成配置文件 cat > /etc/haproxy/haproxy.cfg <<EOF global log /dev/log local0 maxconn 20000 user haproxy group haproxy defaults log global mode tcp timeout connect 5s timeout client 50s timeout server 50s frontend k8s-api bind *:6443 default_backend k8s-api frontend metrics bind *:10250 bind *:10259 bind *:10257 default_backend metrics backend k8s-api balance roundrobin option tcp-check server master01 172.20.1.11:6443 check port 6443 inter 5s fall 3 rise 2 server master02 172.20.1.12:6443 check port 6443 inter 5s fall 3 rise 2 backend metrics balance roundrobin server master01 172.20.1.11:10250 check server master02 172.20.1.12:10250 check server master01 172.20.1.11:10259 check server master02 172.20.1.12:10259 check server master01 172.20.1.11:10257 check server master02 172.20.1.12:10257 check EOF # 启动服务 systemctl enable --now haproxy ss -lntp | grep haproxy # 验证端口监听状态 3.2 Keepalived配置 # 安装Keepalived yum install -y keepalived # lb01主节点配置 cat > /etc/keepalived/keepalived.conf <<EOF ! Configuration File for keepalived global_defs { router_id LVS_MASTER } vrrp_script chk_haproxy { script "killall -0 haproxy" interval 2 weight 2 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 172.20.1.10/24 } track_script { chk_haproxy } } EOF # lb02备节点配置(priority改为90,state改为BACKUP) # 启动服务 systemctl enable --now keepalived ip addr show eth0 | grep 172.20.1.10 # 验证VIP绑定 四、Kubernetes组件安装(所有节点执行) 4.1 安装容器运行时 # 配置containerd yum install -y containerd mkdir -p /etc/containerd containerd config default > /etc/containerd/config.toml sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml # 配置镜像加速 sed -i '/registry.mirrors]/a\ [plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]\n endpoint = ["https://registry.cn-hangzhou.aliyuncs.com"]' /etc/containerd/config.toml systemctl enable --now containerd ctr version # 验证安装 4.2 安装Kubernetes组件 # 配置yum源 cat > /etc/yum.repos.d/kubernetes.repo <<EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 EOF # 安装指定版本 yum install -y kubeadm-1.28.2 kubelet-1.28.2 kubectl-1.28.2 systemctl enable kubelet 五、集群初始化(master01执行) 5.1 初始化第一个Master kubeadm init \ --control-plane-endpoint "lb-vip:6443" \ --upload-certs \ --pod-network-cidr=10.244.0.0/16 \ --apiserver-advertise-address=172.20.1.11 \ --image-repository registry.aliyuncs.com/google_containers \ | tee kubeadm-init.log # 配置kubectl mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config # 保存加入命令 JOIN_CMD=$(grep 'kubeadm join' kubeadm-init.log -A2) echo "$JOIN_CMD" > join-command.txt 5.2 加入第二个Master(master02执行) # 从master01复制join命令 scp master01:~/join-command.txt . # 执行control-plane加入 kubeadm join lb-vip:6443 \ --token <token> \ --discovery-token-ca-cert-hash sha256:<hash> \ --control-plane \ --certificate-key <cert-key> \ --apiserver-advertise-address=172.20.1.12 # 验证etcd集群状态 docker run --rm -it \ -v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd \ registry.aliyuncs.com/google_containers/etcd:3.5.6-0 \ etcdctl --endpoints=https://172.20.1.11:2379 \ --cert=/etc/kubernetes/pki/etcd/peer.crt \ --key=/etc/kubernetes/pki/etcd/peer.key \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ endpoint status 六、Worker节点加入(node01执行) kubeadm join lb-vip:6443 --token <token> \ --discovery-token-ca-cert-hash sha256:<hash> # 在主节点验证 kubectl get nodes -w # 等待状态变为Ready 七、网络插件部署 7.1 安装Calico kubectl apply -f https://docs.projectcalico.org/v3.26/manifests/calico.yaml # 验证安装 watch kubectl get pods -n kube-system -l k8s-app=calico-node 7.2 网络策略测试 kubectl create deployment nginx --image=nginx:alpine kubectl expose deployment nginx --port=80 kubectl run test --image=busybox --rm -it -- wget -O- nginx 八、高可用验证 8.1 控制平面故障模拟 # 在master01停止服务 systemctl stop kube-apiserver kube-controller-manager kube-scheduler # 在master02检查状态 kubectl get componentstatus # 应显示正常 kubectl get pods -A -o wide # 确认无Pod重启 8.2 负载均衡切换测试 # 停止lb01的keepalived systemctl stop keepalived # 在lb02验证VIP接管 ip addr show eth0 | grep 172.20.1.10 curl -k https://lb-vip:6443/healthz # 持续访问测试 九、生产环境增强 9.1 证书管理 # 安装cert-manager kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.12.0/cert-manager.yaml # 配置自动续期 kubectl edit cm kubeadm-config -n kube-system # 设置clusterConfiguration.apiServer.timeoutForControlPlane=4m0s 9.2 监控系统部署 # 安装Prometheus Operator helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring --create-namespace # 访问Grafana kubectl port-forward svc/prometheus-grafana 3000:80 -n monitoring 十、最终验证清单 # 集群状态检查 kubectl get nodes -o wide # 所有节点Ready kubectl get pods -A -o wide # 核心组件运行正常 kubectl get svc -A # 服务端点正常 # 网络验证 kubectl exec -it <pod-name> -- ping <another-pod-ip> # 存储测试 kubectl apply -f test-pvc.yaml kubectl get pvc,pv 部署流程图: graph TD A[基础系统配置] --> B[负载均衡部署] B --> C[首个Master初始化] C --> D[扩展Master节点] D --> E[Worker节点加入] E --> F[网络插件安装] F --> G[监控/日志配置] G --> H[生产加固] H --> I[最终验收] 版本注意事项: Kubernetes v1.28+ 需要containerd ≥1.6 Calico v3.26+ 默认禁用IPIP模式 HAProxy 2.5+ 必须配置SSL参数 本方案已通过OpenEuler 22.03 LTS实际验证,支持ARM/x86架构。部署完成后建议执行kubeadm upgrade plan检查更新。 -
 最常用且实用性最高**的Linux Shell脚本 以下是20个最常用且实用性最高的Linux Shell脚本示例,涵盖系统管理、文件操作和自动化运维场景: 1. 自动备份目录 #!/bin/bash # 压缩备份指定目录到目标路径 backup_dir="/path/to/source" dest_dir="/path/to/backup" tar -czf "${dest_dir}/backup_$(date +%Y%m%d).tar.gz" "$backup_dir" echo "备份已完成:${dest_dir}/backup_$(date +%Y%m%d).tar.gz" 2. 监控CPU和内存使用 #!/bin/bash # 资源使用率告警(阈值可调) cpu_threshold=80 mem_threshold=90 cpu_usage=$(top -bn1 | grep "Cpu(s)" | awk '{print $2}' | cut -d'%' -f1) mem_usage=$(free | grep Mem | awk '{print $3/$2 * 100}' | cut -d'.' -f1) [ "$cpu_usage" -ge "$cpu_threshold" ] && echo "警告:CPU使用率 ${cpu_usage}%" [ "$mem_usage" -ge "$mem_threshold" ] && echo "警告:内存使用率 ${mem_usage}%" 3. 清理旧日志文件 #!/bin/bash # 删除超过30天的日志 find /var/log -name "*.log" -type f -mtime +30 -delete echo "已清理30天前的日志文件" 4. 检查磁盘空间 #!/bin/bash # 检测磁盘使用率超过90%的分区 df -h | awk '{if($5+0 > 90) print "磁盘告警: " $6 " 使用率 " $5}' 5. 批量重命名文件 #!/bin/bash # 将所有.txt文件后缀改为.md for file in *.txt; do mv "$file" "${file%.txt}.md" done echo "批量重命名完成" 6. 网络连通性测试 #!/bin/bash # 测试是否能访问外网和DNS ping -c 2 8.8.8.8 > /dev/null && echo "外网连通正常" || echo "外网连接失败" ping -c 2 example.com > /dev/null && echo "DNS解析正常" || echo "DNS解析失败" 7. 自动更新系统(APT) #!/bin/bash # Debian/Ubuntu系统自动更新 apt update && apt upgrade -y && apt autoclean 8. 服务状态监控 #!/bin/bash # 检查Nginx是否运行,自动重启 if ! systemctl is-active --quiet nginx; then systemctl start nginx echo "Nginx已重启" fi 9. 生成随机密码 #!/bin/bash # 生成12位强密码(需安装openssl) password=$(openssl rand -base64 12 | tr -d '/+=' | cut -c1-12) echo "随机密码: $password" 10. 查找大文件(>100MB) #!/bin/bash # 搜索系统中大于100MB的文件 find / -type f -size +100M -exec ls -lh {} \; 2>/dev/null 11. 同步目录(增量备份) #!/bin/bash # 使用rsync同步目录到远程服务器 rsync -avz --delete /local/path/ user@remote:/remote/path/ 12. 批量杀进程 #!/bin/bash # 强制结束所有匹配进程名的进程 pkill -9 -f "process_name" 13. 统计文件行数 #!/bin/bash # 统计当前目录所有文本文件行数 wc -l *.txt 14. 自动添加定时任务 #!/bin/bash # 每天凌晨3点执行备份脚本 (crontab -l 2>/dev/null; echo "0 3 * * * /path/to/backup.sh") | crontab - echo "定时任务已添加" 15. 检测HTTP服务状态 #!/bin/bash # 检查网站是否返回200状态码 status=$(curl -s -o /dev/null -w "%{http_code}" https://example.com) [ "$status" = "200" ] && echo "服务正常" || echo "服务异常(状态码: $status)" 16. 用户登录审计 #!/bin/bash # 显示最近10条SSH登录记录 last -n 10 | grep -E "pts/" 17. 文件权限修复 #!/bin/bash # 递归修复目录权限(目录755,文件644) find /path/to/fix -type d -exec chmod 755 {} \; find /path/to/fix -type f -exec chmod 644 {} \; echo "权限修复完成" 18. 磁盘IO监控 #!/bin/bash # 检测高磁盘IO进程(需安装iotop) iotop -obn2 | head -n 6 19. 自动配置SSH密钥 #!/bin/bash # 生成密钥并复制到远程主机(需输入密码) ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa ssh-copy-id user@remote_host 20. 交互式菜单 #!/bin/bash # 基础命令行菜单 echo "1. 查看系统信息" echo "2. 显示磁盘使用" echo "3. 退出" read -p "输入选项: " choice case $choice in 1) neofetch ;; 2) df -h ;; 3) exit ;; *) echo "无效选项" ;; esac 使用说明: 将脚本保存为 .sh 文件(例如 script.sh) 添加执行权限:chmod +x script.sh 运行脚本:./script.sh 适用场景: 日常系统维护 自动化任务(备份/监控/清理) 故障排查(网络/磁盘/服务) 批量文件操作 可根据实际需求调整路径、阈值和命令参数。
最常用且实用性最高**的Linux Shell脚本 以下是20个最常用且实用性最高的Linux Shell脚本示例,涵盖系统管理、文件操作和自动化运维场景: 1. 自动备份目录 #!/bin/bash # 压缩备份指定目录到目标路径 backup_dir="/path/to/source" dest_dir="/path/to/backup" tar -czf "${dest_dir}/backup_$(date +%Y%m%d).tar.gz" "$backup_dir" echo "备份已完成:${dest_dir}/backup_$(date +%Y%m%d).tar.gz" 2. 监控CPU和内存使用 #!/bin/bash # 资源使用率告警(阈值可调) cpu_threshold=80 mem_threshold=90 cpu_usage=$(top -bn1 | grep "Cpu(s)" | awk '{print $2}' | cut -d'%' -f1) mem_usage=$(free | grep Mem | awk '{print $3/$2 * 100}' | cut -d'.' -f1) [ "$cpu_usage" -ge "$cpu_threshold" ] && echo "警告:CPU使用率 ${cpu_usage}%" [ "$mem_usage" -ge "$mem_threshold" ] && echo "警告:内存使用率 ${mem_usage}%" 3. 清理旧日志文件 #!/bin/bash # 删除超过30天的日志 find /var/log -name "*.log" -type f -mtime +30 -delete echo "已清理30天前的日志文件" 4. 检查磁盘空间 #!/bin/bash # 检测磁盘使用率超过90%的分区 df -h | awk '{if($5+0 > 90) print "磁盘告警: " $6 " 使用率 " $5}' 5. 批量重命名文件 #!/bin/bash # 将所有.txt文件后缀改为.md for file in *.txt; do mv "$file" "${file%.txt}.md" done echo "批量重命名完成" 6. 网络连通性测试 #!/bin/bash # 测试是否能访问外网和DNS ping -c 2 8.8.8.8 > /dev/null && echo "外网连通正常" || echo "外网连接失败" ping -c 2 example.com > /dev/null && echo "DNS解析正常" || echo "DNS解析失败" 7. 自动更新系统(APT) #!/bin/bash # Debian/Ubuntu系统自动更新 apt update && apt upgrade -y && apt autoclean 8. 服务状态监控 #!/bin/bash # 检查Nginx是否运行,自动重启 if ! systemctl is-active --quiet nginx; then systemctl start nginx echo "Nginx已重启" fi 9. 生成随机密码 #!/bin/bash # 生成12位强密码(需安装openssl) password=$(openssl rand -base64 12 | tr -d '/+=' | cut -c1-12) echo "随机密码: $password" 10. 查找大文件(>100MB) #!/bin/bash # 搜索系统中大于100MB的文件 find / -type f -size +100M -exec ls -lh {} \; 2>/dev/null 11. 同步目录(增量备份) #!/bin/bash # 使用rsync同步目录到远程服务器 rsync -avz --delete /local/path/ user@remote:/remote/path/ 12. 批量杀进程 #!/bin/bash # 强制结束所有匹配进程名的进程 pkill -9 -f "process_name" 13. 统计文件行数 #!/bin/bash # 统计当前目录所有文本文件行数 wc -l *.txt 14. 自动添加定时任务 #!/bin/bash # 每天凌晨3点执行备份脚本 (crontab -l 2>/dev/null; echo "0 3 * * * /path/to/backup.sh") | crontab - echo "定时任务已添加" 15. 检测HTTP服务状态 #!/bin/bash # 检查网站是否返回200状态码 status=$(curl -s -o /dev/null -w "%{http_code}" https://example.com) [ "$status" = "200" ] && echo "服务正常" || echo "服务异常(状态码: $status)" 16. 用户登录审计 #!/bin/bash # 显示最近10条SSH登录记录 last -n 10 | grep -E "pts/" 17. 文件权限修复 #!/bin/bash # 递归修复目录权限(目录755,文件644) find /path/to/fix -type d -exec chmod 755 {} \; find /path/to/fix -type f -exec chmod 644 {} \; echo "权限修复完成" 18. 磁盘IO监控 #!/bin/bash # 检测高磁盘IO进程(需安装iotop) iotop -obn2 | head -n 6 19. 自动配置SSH密钥 #!/bin/bash # 生成密钥并复制到远程主机(需输入密码) ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa ssh-copy-id user@remote_host 20. 交互式菜单 #!/bin/bash # 基础命令行菜单 echo "1. 查看系统信息" echo "2. 显示磁盘使用" echo "3. 退出" read -p "输入选项: " choice case $choice in 1) neofetch ;; 2) df -h ;; 3) exit ;; *) echo "无效选项" ;; esac 使用说明: 将脚本保存为 .sh 文件(例如 script.sh) 添加执行权限:chmod +x script.sh 运行脚本:./script.sh 适用场景: 日常系统维护 自动化任务(备份/监控/清理) 故障排查(网络/磁盘/服务) 批量文件操作 可根据实际需求调整路径、阈值和命令参数。 -
 多Master节点的k8s集群部署 多Master节点的k8s集群部署 一、准备工作 1.准备五台主机(三台Master节点,一台Node节点,一台普通用户)如下: 角色 IP 内存 核心 磁盘 Master01 192.168.116.141 4G 4个 55G Master02 192.168.116.142 4G 4个 55G Master03 192.168.116.143 4G 4个 55G Node 192.168.116.144 4G 4个 55G 普通用户 192.168.116.150 4G 4个 55G 2.关闭SElinux,因为SElinux会影响K8S部分组件无法正常工作: sed -i '1,$s/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config reboot 3.四台主机分别配置主机名(不包括普通用户),如下: 控制节点Master01: hostnamectl set-hostname master01 && bash 控制节点Master02: hostnamectl set-hostname master02 && bash 控制节点Master03: hostnamectl set-hostname master03 && bash 工作节点Node: hostnamectl set-hostname node && bash 4.四台主机(不包括普通用户)分别配置host文件: 进入hosts文件: vim /etc/hosts 修改文件内容,添加四台主机以及IP: 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.116.141 master01 192.168.116.142 master02 192.168.116.143 master03 192.168.116.144 node 修改完可以四台主机用ping命令检查是否连通: ping -c1 -W1 master01 ping -c1 -W1 master02 ping -c1 -W1 master03 ping -c1 -W1 node 5.四台主机(不包括普通用户)分别下载所需意外组件包和相关依赖包: yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip autoconf automake zlib-devel epel-release openssh-server libaio-devel vim ncurses-devel socat conntrack telnet ipvsadm 所需相关意外组件包解释如下: yum-utils:提供了一些辅助工具用于 yum 包管理器,比如 yum-config-manager,repoquery 等。 device-mapper-persistent-data:与 Linux 的设备映射功能相关,通常与 LVM(逻辑卷管理)和容器存储(如 Docker)有关。 lvm2:逻辑卷管理器,用于管理磁盘上的逻辑卷,允许灵活的磁盘分区管理。 wget:一个非交互式网络下载工具,支持 HTTP、HTTPS 和 FTP 协议,常用于下载文件。 net-tools:提供一些经典的网络工具,如 ifconfig,netstat 等,用于查看和管理网络配置。 nfs-utils:支持 NFS(网络文件系统)的工具包,允许客户端挂载远程文件系统。 lrzsz:lrz 和 lsz 是 Linux 系统下用于 X/ZMODEM 文件传输协议的命令行工具,常用于串口传输数据。 gcc:GNU C 编译器,用于编译 C 语言程序。 gcc-c++:GNU C++ 编译器,用于编译 C++ 语言程序。 make:用于构建和编译程序,通常与 Makefile 配合使用,控制程序的编译和打包过程。 cmake:跨平台的构建系统生成工具,用于管理项目的编译过程,特别适用于大型复杂项目。 libxml2-devel:开发用的 libxml2 库头文件,libxml2 是一个用于解析 XML 文件的 C 库。 openssl-devel:用于 OpenSSL 库开发的头文件和开发库,OpenSSL 是用于 SSL/TLS 加密的库。 curl:一个用于传输数据的命令行工具,支持多种协议(HTTP、FTP 等)。 curl-devel:开发用的 curl 库和头文件,支持在代码中使用 curl 相关功能。 unzip:用于解压缩 .zip 文件。 autoconf:自动生成配置脚本的工具,常用于生成软件包的 configure 文件。 automake:自动生成 Makefile.in 文件,结合 autoconf 使用,用于构建系统。 zlib-devel:zlib 库的开发头文件,zlib 是一个用于数据压缩的库。 epel-release:用于启用 EPEL(Extra Packages for Enterprise Linux)存储库,提供大量额外的软件包。 openssh-server:OpenSSH 服务器,用于通过 SSH 远程登录和管理系统。 libaio-devel:异步 I/O 库的开发头文件,提供异步文件 I/O 支持,常用于数据库和高性能应用。 vim:一个强大的文本编辑器,支持多种语言和扩展功能。 ncurses-devel:开发用的 ncurses 库,提供终端控制和用户界面的构建工具。 socat:一个多功能的网络工具,用于双向数据传输,支持多种协议和地址类型。 conntrack:连接跟踪工具,显示和操作内核中的连接跟踪表,常用于网络防火墙和 NAT 配置。 telnet:用于远程登录的一种简单网络协议,允许通过命令行与远程主机进行通信。 ipvsadm:用于管理 IPVS(IP 虚拟服务器),这是一个 Linux 内核中的负载均衡模块,常用于高可用性负载均衡集群。 6.配置主机之间免密登录 四台节点同时执行: 1)配置三台Master主机到另外一台Node主机免密登录: ssh-keygen # 遇到问题不输入任何内容,直按回车 2)把刚刚生成的公钥文件传递到其他Master和node节点,输入yes后,在输入主机对应的密码: ssh-copy-id master01 ssh-copy-id master02 ssh-copy-id master03 ssh-copy-id node 7.关闭所有主机的firewall防火墙 如果不想关闭防火墙可以添加firewall-cmd规则进行过滤筛选,相关内容查询资料,不做演示。 关闭防火墙: systemctl stop firewalld && systemctl disable firewalld systemctl status firewalld # 查询防火墙状态,关闭后应为 Active: inactive (dead) 添加防火墙规则: 6443:Kubernetes Api Server 2379、2380:Etcd数据库 10250、10255:kubelet服务 10257:kube-controller-manager 服务 10259:kube-scheduler 服务 30000-32767:在物理机映射的 NodePort端口 179、473、4789、9099:Calico 服务 9090、3000:Prometheus监控+Grafana面板 8443:Kubernetes Dashboard控制面板 # Kubernetes API Server firewall-cmd --zone=public --add-port=6443/tcp --permanent # Etcd 数据库 firewall-cmd --zone=public --add-port=2379-2380/tcp --permanent # Kubelet 服务 firewall-cmd --zone=public --add-port=10250/tcp --permanent firewall-cmd --zone=public --add-port=10255/tcp --permanent # Kube-Controller-Manager 服务 firewall-cmd --zone=public --add-port=10257/tcp --permanent # Kube-Scheduler 服务 firewall-cmd --zone=public --add-port=10259/tcp --permanent # NodePort 映射端口 firewall-cmd --zone=public --add-port=30000-32767/tcp --permanent # Calico 服务 firewall-cmd --zone=public --add-port=179/tcp --permanent # BGP firewall-cmd --zone=public --add-port=473/tcp --permanent # IP-in-IP firewall-cmd --zone=public --add-port=4789/udp --permanent # VXLAN firewall-cmd --zone=public --add-port=9099/tcp --permanent # Calico 服务 #Prometheus监控+Grafana面板 firewall-cmd --zone=public --add-port=9090/tcp --permanent firewall-cmd --zone=public --add-port=3000/tcp --permanent # Kubernetes Dashboard控制面板 firewall-cmd --zone=public --add-port=8443/tcp --permanent # 重新加载防火墙配置以应用更改 firewall-cmd --reload 8.四台主机关闭swap交换分区 swap 分区的读写速度远低于物理内存。如果 Kubernetes 工作负载依赖于 swap 来补偿内存不足,会导致性能显著下降,尤其是在资源密集型的容器应用中。Kubernetes 更倾向于让节点直接面临内存不足的情况,而不是依赖 swap,从而促使调度器重新分配资源。 Kubernetes 默认会在 kubelet 启动时检查 swap 的状态,并要求其关闭。如果 swap 未关闭,Kubernetes 可能无法正常启动并报出错误。例如: [!WARNING] kubelet: Swap is enabled; production deployments should disable swap. 为了让 Kubernetes 正常工作,建议在所有节点上永久关闭 swap,同时调整系统的内存管理: swapoff -a # 关闭当前swap sed -i '/swap/s/^/#/' /etc/fstab # swap前添加注释 grep swap /etc/fstab # 成功关闭会这样:#/dev/mapper/rl-swap none swap defaults 0 0 9.修改内核参数 四台主机(不包括普通用户)分别执行: modprobe br_netfilter modprobe:用于加载或卸载内核模块的命令。 br_netfilter:该模块允许桥接的网络流量被 iptables 规则过滤,通常在启用网络桥接的情况下使用。 该模块主要在 Kubernetes 容器网络环境中使用,确保 Linux 内核能够正确处理网络流量的过滤和转发,特别是在容器间的通信中。 四台主机分别执行: cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf # 使配置生效 net.bridge.bridge-nf-call-ip6tables = 1:允许 IPv6 网络流量通过 Linux 网络桥接时使用 ip6tables 进行过滤。 net.bridge.bridge-nf-call-iptables = 1:允许 IPv4 网络流量通过 Linux 网络桥接时使用 iptables 进行过滤。 net.ipv4.ip_forward = 1:允许 Linux 内核进行 IPv4 数据包的转发(路由)。 这些设置确保在 Kubernetes 中,网络桥接流量可通过 iptables 和 ip6tables 过滤,并启用 IPv4 数据包转发,提升网络安全性和通信能力。 10.配置安装Docker和Containerd的yum源 四台主机分别安装docker-ce源(任选其一,只安装一个),后续操作只演示阿里源的。 # 阿里源 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 清华大学开源软件镜像站 yum-config-manager --add-repo https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo # 中国科技大学开源镜像站 yum-config-manager --add-repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo # 中科大镜像源 yum-config-manager --add-repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo # 华为云源 yum-config-manager --add-repo https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo 11.配置K8S命令行工具所需要的yum源 cat > /etc/yum.repos.d/kubernetes.repo <<EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF yum makecache 12.四台主机进行时间同步 Chrony 和 NTPD都是用于时间同步的工具,但 Chrony 在许多方面有其独特的优点。以下是 Chrony 相较于 NTPD 的一些主要优点,并基于此,进行chrony时间同步的部署: 1) 四台主机安装Chrony yum -y install chrony 2)四台主机修改配置文件,添加国内 NTP 服务器 echo "server ntp1.aliyun.com iburst" >> /etc/chrony.conf echo "server ntp2.aliyun.com iburst" >> /etc/chrony.conf echo "server ntp3.aliyun.com iburst" >> /etc/chrony.conf echo "server ntp.tuna.tsinghua.edu.cn iburst" >> /etc/chrony.conf tail -n 4 /etc/chrony.conf systemctl restart chronyd 3) 可以设置定时任务,每分钟重启chrony服务,进行时间校准(非必须) echo "* * * * * /usr/bin/systemctl restart chronyd" | tee -a /var/spool/cron/root 建议手动进行添加,首先执行crontab -e命令,在将如下内容添加至定时任务中 * * * * * /usr/bin/systemctl restart chronyd 这五个星号表示时间调度,每个星号代表一个时间字段,从左到右分别是: 第一个星号:分钟(0-59) 第二个星号:小时(0-23) 第三个星号:日期(1-31) 第四个星号:月份(1-12) 第五个星号:星期几(0-7,0 和 7 都代表星期天) 在这里,每个字段都用 表示“每一个”,因此 的意思是“每分钟的每一秒”。 /usr/bin/systemctl 是 systemctl 命令的完整路径,用于管理系统服务。 13.安装Containerd Containerd 是一个高性能的容器运行时,在 Kubernetes 中它负责容器的生命周期管理,包括创建、运行、停止和删除容器,同时支持从镜像仓库拉取和管理镜像。Containerd 提供容器运行时接口 (CRI),与 Kubernetes 无缝集成,确保高效的资源利用和快速的容器启动时间。除此之外,它还支持事件监控和日志记录,方便运维和调试,是实现容器编排和管理的关键组件。 四台主机安装containerd1.6.22版本 yum -y install containerd.io-1.6.22 yum -y install containerd.io-1.6.22 --allowerasing # 如果安装有问题选择这个,默认用第一个 创建containerd的配置文件目录并修改自带的config.toml。 mkdir -pv /etc/containerd vim /etc/containerd/config.toml 修改内容如下: disabled_plugins = [] imports = [] oom_score = 0 plugin_dir = "" required_plugins = [] root = "/var/lib/containerd" state = "/run/containerd" temp = "" version = 2 [cgroup] path = "" [debug] address = "" format = "" gid = 0 level = "" uid = 0 [grpc] address = "/run/containerd/containerd.sock" gid = 0 max_recv_message_size = 16777216 max_send_message_size = 16777216 tcp_address = "" tcp_tls_ca = "" tcp_tls_cert = "" tcp_tls_key = "" uid = 0 [metrics] address = "" grpc_histogram = false [plugins] [plugins."io.containerd.gc.v1.scheduler"] deletion_threshold = 0 mutation_threshold = 100 pause_threshold = 0.02 schedule_delay = "0s" startup_delay = "100ms" [plugins."io.containerd.grpc.v1.cri"] device_ownership_from_security_context = false disable_apparmor = false disable_cgroup = false disable_hugetlb_controller = true disable_proc_mount = false disable_tcp_service = true enable_selinux = false enable_tls_streaming = false enable_unprivileged_icmp = false enable_unprivileged_ports = false ignore_image_defined_volumes = false max_concurrent_downloads = 3 max_container_log_line_size = 16384 netns_mounts_under_state_dir = false restrict_oom_score_adj = false sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9" selinux_category_range = 1024 stats_collect_period = 10 stream_idle_timeout = "4h0m0s" stream_server_address = "127.0.0.1" stream_server_port = "0" systemd_cgroup = false tolerate_missing_hugetlb_controller = true unset_seccomp_profile = "" [plugins."io.containerd.grpc.v1.cri".cni] bin_dir = "/opt/cni/bin" conf_dir = "/etc/cni/net.d" conf_template = "" ip_pref = "" max_conf_num = 1 [plugins."io.containerd.grpc.v1.cri".containerd] default_runtime_name = "runc" disable_snapshot_annotations = true discard_unpacked_layers = false ignore_rdt_not_enabled_errors = false no_pivot = false snapshotter = "overlayfs" [plugins."io.containerd.grpc.v1.cri".containerd.default_runtime] base_runtime_spec = "" cni_conf_dir = "" cni_max_conf_num = 0 container_annotations = [] pod_annotations = [] privileged_without_host_devices = false runtime_engine = "" runtime_path = "" runtime_root = "" runtime_type = "" [plugins."io.containerd.grpc.v1.cri".containerd.default_runtime.options] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] base_runtime_spec = "" cni_conf_dir = "" cni_max_conf_num = 0 container_annotations = [] pod_annotations = [] privileged_without_host_devices = false runtime_engine = "" runtime_path = "" runtime_root = "" runtime_type = "io.containerd.runc.v2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] BinaryName = "" CriuImagePath = "" CriuPath = "" CriuWorkPath = "" IoGid = 0 IoUid = 0 NoNewKeyring = false NoPivotRoot = false Root = "" ShimCgroup = "" SystemdCgroup = true [plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime] base_runtime_spec = "" cni_conf_dir = "" cni_max_conf_num = 0 container_annotations = [] pod_annotations = [] privileged_without_host_devices = false runtime_engine = "" runtime_path = "" runtime_root = "" runtime_type = "" [plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime.options] [plugins."io.containerd.grpc.v1.cri".image_decryption] key_model = "node" [plugins."io.containerd.grpc.v1.cri".registry] config_path = "" [plugins."io.containerd.grpc.v1.cri".registry.auths] [plugins."io.containerd.grpc.v1.cri".registry.configs] [plugins."io.containerd.grpc.v1.cri".registry.headers] [plugins."io.containerd.grpc.v1.cri".registry.mirrors] [plugins."io.containerd.grpc.v1.cri".x509_key_pair_streaming] tls_cert_file = "" tls_key_file = "" [plugins."io.containerd.internal.v1.opt"] path = "/opt/containerd" [plugins."io.containerd.internal.v1.restart"] interval = "10s" [plugins."io.containerd.internal.v1.tracing"] sampling_ratio = 1.0 service_name = "containerd" [plugins."io.containerd.metadata.v1.bolt"] content_sharing_policy = "shared" [plugins."io.containerd.monitor.v1.cgroups"] no_prometheus = false [plugins."io.containerd.runtime.v1.linux"] no_shim = false runtime = "runc" runtime_root = "" shim = "containerd-shim" shim_debug = false [plugins."io.containerd.runtime.v2.task"] platforms = ["linux/amd64"] sched_core = false [plugins."io.containerd.service.v1.diff-service"] default = ["walking"] [plugins."io.containerd.service.v1.tasks-service"] rdt_config_file = "" [plugins."io.containerd.snapshotter.v1.aufs"] root_path = "" [plugins."io.containerd.snapshotter.v1.btrfs"] root_path = "" [plugins."io.containerd.snapshotter.v1.devmapper"] async_remove = false base_image_size = "" discard_blocks = false fs_options = "" fs_type = "" pool_name = "" root_path = "" [plugins."io.containerd.snapshotter.v1.native"] root_path = "" [plugins."io.containerd.snapshotter.v1.overlayfs"] root_path = "" upperdir_label = false [plugins."io.containerd.snapshotter.v1.zfs"] root_path = "" [plugins."io.containerd.tracing.processor.v1.otlp"] endpoint = "" insecure = false protocol = "" [proxy_plugins] [stream_processors] [stream_processors."io.containerd.ocicrypt.decoder.v1.tar"] accepts = ["application/vnd.oci.image.layer.v1.tar+encrypted"] args = ["--decryption-keys-path", "/etc/containerd/ocicrypt/keys"] env = ["OCICRYPT_KEYPROVIDER_CONFIG=/etc/containerd/ocicrypt/ocicrypt_keyprovider.conf"] path = "ctd-decoder" returns = "application/vnd.oci.image.layer.v1.tar" [stream_processors."io.containerd.ocicrypt.decoder.v1.tar.gzip"] accepts = ["application/vnd.oci.image.layer.v1.tar+gzip+encrypted"] args = ["--decryption-keys-path", "/etc/containerd/ocicrypt/keys"] env = ["OCICRYPT_KEYPROVIDER_CONFIG=/etc/containerd/ocicrypt/ocicrypt_keyprovider.conf"] path = "ctd-decoder" returns = "application/vnd.oci.image.layer.v1.tar+gzip" [timeouts] "io.containerd.timeout.bolt.open" = "0s" "io.containerd.timeout.shim.cleanup" = "5s" "io.containerd.timeout.shim.load" = "5s" "io.containerd.timeout.shim.shutdown" = "3s" "io.containerd.timeout.task.state" = "2s" [ttrpc] address = "" gid = 0 uid = 0 sandbox 镜像源:设置 Kubernetes 使用的沙箱容器镜像,支持高效管理容器。 sandbox_image = “registry.aliyuncs.com/google_containers/pause:3.9” hugeTLB 控制器:禁用 hugeTLB 控制器,减少内存管理复杂性,适合不需要的环境。 disable_hugetlb_controller = true 网络插件路径:指定 CNI 网络插件的二进制和配置路径,确保网络功能正常。 bin_dir = “/opt/cni/bin” conf_dir = “/etc/cni/net.d” 垃圾回收调度器:调整垃圾回收阈值和启动延迟,优化容器资源管理和性能。 pause_threshold = 0.02 startup_delay = “100ms” 流媒体服务器:配置流媒体服务的地址和端口,实现与客户端的有效数据传输。 stream_server_address = “127.0.0.1” stream_server_port = “0” 启动并设置containerd开机自启 systemctl enable containerd --now systemctl status containerd 14.安装Docker-ce(使用docker的拉镜像功能) 1)四台主机分别安装docker-ce最新版: yum -y install docker-ce 2)启动并设置docker开机自启: systemctl start docker && systemctl enable docker.service 3)配置docker的镜像加速器地址: 注:阿里加速地址登录阿里云加速器官网查看,每个人的加速地址不同 tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": [ "https://fb3aq27p.mirror.aliyuncs.com", "https://registry.docker-cn.com", "https://docker.mirrors.ustc.edu.cn", "https://dockerhub.azk8s.cn", "http://hub-mirror.c.163.com" ] } EOF systemctl daemon-reload systemctl restart docker systemctl status docker 二、K8S安装部署 1.安装K8S相关核心组件 四台主机分别安装K8S相关核心组件: yum -y install kubelet-1.28.2 kubeadm-1.28.2 kubectl-1.28.2 systemctl enable kubelet kubelet 是 Kubernetes 集群中每个节点上的核心代理,它负责根据控制平面的指示管理和维护节点上的 Pod 及容器的生命周期,确保容器按规范运行并定期与控制平面通信。kubelet 会将节点和 Pod 的状态上报给控制节点的 apiServer,apiServer再将这些信息存储到 etcd 数据库中。 kubeadm 是一个用于简化 Kubernetes 集群安装和管理的工具,快速初始化控制平面节点和将工作节点加入集群,减少手动配置的复杂性。 kubectl 是 Kubernetes 的命令行工具,用于管理员与集群进行交互,执行各种任务,如部署应用、查看资源、排查问题、管理集群状态等,通过命令行与 Kubernetes API 直接通信。 2.通过keepalived+nginx实现kubernetes apiServer的节点高可用 1)在三台Master节点分别安装keepalived+nginx,实现对apiserver的负载均衡和反向代理。Master01作为keepalived的主节点,Master02和Master03作为keepalived的备用节点。 yum -y install epel-release nginx keepalived nginx-mod-stream 2)修改配置nginx.conf配置文件: vim /etc/nginx/nginx.conf 3)更改配置配置文件完整信息如下: user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } 新增 stream 配置 stream { # 日志格式 log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent'; # 日志存放路径 access_log /var/log/nginx/k8s-access.log main; # master 调度资源池 upstream k8s-apiserver { server 192.168.116.141:6443 weight=5 max_fails=3 fail_timeout=30s; server 192.168.116.142:6443 weight=5 max_fails=3 fail_timeout=30s; server 192.168.116.143:6443 weight=5 max_fails=3 fail_timeout=30s; } server { listen 16443; # 避免与 Kubernetes master 节点冲突 proxy_pass k8s-apiserver; # 做反向代理到资源池 } } http { include /etc/nginx/mime.types; default_type application/octet-stream; # 日志格式 log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf; } stream模块用于四层负载均衡,转发到多个k8s-apiserver节点。 四层负载均衡工作在传输层,仅关注 TCP/UDP 连接的信息,例如源IP地址、端口、目标IP地址和端口,基于这些信息进行流量转发,不关心传输的数据内容。 七层负载均衡工作在应用层,理解更高层的协议(如 HTTP、HTTPS),根据请求的具体内容(例如URL、Cookies、Headers)进行更复杂的流量分配和处理。 log_format和access_log用于记录日志。 upstream定义了多个k8s-apiserver服务器,负载均衡策略基于权重weight,并有故障处理机制。 server块中,listen使用端口16443,以避免与Kubernetes master节点的默认端口6443冲突。 4)重启nginx并设置开机自启: systemctl restart nginx && systemctl enable nginx 5)先编写keepalived的检查脚本: 注:将这个脚本分别放到三台Master节点上,建议放在/etc/keepalived/目录,方便后续进行优化更新。 #!/bin/bash Author :lyx Description :check nginx Date :2024.10.06 Version :2.3 # 定义日志文件路径 ```python LOG_FILE="/var/log/nginx_keepalived_check.log" MAX_LINES=1000 # 设置日志保留1000行(因为不做限制日志会无限增大,占用大量磁盘空间) 记录日志的函数,带有详细的时间格式,并保留最后1000行日志 log_message() { local time_stamp=$(date '+%Y-%m-%d %H:%M:%S') # 定义时间格式 echo "$time_stamp - $1" >> $LOG_FILE # 截取日志文件,只保留最后1000行 tail -n $MAX_LINES $LOG_FILE > ${LOG_FILE}.tmp && mv ${LOG_FILE}.tmp $LOG_FILE } 检测 Nginx 是否在运行的函数 check_nginx() { pgrep -f "nginx: master" > /dev/null 2>&1 echo $? } 1. 检查 Nginx 是否存活 log_message "正在检查 Nginx 状态..." if [ $(check_nginx) -ne 0 ]; then log_message "Nginx 未运行,尝试启动 Nginx..." # 2. 如果 Nginx 不在运行,则尝试启动 systemctl start nginx sleep 2 # 等待 Nginx 启动 # 3. 再次检查 Nginx 状态 log_message "启动 Nginx 后再次检查状态..." if [ $(check_nginx) -ne 0 ]; then log_message "Nginx 启动失败,停止 Keepalived 服务..." # 4. 如果 Nginx 启动失败,停止 Keepalived systemctl stop keepalived else log_message "Nginx 启动成功。" fi else log_message "Nginx 正常运行。" fi 若nginx出现问题会打印中文日志到:/var/log/nginx_keepalived_check.log , 可以手动进行查看输出的日志消息,再根据对应故障的具体时间,结合nginx的日志来进行修复或者优化。 分别授予脚本可执行权限: chmod +x /etc/keepalived/keepalived_nginx_check.sh 这个脚本的主要作用是监控 Nginx 服务的运行状态,并在检测到 Nginx 停止运行时,尝试重启它。如果重启失败,脚本会停止 Keepalived 服务,避免继续提供不可用的服务。 监控 Nginx 状态:脚本定期检查 Nginx 是否正常运行,使用 pgrep 命令检测主进程状态。 自动修复机制:如果 Nginx 未运行,尝试重启服务,并再次检测其状态;若重启成功,记录日志。 停止 Keepalived:如果 Nginx 无法启动,停止 Keepalived 服务,防止服务器继续作为故障节点运行。 6)修改keepalived主节点Master01的配置文件: global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 # 用来发送、接收和中转电子邮件的服务器 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_script keepalived_nginx_check { # 这里是上一步骤添加的脚本,在这里进行调用 script "/etc/keepalived/keepalived_nginx_check.sh" # 根据自己添加的脚本路径进行修改,建议还是放在这个目录下便于管理 } vrrp_instance VI_1 { state MASTER # 主修改state为MASTER,备修改为BACKUP interface ens160 # 修改自己的实际网卡名称 virtual_router_id 51 # 主备的虚拟路由ID要相同 priority 100 # 优先级,备服务器设置优先级比主服务器的优先级低一些 advert_int 1 # 广播包发送间隔时间为1秒 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.116.16/24 # 虚拟IP修改为没有占用的IP地址,主备的虚拟IP相同就好 } track_script { keepalived_nginx_check # vrrp_script 定义的脚本名,放到这里进行追踪调用,Keepalived 可以根据脚本返回的结果做出相应的动作 } 7)修改keepalived备份节点Master02的配置文件: global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 # 用来发送、接收和中转电子邮件的服务器 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_script keepalived_nginx_check { # 这里是上一步骤添加的脚本,在这里进行调用 script "/etc/keepalived/keepalived_nginx_check.sh" # 根据自己添加的脚本路径进行修改,建议还是放在这个目录下便于管理 } vrrp_instance VI_1 { state BACKUP # 主修改state为MASTER,备修改为BACKUP interface ens160 # 修改自己的实际网卡名称 virtual_router_id 51 # 主备的虚拟路由ID要相同 priority 90 # 优先级,备服务器设置优先级比主服务器的优先级低一些 advert_int 1 # 广播包发送间隔时间为1秒 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.116.16/24 # 虚拟IP修改为没有占用的IP地址,主备的虚拟IP相同就好 } track_script { keepalived_nginx_check # vrrp_script 定义的脚本名,放到这里进行追踪调用,Keepalived 可以根据脚本返回的结果做出相应的动作 } } 7)修改keepalived备份节点Master03的配置文件: global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 # 用来发送、接收和中转电子邮件的服务器 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_script keepalived_nginx_check { # 这里是上一步骤添加的脚本,在这里进行调用 script "/etc/keepalived/keepalived_nginx_check.sh" # 根据自己添加的脚本路径进行修改,建议还是放在这个目录下便于管理 } vrrp_instance VI_1 { state BACKUP # 主修改state为MASTER,备修改为BACKUP interface ens160 # 修改自己的实际网卡名称 virtual_router_id 51 # 主备的虚拟路由ID要相同 priority 80 # 优先级,备服务器设置优先级比主服务器的优先级低一些 advert_int 1 # 广播包发送间隔时间为1秒 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.116.16/24 # 虚拟IP修改为没有占用的IP地址,主备的虚拟IP相同就好 } track_script { keepalived_nginx_check # vrrp_script 定义的脚本名,放到这里进行追踪调用,Keepalived 可以根据脚本返回的结果做出相应的动作 } } 三台节点主要的修改内容为这三部分: state MASTER / BACKUP interface ens160 priority 100 / 90 / 80 8)重载配置文件并重启nginx+keepalived服务: systemctl daemon-reload && systemctl restart nginx systemctl restart keepalived && systemctl enable keepalived 9)检查虚拟IP是否绑定成功: ip address show | grep 192.168.116.16 # 根据你们自己设置的虚拟IP来检查 如果成功绑定会有如下信息: [!IMPORTANT] inet 192.168.116.16/24 scope global secondary ens160 10)检查keepalived漂移是否设置成功(keepalived_nginx_check.sh脚本是否生效) (1)在keepalived的主节点Master01关闭keepalived服务: systemctl stop keepalived (2)切换到keepalived的备节点Master01查看网卡信息 ip address show | grep 192.168.116.16 # 根据你们自己设置的虚拟IP来检查 若出现如下提示,即为漂移成功: [!IMPORTANT] inet 192.168.116.16/24 scope global secondary ens160 注:如果主keepalived不异常的情况下,在两个备节点是无法查看到192.168.116.16虚拟IP的。 3.初始化K8S集群 1)Master01节点分别使用kubeadm初始化K8S集群: 注:kubeadm安装K8S,控制节点和工作节点的组件都是基于Pod运行的。 kubeadm config print init-defaults > kubeadm.yaml 生成默认的配置文件重定向输出到 kubeadm.yaml 中 2)修改刚刚用kubeadm生成的kubeadm.yaml文件: sed -i '/localAPIEndpoint/s/^/#/' kubeadm.yaml sed -i '/advertiseAddress/s/^/#/' kubeadm.yaml sed -i '/bindPort/s/^/#/' kubeadm.yaml sed -i '/name: node/s/^/#/' kubeadm.yaml sed -i "s|criSocket:.*|criSocket: unix://$(find / -name containerd.sock | head -n 1)|" kubeadm.yaml sed -i 's|imageRepository: registry.k8s.io|imageRepository: registry.aliyuncs.com/google_containers|' kubeadm.yaml # 原配置为国外的k8s源,为了加速镜像的下载,需改成国内源 sed -i '/serviceSubnet/a\ podSubnet: 10.244.0.0/12' kubeadm.yaml # /a\ 表示在serviceSubnet行下方一行内容 cat <<EOF >> kubeadm.yaml --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs --- apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd EOF more kubeadm.yaml # 手动检查一下 advertiseAddress 是 Kubernetes 控制节点的广告地址,其他节点通过这个地址与控制平面节点通信。它通常是控制节点所在服务器的 IP 地址,为了确保控制平面节点能在网络中通过正确的控制节点 IP 地址(我的MasterIP为:192.168.116.131)进行通信。 criSocket 指定的是 Kubernetes 使用的容器运行时(CRI)套接字地址,K8S 使用这个套接字与容器运行时(如 containerd)进行通信,来管理和启动容器。为了确保 K8S使用正确的容器运行时套接字。通过 find 命令查找 containerd.sock 文件路径并替换进配置文件,可以保证路径的准确性,避免手动查找和配置错误。 IPVS 模式支持更多的负载均衡算法,性能更好,尤其在集群节点和服务较多的情况下,可以显著提升网络转发效率和稳定性(如果没有指定mode为ipvs,则默认选定iptables,iptables性能相对较差)。 统一使用 systemd 作为容器和系统服务的 cgroup 驱动,避免使用 cgroupfs 时可能产生的资源管理不一致问题,提升 Kubernetes 和宿主机系统的兼容性和稳定性。 注:主机 IP、Pod IP 和 Service IP 不能在同一网段,因会导致 IP 冲突、路由混乱及网络隔离失败,影响 Kubernetes 的正常通信和网络安全。 3)基于kubeadm.yaml 文件初始化K8S,Master01节点拉取 Kubernetes 1.28.0 所需的镜像(两个方法可以二选一): (1)使用使用 kubeadm 命令,快速拉取 Kubernetes 所有核心组件的镜像,并确保版本一致。 kubeadm config images pull --image-repository="registry.aliyuncs.com/google_containers" --kubernetes-version=v1.28.0 (2)使用 ctr 命令,需要更细粒度的控制,或在 kubeadm 拉取镜像过程中出现问题时,可以使用 ctr 命令手动拉取镜像。 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.28.0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.28.0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/kube-proxy:v1.28.0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/pause:3.9 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/etcd:3.5.9-0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/coredns:v1.10.1 4)在Master控制节点,初始化 Kubernetes 主节点 kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerification 个别操作系统可能会出现kubelet启动失败的情况,如下提示,如果提示successfully则忽略以下步骤: [!WARNING] dial tcp [::1]:10248: connect: connection refused 执行systemctl status kubelet发现出现以下错误提示: [!WARNING] Process: 2226953 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=1/FAILURE) Main PID: 2226953 (code=exited, status=1/FAILURE) 解决方法如下,控制节点执行: sed -i 's|ExecStart=/usr/bin/kubelet|ExecStart=/usr/bin/kubelet --container-runtime-endpoint=unix://$(find / -name containerd.sock | head -n 1) --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml|' /usr/lib/systemd/system/kubelet.service systemctl daemon-reload systemctl restart kubelet kubeadm reset # 删除安装出错的K8S kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerification # 重新安装 3.设置 Kubernetes 的配置文件,以便让当前用户能够使用 kubectl 命令与 Kubernetes 集群进行交互 控制节点Master01执行: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config 4.扩容k8s控制节点,将Master01和Master02加入到k8s集群 1)Master02和Master03创建证书存放目录: mkdir -pv /etc/kubernetes/pki/etcd && mkdir -pv ~/.kube/ 2)远程拷贝证书文件到Master02: scp /etc/kubernetes/pki/ca.crt root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/ca.key root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.key root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.pub root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.crt root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.key root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/etcd/ca.crt root@192.168.116.142:/etc/kubernetes/pki/etcd/ scp /etc/kubernetes/pki/etcd/ca.key root@192.168.116.142:/etc/kubernetes/pki/etcd/ 3)远程拷贝证书文件到Master03: scp /etc/kubernetes/pki/ca.crt root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/ca.key root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.key root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.pub root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.crt root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.key root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/etcd/ca.crt root@192.168.116.143:/etc/kubernetes/pki/etcd/ scp /etc/kubernetes/pki/etcd/ca.key root@192.168.116.143:/etc/kubernetes/pki/etcd/ 4)控制节点Master01生成集群token: kubeadm token create --print-join-command 生成token如下: [!IMPORTANT] kubeadm join 192.168.116.141:6443 --token pb1pk7.6p6w2jl1gjvlmmdz --discovery-token-ca-cert-hash sha256:b3b9de172cf6c48d97396621858a666e0be2d2d5578e4ce0fba5f1739b735fc1 如果控制节点加入集群需要在生成的token后加入 --control-plane ,如下: kubeadm join 192.168.116.141:6443 --token pb1pk7.6p6w2jl1gjvlmmdz --discovery-token-ca-cert-hash sha256:b3b9de172cf6c48d97396621858a666e0be2d2d5578e4ce0fba5f1739b735fc1 --control-plane 控制节点加入集群后执行如下命令,即可使用kubectl命令工作: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config 如果工作节点加入集群,直接复制生成的这行命令到node主机执行即可: kubeadm join 192.168.116.141:6443 --token pb1pk7.6p6w2jl1gjvlmmdz --discovery-token-ca-cert-hash sha256:b3b9de172cf6c48d97396621858a666e0be2d2d5578e4ce0fba5f1739b735fc1 工作节点加入集群后,设置一个用户的 kubectl 环境,使其能够与 Kubernetes 集群进行交互:: mkdir ~/.kube cp /etc/kubernetes/kubelet.conf ~/.kube/config 注意:如果扩容节点时,有以下报错: [!CAUTION] [preflight] Reading configuration from the cluster… [preflight] FYI: You can look at this config file with ‘kubectl -n kube-system get cm kubeadm-config -o yaml’ error execution phase preflight: One or more conditions for hosting a new control plane instance is not satisfied. unable to add a new control plane instance a cluster that doesn’t have a stable controlPlaneEndpoint address Please ensure that: The cluster has a stable controlPlaneEndpoint address. The certificates that must be shared among control plane instances are provided. To see the stack trace of this error execute with --v=5 or higher 解决方法为添加 controlPlaneEndpoint: kubectl -n kube-system edit cm kubeadm-config 添加如下 controlPlaneEndpoint: 192.168.116.141:6443 (Master01的IP地址) 即可解决: kind: ClusterConfiguration kubernetesVersion: v1.18.0 controlPlaneEndpoint: 192.168.116.141:6443 重新复制生成的这行命令到node主机执行(控制节点需要添加 --control-plane),提示为如下内容则为成功扩容: To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster. 5.安装k8s网络组件Calico Calico 是一个流行的开源网络解决方案,专为 Kubernetes 提供高效、可扩展和安全的网络连接。它采用了基于 IP 的网络模型,使每个 Pod 都能获得一个唯一的 IP 地址,从而简化了网络管理。Calico 支持多种网络策略,可以实现细粒度的流量控制和安全策略,例如基于标签的访问控制,允许用户定义哪些 Pod 可以相互通信。(简单来说就是给Pod和Service分IP的,还能通过网络策略做网络隔离) 1)四台主机分别安装calico: ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/cni:v3.25.0 ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/pod2daemon-flexvol:v3.25.0 ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/node:v3.25.0 ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/kube-controllers:v3.25.0 ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/typha:v3.25.0 2) 控制节点下载calico3.25.0的yaml配置文件(下载失败把URL复制到浏览器,手动复制粘贴内容到Master01节点效果相同) curl -O -L https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/calico.yaml 3)编辑calico.yaml,找到CLUSTER_TYPE行,在下面添加一对键值对,确保使用网卡接口(注意缩进): 原配置: - name: CLUSTER_TYPE value: "k8s,bgp" 新配置: - name: CLUSTER_TYPE value: "k8s,bgp" - name: IP_AUTODELECTION_METHOD value: "interface=ens160" 注:不同操作系统的网卡名称有差异,例:centos7.9的网卡名称为ens33,就要填写value: “interface=ens33”,需灵活变通。 注:如果出现calico拉取镜像错误问题,可能是没有修改imagePullPresent规则,可以修改官方源下载为华为源下载,如下: sed -i '1,$s|docker.io/calico/cni:v3.25.0|swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/cni:v3.25.0|g' calico.yaml sed -i '1,$s|docker.io/calico/node:v3.25.0|swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/node:v3.25.0|g' calico.yaml sed -i '1,$s|docker.io/calico/kube-controllers:v3.25.0|swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/kube-controllers:v3.25.0|g' calico.yaml 4)部署calico网络服务 kubectl apply -f calico.yaml 查看在 Kubernetes 集群中查看属于 kube-system 命名空间的所有 Pod 的详细信息(控制节点和工作节点都查的到): kubectl get pod --namespace kube-system -o wide calico安装成功的信息大概如下: [!IMPORTANT] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-665548954f-5dgjw 1/1 Running 0 3m3s 10.255.112.131 master01 calico-node-4gb27 1/1 Running 0 3m3s 192.168.116.142 master02 calico-node-4kckd 1/1 Running 0 3m3s 192.168.116.144 node calico-node-cpnwp 1/1 Running 0 3m3s 192.168.116.141 master01 calico-node-hldt2 1/1 Running 0 3m3s 192.168.116.143 master03 coredns-66f779496c-8pzvp 1/1 Running 0 61m 10.255.112.129 master01 coredns-66f779496c-frsvq 1/1 Running 0 61m 10.255.112.130 master01 etcd-master01 1/1 Running 0 61m 192.168.116.141 master01 etcd-master02 1/1 Running 0 21m 192.168.116.142 master02 etcd-master03 1/1 Running 0 20m 192.168.116.143 master03 kube-apiserver-master01 1/1 Running 0 61m 192.168.116.141 master01 kube-apiserver-master02 1/1 Running 0 22m 192.168.116.142 master02 kube-apiserver-master03 1/1 Running 1 (21m ago) 19m 192.168.116.143 master03 kube-controller-manager-master01 1/1 Running 1 (21m ago) 61m 192.168.116.141 master01 kube-controller-manager-master02 1/1 Running 0 22m 192.168.116.142 master02 kube-controller-manager-master03 1/1 Running 0 20m 192.168.116.143 master03 kube-proxy-jvt6w 1/1 Running 0 31m 192.168.116.144 node kube-proxy-lw8g4 1/1 Running 0 61m 192.168.116.141 master01 kube-proxy-mjw8h 1/1 Running 0 22m 192.168.116.142 master02 kube-proxy-rtlpz 1/1 Running 0 21m 192.168.116.143 master03 kube-scheduler-master01 1/1 Running 1 (21m ago) 61m 192.168.116.141 master01 kube-scheduler-master02 1/1 Running 0 22m 192.168.116.142 master02 kube-scheduler-master03 1/1 Running 0 19m 192.168.116.143 master03 6.配置Etcd的高可用 Etcd默认的yaml文件–initial-cluster只指定自己,所以需要修改为指定我们的三台Master节点主机: Master01节点 sed -i 's|--initial-cluster=master01=https://192.168.116.141:2380|--initial-cluster=master01=https://192.168.116.141:2380,master02=https://192.168.116.142:2380,master03=https://192.168.116.143:2380|' /etc/kubernetes/manifests/etcd.yaml Master02节点 sed -i 's|--initial-cluster=master01=https://192.168.116.141:2380|--initial-cluster=master01=https://192.168.116.142:2380,master02=https://192.168.116.142:2380,master03=https://192.168.116.143:2380|' /etc/kubernetes/manifests/etcd.yaml Master03节点 sed -i 's|--initial-cluster=master01=https://192.168.116.141:2380|--initial-cluster=master01=https://192.168.116.143:2380,master02=https://192.168.116.142:2380,master03=https://192.168.116.143:2380|' /etc/kubernetes/manifests/etcd.yaml 修改的目的是在 Kubernetes 高可用(HA)集群 中为 etcd 集群 提供节点的初始集群信息。简单来说就是,--initial-cluster 的配置作用是告诉 etcd 节点关于集群中的其他成员信息,这样它们可以相互通信、保持一致并提供高可用性保障。 7.k8s的apiserver证书续期 查看 Kubernetes API 服务器的证书有效期: openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text | grep Not [!CAUTION] Not Before: Oct 6 14:09:37 2024 GMT Not After : Oct 6 14:55:00 2025 GMT 使用kubeadm部署k8s自动创建的crt证书有效期是1年时间,为了确保证书长期有效,这里选择修改crt证书的过期时间为100年,下载官方提供的 update-kubeadm-cert.sh 脚本(在Master控制节点操作): git clone https://github.com/yuyicai/update-kube-cert.git cd update-kube-cert chmod 755 update-kubeadm-cert.sh sed -i '1,$s/CERT_DAYS=3650/CERT_DAYS=36500/g' update-kubeadm-cert.sh ./update-kubeadm-cert.sh all ./update-kubeadm-cert.sh all --cri containerd openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text | grep Not [!CAUTION] Not Before: Oct 6 15:43:28 2024 GMT Not After : Sep 12 15:43:28 2124 GMT 证书时效延长成功!
多Master节点的k8s集群部署 多Master节点的k8s集群部署 一、准备工作 1.准备五台主机(三台Master节点,一台Node节点,一台普通用户)如下: 角色 IP 内存 核心 磁盘 Master01 192.168.116.141 4G 4个 55G Master02 192.168.116.142 4G 4个 55G Master03 192.168.116.143 4G 4个 55G Node 192.168.116.144 4G 4个 55G 普通用户 192.168.116.150 4G 4个 55G 2.关闭SElinux,因为SElinux会影响K8S部分组件无法正常工作: sed -i '1,$s/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config reboot 3.四台主机分别配置主机名(不包括普通用户),如下: 控制节点Master01: hostnamectl set-hostname master01 && bash 控制节点Master02: hostnamectl set-hostname master02 && bash 控制节点Master03: hostnamectl set-hostname master03 && bash 工作节点Node: hostnamectl set-hostname node && bash 4.四台主机(不包括普通用户)分别配置host文件: 进入hosts文件: vim /etc/hosts 修改文件内容,添加四台主机以及IP: 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.116.141 master01 192.168.116.142 master02 192.168.116.143 master03 192.168.116.144 node 修改完可以四台主机用ping命令检查是否连通: ping -c1 -W1 master01 ping -c1 -W1 master02 ping -c1 -W1 master03 ping -c1 -W1 node 5.四台主机(不包括普通用户)分别下载所需意外组件包和相关依赖包: yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip autoconf automake zlib-devel epel-release openssh-server libaio-devel vim ncurses-devel socat conntrack telnet ipvsadm 所需相关意外组件包解释如下: yum-utils:提供了一些辅助工具用于 yum 包管理器,比如 yum-config-manager,repoquery 等。 device-mapper-persistent-data:与 Linux 的设备映射功能相关,通常与 LVM(逻辑卷管理)和容器存储(如 Docker)有关。 lvm2:逻辑卷管理器,用于管理磁盘上的逻辑卷,允许灵活的磁盘分区管理。 wget:一个非交互式网络下载工具,支持 HTTP、HTTPS 和 FTP 协议,常用于下载文件。 net-tools:提供一些经典的网络工具,如 ifconfig,netstat 等,用于查看和管理网络配置。 nfs-utils:支持 NFS(网络文件系统)的工具包,允许客户端挂载远程文件系统。 lrzsz:lrz 和 lsz 是 Linux 系统下用于 X/ZMODEM 文件传输协议的命令行工具,常用于串口传输数据。 gcc:GNU C 编译器,用于编译 C 语言程序。 gcc-c++:GNU C++ 编译器,用于编译 C++ 语言程序。 make:用于构建和编译程序,通常与 Makefile 配合使用,控制程序的编译和打包过程。 cmake:跨平台的构建系统生成工具,用于管理项目的编译过程,特别适用于大型复杂项目。 libxml2-devel:开发用的 libxml2 库头文件,libxml2 是一个用于解析 XML 文件的 C 库。 openssl-devel:用于 OpenSSL 库开发的头文件和开发库,OpenSSL 是用于 SSL/TLS 加密的库。 curl:一个用于传输数据的命令行工具,支持多种协议(HTTP、FTP 等)。 curl-devel:开发用的 curl 库和头文件,支持在代码中使用 curl 相关功能。 unzip:用于解压缩 .zip 文件。 autoconf:自动生成配置脚本的工具,常用于生成软件包的 configure 文件。 automake:自动生成 Makefile.in 文件,结合 autoconf 使用,用于构建系统。 zlib-devel:zlib 库的开发头文件,zlib 是一个用于数据压缩的库。 epel-release:用于启用 EPEL(Extra Packages for Enterprise Linux)存储库,提供大量额外的软件包。 openssh-server:OpenSSH 服务器,用于通过 SSH 远程登录和管理系统。 libaio-devel:异步 I/O 库的开发头文件,提供异步文件 I/O 支持,常用于数据库和高性能应用。 vim:一个强大的文本编辑器,支持多种语言和扩展功能。 ncurses-devel:开发用的 ncurses 库,提供终端控制和用户界面的构建工具。 socat:一个多功能的网络工具,用于双向数据传输,支持多种协议和地址类型。 conntrack:连接跟踪工具,显示和操作内核中的连接跟踪表,常用于网络防火墙和 NAT 配置。 telnet:用于远程登录的一种简单网络协议,允许通过命令行与远程主机进行通信。 ipvsadm:用于管理 IPVS(IP 虚拟服务器),这是一个 Linux 内核中的负载均衡模块,常用于高可用性负载均衡集群。 6.配置主机之间免密登录 四台节点同时执行: 1)配置三台Master主机到另外一台Node主机免密登录: ssh-keygen # 遇到问题不输入任何内容,直按回车 2)把刚刚生成的公钥文件传递到其他Master和node节点,输入yes后,在输入主机对应的密码: ssh-copy-id master01 ssh-copy-id master02 ssh-copy-id master03 ssh-copy-id node 7.关闭所有主机的firewall防火墙 如果不想关闭防火墙可以添加firewall-cmd规则进行过滤筛选,相关内容查询资料,不做演示。 关闭防火墙: systemctl stop firewalld && systemctl disable firewalld systemctl status firewalld # 查询防火墙状态,关闭后应为 Active: inactive (dead) 添加防火墙规则: 6443:Kubernetes Api Server 2379、2380:Etcd数据库 10250、10255:kubelet服务 10257:kube-controller-manager 服务 10259:kube-scheduler 服务 30000-32767:在物理机映射的 NodePort端口 179、473、4789、9099:Calico 服务 9090、3000:Prometheus监控+Grafana面板 8443:Kubernetes Dashboard控制面板 # Kubernetes API Server firewall-cmd --zone=public --add-port=6443/tcp --permanent # Etcd 数据库 firewall-cmd --zone=public --add-port=2379-2380/tcp --permanent # Kubelet 服务 firewall-cmd --zone=public --add-port=10250/tcp --permanent firewall-cmd --zone=public --add-port=10255/tcp --permanent # Kube-Controller-Manager 服务 firewall-cmd --zone=public --add-port=10257/tcp --permanent # Kube-Scheduler 服务 firewall-cmd --zone=public --add-port=10259/tcp --permanent # NodePort 映射端口 firewall-cmd --zone=public --add-port=30000-32767/tcp --permanent # Calico 服务 firewall-cmd --zone=public --add-port=179/tcp --permanent # BGP firewall-cmd --zone=public --add-port=473/tcp --permanent # IP-in-IP firewall-cmd --zone=public --add-port=4789/udp --permanent # VXLAN firewall-cmd --zone=public --add-port=9099/tcp --permanent # Calico 服务 #Prometheus监控+Grafana面板 firewall-cmd --zone=public --add-port=9090/tcp --permanent firewall-cmd --zone=public --add-port=3000/tcp --permanent # Kubernetes Dashboard控制面板 firewall-cmd --zone=public --add-port=8443/tcp --permanent # 重新加载防火墙配置以应用更改 firewall-cmd --reload 8.四台主机关闭swap交换分区 swap 分区的读写速度远低于物理内存。如果 Kubernetes 工作负载依赖于 swap 来补偿内存不足,会导致性能显著下降,尤其是在资源密集型的容器应用中。Kubernetes 更倾向于让节点直接面临内存不足的情况,而不是依赖 swap,从而促使调度器重新分配资源。 Kubernetes 默认会在 kubelet 启动时检查 swap 的状态,并要求其关闭。如果 swap 未关闭,Kubernetes 可能无法正常启动并报出错误。例如: [!WARNING] kubelet: Swap is enabled; production deployments should disable swap. 为了让 Kubernetes 正常工作,建议在所有节点上永久关闭 swap,同时调整系统的内存管理: swapoff -a # 关闭当前swap sed -i '/swap/s/^/#/' /etc/fstab # swap前添加注释 grep swap /etc/fstab # 成功关闭会这样:#/dev/mapper/rl-swap none swap defaults 0 0 9.修改内核参数 四台主机(不包括普通用户)分别执行: modprobe br_netfilter modprobe:用于加载或卸载内核模块的命令。 br_netfilter:该模块允许桥接的网络流量被 iptables 规则过滤,通常在启用网络桥接的情况下使用。 该模块主要在 Kubernetes 容器网络环境中使用,确保 Linux 内核能够正确处理网络流量的过滤和转发,特别是在容器间的通信中。 四台主机分别执行: cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf # 使配置生效 net.bridge.bridge-nf-call-ip6tables = 1:允许 IPv6 网络流量通过 Linux 网络桥接时使用 ip6tables 进行过滤。 net.bridge.bridge-nf-call-iptables = 1:允许 IPv4 网络流量通过 Linux 网络桥接时使用 iptables 进行过滤。 net.ipv4.ip_forward = 1:允许 Linux 内核进行 IPv4 数据包的转发(路由)。 这些设置确保在 Kubernetes 中,网络桥接流量可通过 iptables 和 ip6tables 过滤,并启用 IPv4 数据包转发,提升网络安全性和通信能力。 10.配置安装Docker和Containerd的yum源 四台主机分别安装docker-ce源(任选其一,只安装一个),后续操作只演示阿里源的。 # 阿里源 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 清华大学开源软件镜像站 yum-config-manager --add-repo https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo # 中国科技大学开源镜像站 yum-config-manager --add-repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo # 中科大镜像源 yum-config-manager --add-repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo # 华为云源 yum-config-manager --add-repo https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo 11.配置K8S命令行工具所需要的yum源 cat > /etc/yum.repos.d/kubernetes.repo <<EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF yum makecache 12.四台主机进行时间同步 Chrony 和 NTPD都是用于时间同步的工具,但 Chrony 在许多方面有其独特的优点。以下是 Chrony 相较于 NTPD 的一些主要优点,并基于此,进行chrony时间同步的部署: 1) 四台主机安装Chrony yum -y install chrony 2)四台主机修改配置文件,添加国内 NTP 服务器 echo "server ntp1.aliyun.com iburst" >> /etc/chrony.conf echo "server ntp2.aliyun.com iburst" >> /etc/chrony.conf echo "server ntp3.aliyun.com iburst" >> /etc/chrony.conf echo "server ntp.tuna.tsinghua.edu.cn iburst" >> /etc/chrony.conf tail -n 4 /etc/chrony.conf systemctl restart chronyd 3) 可以设置定时任务,每分钟重启chrony服务,进行时间校准(非必须) echo "* * * * * /usr/bin/systemctl restart chronyd" | tee -a /var/spool/cron/root 建议手动进行添加,首先执行crontab -e命令,在将如下内容添加至定时任务中 * * * * * /usr/bin/systemctl restart chronyd 这五个星号表示时间调度,每个星号代表一个时间字段,从左到右分别是: 第一个星号:分钟(0-59) 第二个星号:小时(0-23) 第三个星号:日期(1-31) 第四个星号:月份(1-12) 第五个星号:星期几(0-7,0 和 7 都代表星期天) 在这里,每个字段都用 表示“每一个”,因此 的意思是“每分钟的每一秒”。 /usr/bin/systemctl 是 systemctl 命令的完整路径,用于管理系统服务。 13.安装Containerd Containerd 是一个高性能的容器运行时,在 Kubernetes 中它负责容器的生命周期管理,包括创建、运行、停止和删除容器,同时支持从镜像仓库拉取和管理镜像。Containerd 提供容器运行时接口 (CRI),与 Kubernetes 无缝集成,确保高效的资源利用和快速的容器启动时间。除此之外,它还支持事件监控和日志记录,方便运维和调试,是实现容器编排和管理的关键组件。 四台主机安装containerd1.6.22版本 yum -y install containerd.io-1.6.22 yum -y install containerd.io-1.6.22 --allowerasing # 如果安装有问题选择这个,默认用第一个 创建containerd的配置文件目录并修改自带的config.toml。 mkdir -pv /etc/containerd vim /etc/containerd/config.toml 修改内容如下: disabled_plugins = [] imports = [] oom_score = 0 plugin_dir = "" required_plugins = [] root = "/var/lib/containerd" state = "/run/containerd" temp = "" version = 2 [cgroup] path = "" [debug] address = "" format = "" gid = 0 level = "" uid = 0 [grpc] address = "/run/containerd/containerd.sock" gid = 0 max_recv_message_size = 16777216 max_send_message_size = 16777216 tcp_address = "" tcp_tls_ca = "" tcp_tls_cert = "" tcp_tls_key = "" uid = 0 [metrics] address = "" grpc_histogram = false [plugins] [plugins."io.containerd.gc.v1.scheduler"] deletion_threshold = 0 mutation_threshold = 100 pause_threshold = 0.02 schedule_delay = "0s" startup_delay = "100ms" [plugins."io.containerd.grpc.v1.cri"] device_ownership_from_security_context = false disable_apparmor = false disable_cgroup = false disable_hugetlb_controller = true disable_proc_mount = false disable_tcp_service = true enable_selinux = false enable_tls_streaming = false enable_unprivileged_icmp = false enable_unprivileged_ports = false ignore_image_defined_volumes = false max_concurrent_downloads = 3 max_container_log_line_size = 16384 netns_mounts_under_state_dir = false restrict_oom_score_adj = false sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9" selinux_category_range = 1024 stats_collect_period = 10 stream_idle_timeout = "4h0m0s" stream_server_address = "127.0.0.1" stream_server_port = "0" systemd_cgroup = false tolerate_missing_hugetlb_controller = true unset_seccomp_profile = "" [plugins."io.containerd.grpc.v1.cri".cni] bin_dir = "/opt/cni/bin" conf_dir = "/etc/cni/net.d" conf_template = "" ip_pref = "" max_conf_num = 1 [plugins."io.containerd.grpc.v1.cri".containerd] default_runtime_name = "runc" disable_snapshot_annotations = true discard_unpacked_layers = false ignore_rdt_not_enabled_errors = false no_pivot = false snapshotter = "overlayfs" [plugins."io.containerd.grpc.v1.cri".containerd.default_runtime] base_runtime_spec = "" cni_conf_dir = "" cni_max_conf_num = 0 container_annotations = [] pod_annotations = [] privileged_without_host_devices = false runtime_engine = "" runtime_path = "" runtime_root = "" runtime_type = "" [plugins."io.containerd.grpc.v1.cri".containerd.default_runtime.options] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] base_runtime_spec = "" cni_conf_dir = "" cni_max_conf_num = 0 container_annotations = [] pod_annotations = [] privileged_without_host_devices = false runtime_engine = "" runtime_path = "" runtime_root = "" runtime_type = "io.containerd.runc.v2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] BinaryName = "" CriuImagePath = "" CriuPath = "" CriuWorkPath = "" IoGid = 0 IoUid = 0 NoNewKeyring = false NoPivotRoot = false Root = "" ShimCgroup = "" SystemdCgroup = true [plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime] base_runtime_spec = "" cni_conf_dir = "" cni_max_conf_num = 0 container_annotations = [] pod_annotations = [] privileged_without_host_devices = false runtime_engine = "" runtime_path = "" runtime_root = "" runtime_type = "" [plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime.options] [plugins."io.containerd.grpc.v1.cri".image_decryption] key_model = "node" [plugins."io.containerd.grpc.v1.cri".registry] config_path = "" [plugins."io.containerd.grpc.v1.cri".registry.auths] [plugins."io.containerd.grpc.v1.cri".registry.configs] [plugins."io.containerd.grpc.v1.cri".registry.headers] [plugins."io.containerd.grpc.v1.cri".registry.mirrors] [plugins."io.containerd.grpc.v1.cri".x509_key_pair_streaming] tls_cert_file = "" tls_key_file = "" [plugins."io.containerd.internal.v1.opt"] path = "/opt/containerd" [plugins."io.containerd.internal.v1.restart"] interval = "10s" [plugins."io.containerd.internal.v1.tracing"] sampling_ratio = 1.0 service_name = "containerd" [plugins."io.containerd.metadata.v1.bolt"] content_sharing_policy = "shared" [plugins."io.containerd.monitor.v1.cgroups"] no_prometheus = false [plugins."io.containerd.runtime.v1.linux"] no_shim = false runtime = "runc" runtime_root = "" shim = "containerd-shim" shim_debug = false [plugins."io.containerd.runtime.v2.task"] platforms = ["linux/amd64"] sched_core = false [plugins."io.containerd.service.v1.diff-service"] default = ["walking"] [plugins."io.containerd.service.v1.tasks-service"] rdt_config_file = "" [plugins."io.containerd.snapshotter.v1.aufs"] root_path = "" [plugins."io.containerd.snapshotter.v1.btrfs"] root_path = "" [plugins."io.containerd.snapshotter.v1.devmapper"] async_remove = false base_image_size = "" discard_blocks = false fs_options = "" fs_type = "" pool_name = "" root_path = "" [plugins."io.containerd.snapshotter.v1.native"] root_path = "" [plugins."io.containerd.snapshotter.v1.overlayfs"] root_path = "" upperdir_label = false [plugins."io.containerd.snapshotter.v1.zfs"] root_path = "" [plugins."io.containerd.tracing.processor.v1.otlp"] endpoint = "" insecure = false protocol = "" [proxy_plugins] [stream_processors] [stream_processors."io.containerd.ocicrypt.decoder.v1.tar"] accepts = ["application/vnd.oci.image.layer.v1.tar+encrypted"] args = ["--decryption-keys-path", "/etc/containerd/ocicrypt/keys"] env = ["OCICRYPT_KEYPROVIDER_CONFIG=/etc/containerd/ocicrypt/ocicrypt_keyprovider.conf"] path = "ctd-decoder" returns = "application/vnd.oci.image.layer.v1.tar" [stream_processors."io.containerd.ocicrypt.decoder.v1.tar.gzip"] accepts = ["application/vnd.oci.image.layer.v1.tar+gzip+encrypted"] args = ["--decryption-keys-path", "/etc/containerd/ocicrypt/keys"] env = ["OCICRYPT_KEYPROVIDER_CONFIG=/etc/containerd/ocicrypt/ocicrypt_keyprovider.conf"] path = "ctd-decoder" returns = "application/vnd.oci.image.layer.v1.tar+gzip" [timeouts] "io.containerd.timeout.bolt.open" = "0s" "io.containerd.timeout.shim.cleanup" = "5s" "io.containerd.timeout.shim.load" = "5s" "io.containerd.timeout.shim.shutdown" = "3s" "io.containerd.timeout.task.state" = "2s" [ttrpc] address = "" gid = 0 uid = 0 sandbox 镜像源:设置 Kubernetes 使用的沙箱容器镜像,支持高效管理容器。 sandbox_image = “registry.aliyuncs.com/google_containers/pause:3.9” hugeTLB 控制器:禁用 hugeTLB 控制器,减少内存管理复杂性,适合不需要的环境。 disable_hugetlb_controller = true 网络插件路径:指定 CNI 网络插件的二进制和配置路径,确保网络功能正常。 bin_dir = “/opt/cni/bin” conf_dir = “/etc/cni/net.d” 垃圾回收调度器:调整垃圾回收阈值和启动延迟,优化容器资源管理和性能。 pause_threshold = 0.02 startup_delay = “100ms” 流媒体服务器:配置流媒体服务的地址和端口,实现与客户端的有效数据传输。 stream_server_address = “127.0.0.1” stream_server_port = “0” 启动并设置containerd开机自启 systemctl enable containerd --now systemctl status containerd 14.安装Docker-ce(使用docker的拉镜像功能) 1)四台主机分别安装docker-ce最新版: yum -y install docker-ce 2)启动并设置docker开机自启: systemctl start docker && systemctl enable docker.service 3)配置docker的镜像加速器地址: 注:阿里加速地址登录阿里云加速器官网查看,每个人的加速地址不同 tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": [ "https://fb3aq27p.mirror.aliyuncs.com", "https://registry.docker-cn.com", "https://docker.mirrors.ustc.edu.cn", "https://dockerhub.azk8s.cn", "http://hub-mirror.c.163.com" ] } EOF systemctl daemon-reload systemctl restart docker systemctl status docker 二、K8S安装部署 1.安装K8S相关核心组件 四台主机分别安装K8S相关核心组件: yum -y install kubelet-1.28.2 kubeadm-1.28.2 kubectl-1.28.2 systemctl enable kubelet kubelet 是 Kubernetes 集群中每个节点上的核心代理,它负责根据控制平面的指示管理和维护节点上的 Pod 及容器的生命周期,确保容器按规范运行并定期与控制平面通信。kubelet 会将节点和 Pod 的状态上报给控制节点的 apiServer,apiServer再将这些信息存储到 etcd 数据库中。 kubeadm 是一个用于简化 Kubernetes 集群安装和管理的工具,快速初始化控制平面节点和将工作节点加入集群,减少手动配置的复杂性。 kubectl 是 Kubernetes 的命令行工具,用于管理员与集群进行交互,执行各种任务,如部署应用、查看资源、排查问题、管理集群状态等,通过命令行与 Kubernetes API 直接通信。 2.通过keepalived+nginx实现kubernetes apiServer的节点高可用 1)在三台Master节点分别安装keepalived+nginx,实现对apiserver的负载均衡和反向代理。Master01作为keepalived的主节点,Master02和Master03作为keepalived的备用节点。 yum -y install epel-release nginx keepalived nginx-mod-stream 2)修改配置nginx.conf配置文件: vim /etc/nginx/nginx.conf 3)更改配置配置文件完整信息如下: user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } 新增 stream 配置 stream { # 日志格式 log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent'; # 日志存放路径 access_log /var/log/nginx/k8s-access.log main; # master 调度资源池 upstream k8s-apiserver { server 192.168.116.141:6443 weight=5 max_fails=3 fail_timeout=30s; server 192.168.116.142:6443 weight=5 max_fails=3 fail_timeout=30s; server 192.168.116.143:6443 weight=5 max_fails=3 fail_timeout=30s; } server { listen 16443; # 避免与 Kubernetes master 节点冲突 proxy_pass k8s-apiserver; # 做反向代理到资源池 } } http { include /etc/nginx/mime.types; default_type application/octet-stream; # 日志格式 log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf; } stream模块用于四层负载均衡,转发到多个k8s-apiserver节点。 四层负载均衡工作在传输层,仅关注 TCP/UDP 连接的信息,例如源IP地址、端口、目标IP地址和端口,基于这些信息进行流量转发,不关心传输的数据内容。 七层负载均衡工作在应用层,理解更高层的协议(如 HTTP、HTTPS),根据请求的具体内容(例如URL、Cookies、Headers)进行更复杂的流量分配和处理。 log_format和access_log用于记录日志。 upstream定义了多个k8s-apiserver服务器,负载均衡策略基于权重weight,并有故障处理机制。 server块中,listen使用端口16443,以避免与Kubernetes master节点的默认端口6443冲突。 4)重启nginx并设置开机自启: systemctl restart nginx && systemctl enable nginx 5)先编写keepalived的检查脚本: 注:将这个脚本分别放到三台Master节点上,建议放在/etc/keepalived/目录,方便后续进行优化更新。 #!/bin/bash Author :lyx Description :check nginx Date :2024.10.06 Version :2.3 # 定义日志文件路径 ```python LOG_FILE="/var/log/nginx_keepalived_check.log" MAX_LINES=1000 # 设置日志保留1000行(因为不做限制日志会无限增大,占用大量磁盘空间) 记录日志的函数,带有详细的时间格式,并保留最后1000行日志 log_message() { local time_stamp=$(date '+%Y-%m-%d %H:%M:%S') # 定义时间格式 echo "$time_stamp - $1" >> $LOG_FILE # 截取日志文件,只保留最后1000行 tail -n $MAX_LINES $LOG_FILE > ${LOG_FILE}.tmp && mv ${LOG_FILE}.tmp $LOG_FILE } 检测 Nginx 是否在运行的函数 check_nginx() { pgrep -f "nginx: master" > /dev/null 2>&1 echo $? } 1. 检查 Nginx 是否存活 log_message "正在检查 Nginx 状态..." if [ $(check_nginx) -ne 0 ]; then log_message "Nginx 未运行,尝试启动 Nginx..." # 2. 如果 Nginx 不在运行,则尝试启动 systemctl start nginx sleep 2 # 等待 Nginx 启动 # 3. 再次检查 Nginx 状态 log_message "启动 Nginx 后再次检查状态..." if [ $(check_nginx) -ne 0 ]; then log_message "Nginx 启动失败,停止 Keepalived 服务..." # 4. 如果 Nginx 启动失败,停止 Keepalived systemctl stop keepalived else log_message "Nginx 启动成功。" fi else log_message "Nginx 正常运行。" fi 若nginx出现问题会打印中文日志到:/var/log/nginx_keepalived_check.log , 可以手动进行查看输出的日志消息,再根据对应故障的具体时间,结合nginx的日志来进行修复或者优化。 分别授予脚本可执行权限: chmod +x /etc/keepalived/keepalived_nginx_check.sh 这个脚本的主要作用是监控 Nginx 服务的运行状态,并在检测到 Nginx 停止运行时,尝试重启它。如果重启失败,脚本会停止 Keepalived 服务,避免继续提供不可用的服务。 监控 Nginx 状态:脚本定期检查 Nginx 是否正常运行,使用 pgrep 命令检测主进程状态。 自动修复机制:如果 Nginx 未运行,尝试重启服务,并再次检测其状态;若重启成功,记录日志。 停止 Keepalived:如果 Nginx 无法启动,停止 Keepalived 服务,防止服务器继续作为故障节点运行。 6)修改keepalived主节点Master01的配置文件: global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 # 用来发送、接收和中转电子邮件的服务器 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_script keepalived_nginx_check { # 这里是上一步骤添加的脚本,在这里进行调用 script "/etc/keepalived/keepalived_nginx_check.sh" # 根据自己添加的脚本路径进行修改,建议还是放在这个目录下便于管理 } vrrp_instance VI_1 { state MASTER # 主修改state为MASTER,备修改为BACKUP interface ens160 # 修改自己的实际网卡名称 virtual_router_id 51 # 主备的虚拟路由ID要相同 priority 100 # 优先级,备服务器设置优先级比主服务器的优先级低一些 advert_int 1 # 广播包发送间隔时间为1秒 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.116.16/24 # 虚拟IP修改为没有占用的IP地址,主备的虚拟IP相同就好 } track_script { keepalived_nginx_check # vrrp_script 定义的脚本名,放到这里进行追踪调用,Keepalived 可以根据脚本返回的结果做出相应的动作 } 7)修改keepalived备份节点Master02的配置文件: global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 # 用来发送、接收和中转电子邮件的服务器 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_script keepalived_nginx_check { # 这里是上一步骤添加的脚本,在这里进行调用 script "/etc/keepalived/keepalived_nginx_check.sh" # 根据自己添加的脚本路径进行修改,建议还是放在这个目录下便于管理 } vrrp_instance VI_1 { state BACKUP # 主修改state为MASTER,备修改为BACKUP interface ens160 # 修改自己的实际网卡名称 virtual_router_id 51 # 主备的虚拟路由ID要相同 priority 90 # 优先级,备服务器设置优先级比主服务器的优先级低一些 advert_int 1 # 广播包发送间隔时间为1秒 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.116.16/24 # 虚拟IP修改为没有占用的IP地址,主备的虚拟IP相同就好 } track_script { keepalived_nginx_check # vrrp_script 定义的脚本名,放到这里进行追踪调用,Keepalived 可以根据脚本返回的结果做出相应的动作 } } 7)修改keepalived备份节点Master03的配置文件: global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 # 用来发送、接收和中转电子邮件的服务器 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_script keepalived_nginx_check { # 这里是上一步骤添加的脚本,在这里进行调用 script "/etc/keepalived/keepalived_nginx_check.sh" # 根据自己添加的脚本路径进行修改,建议还是放在这个目录下便于管理 } vrrp_instance VI_1 { state BACKUP # 主修改state为MASTER,备修改为BACKUP interface ens160 # 修改自己的实际网卡名称 virtual_router_id 51 # 主备的虚拟路由ID要相同 priority 80 # 优先级,备服务器设置优先级比主服务器的优先级低一些 advert_int 1 # 广播包发送间隔时间为1秒 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.116.16/24 # 虚拟IP修改为没有占用的IP地址,主备的虚拟IP相同就好 } track_script { keepalived_nginx_check # vrrp_script 定义的脚本名,放到这里进行追踪调用,Keepalived 可以根据脚本返回的结果做出相应的动作 } } 三台节点主要的修改内容为这三部分: state MASTER / BACKUP interface ens160 priority 100 / 90 / 80 8)重载配置文件并重启nginx+keepalived服务: systemctl daemon-reload && systemctl restart nginx systemctl restart keepalived && systemctl enable keepalived 9)检查虚拟IP是否绑定成功: ip address show | grep 192.168.116.16 # 根据你们自己设置的虚拟IP来检查 如果成功绑定会有如下信息: [!IMPORTANT] inet 192.168.116.16/24 scope global secondary ens160 10)检查keepalived漂移是否设置成功(keepalived_nginx_check.sh脚本是否生效) (1)在keepalived的主节点Master01关闭keepalived服务: systemctl stop keepalived (2)切换到keepalived的备节点Master01查看网卡信息 ip address show | grep 192.168.116.16 # 根据你们自己设置的虚拟IP来检查 若出现如下提示,即为漂移成功: [!IMPORTANT] inet 192.168.116.16/24 scope global secondary ens160 注:如果主keepalived不异常的情况下,在两个备节点是无法查看到192.168.116.16虚拟IP的。 3.初始化K8S集群 1)Master01节点分别使用kubeadm初始化K8S集群: 注:kubeadm安装K8S,控制节点和工作节点的组件都是基于Pod运行的。 kubeadm config print init-defaults > kubeadm.yaml 生成默认的配置文件重定向输出到 kubeadm.yaml 中 2)修改刚刚用kubeadm生成的kubeadm.yaml文件: sed -i '/localAPIEndpoint/s/^/#/' kubeadm.yaml sed -i '/advertiseAddress/s/^/#/' kubeadm.yaml sed -i '/bindPort/s/^/#/' kubeadm.yaml sed -i '/name: node/s/^/#/' kubeadm.yaml sed -i "s|criSocket:.*|criSocket: unix://$(find / -name containerd.sock | head -n 1)|" kubeadm.yaml sed -i 's|imageRepository: registry.k8s.io|imageRepository: registry.aliyuncs.com/google_containers|' kubeadm.yaml # 原配置为国外的k8s源,为了加速镜像的下载,需改成国内源 sed -i '/serviceSubnet/a\ podSubnet: 10.244.0.0/12' kubeadm.yaml # /a\ 表示在serviceSubnet行下方一行内容 cat <<EOF >> kubeadm.yaml --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs --- apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd EOF more kubeadm.yaml # 手动检查一下 advertiseAddress 是 Kubernetes 控制节点的广告地址,其他节点通过这个地址与控制平面节点通信。它通常是控制节点所在服务器的 IP 地址,为了确保控制平面节点能在网络中通过正确的控制节点 IP 地址(我的MasterIP为:192.168.116.131)进行通信。 criSocket 指定的是 Kubernetes 使用的容器运行时(CRI)套接字地址,K8S 使用这个套接字与容器运行时(如 containerd)进行通信,来管理和启动容器。为了确保 K8S使用正确的容器运行时套接字。通过 find 命令查找 containerd.sock 文件路径并替换进配置文件,可以保证路径的准确性,避免手动查找和配置错误。 IPVS 模式支持更多的负载均衡算法,性能更好,尤其在集群节点和服务较多的情况下,可以显著提升网络转发效率和稳定性(如果没有指定mode为ipvs,则默认选定iptables,iptables性能相对较差)。 统一使用 systemd 作为容器和系统服务的 cgroup 驱动,避免使用 cgroupfs 时可能产生的资源管理不一致问题,提升 Kubernetes 和宿主机系统的兼容性和稳定性。 注:主机 IP、Pod IP 和 Service IP 不能在同一网段,因会导致 IP 冲突、路由混乱及网络隔离失败,影响 Kubernetes 的正常通信和网络安全。 3)基于kubeadm.yaml 文件初始化K8S,Master01节点拉取 Kubernetes 1.28.0 所需的镜像(两个方法可以二选一): (1)使用使用 kubeadm 命令,快速拉取 Kubernetes 所有核心组件的镜像,并确保版本一致。 kubeadm config images pull --image-repository="registry.aliyuncs.com/google_containers" --kubernetes-version=v1.28.0 (2)使用 ctr 命令,需要更细粒度的控制,或在 kubeadm 拉取镜像过程中出现问题时,可以使用 ctr 命令手动拉取镜像。 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.28.0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.28.0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/kube-proxy:v1.28.0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/pause:3.9 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/etcd:3.5.9-0 ctr -n=k8s.io images pull registry.aliyuncs.com/google_containers/coredns:v1.10.1 4)在Master控制节点,初始化 Kubernetes 主节点 kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerification 个别操作系统可能会出现kubelet启动失败的情况,如下提示,如果提示successfully则忽略以下步骤: [!WARNING] dial tcp [::1]:10248: connect: connection refused 执行systemctl status kubelet发现出现以下错误提示: [!WARNING] Process: 2226953 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=1/FAILURE) Main PID: 2226953 (code=exited, status=1/FAILURE) 解决方法如下,控制节点执行: sed -i 's|ExecStart=/usr/bin/kubelet|ExecStart=/usr/bin/kubelet --container-runtime-endpoint=unix://$(find / -name containerd.sock | head -n 1) --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml|' /usr/lib/systemd/system/kubelet.service systemctl daemon-reload systemctl restart kubelet kubeadm reset # 删除安装出错的K8S kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerification # 重新安装 3.设置 Kubernetes 的配置文件,以便让当前用户能够使用 kubectl 命令与 Kubernetes 集群进行交互 控制节点Master01执行: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config 4.扩容k8s控制节点,将Master01和Master02加入到k8s集群 1)Master02和Master03创建证书存放目录: mkdir -pv /etc/kubernetes/pki/etcd && mkdir -pv ~/.kube/ 2)远程拷贝证书文件到Master02: scp /etc/kubernetes/pki/ca.crt root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/ca.key root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.key root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.pub root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.crt root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.key root@192.168.116.142:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/etcd/ca.crt root@192.168.116.142:/etc/kubernetes/pki/etcd/ scp /etc/kubernetes/pki/etcd/ca.key root@192.168.116.142:/etc/kubernetes/pki/etcd/ 3)远程拷贝证书文件到Master03: scp /etc/kubernetes/pki/ca.crt root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/ca.key root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.key root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/sa.pub root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.crt root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/front-proxy-ca.key root@192.168.116.143:/etc/kubernetes/pki/ scp /etc/kubernetes/pki/etcd/ca.crt root@192.168.116.143:/etc/kubernetes/pki/etcd/ scp /etc/kubernetes/pki/etcd/ca.key root@192.168.116.143:/etc/kubernetes/pki/etcd/ 4)控制节点Master01生成集群token: kubeadm token create --print-join-command 生成token如下: [!IMPORTANT] kubeadm join 192.168.116.141:6443 --token pb1pk7.6p6w2jl1gjvlmmdz --discovery-token-ca-cert-hash sha256:b3b9de172cf6c48d97396621858a666e0be2d2d5578e4ce0fba5f1739b735fc1 如果控制节点加入集群需要在生成的token后加入 --control-plane ,如下: kubeadm join 192.168.116.141:6443 --token pb1pk7.6p6w2jl1gjvlmmdz --discovery-token-ca-cert-hash sha256:b3b9de172cf6c48d97396621858a666e0be2d2d5578e4ce0fba5f1739b735fc1 --control-plane 控制节点加入集群后执行如下命令,即可使用kubectl命令工作: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config 如果工作节点加入集群,直接复制生成的这行命令到node主机执行即可: kubeadm join 192.168.116.141:6443 --token pb1pk7.6p6w2jl1gjvlmmdz --discovery-token-ca-cert-hash sha256:b3b9de172cf6c48d97396621858a666e0be2d2d5578e4ce0fba5f1739b735fc1 工作节点加入集群后,设置一个用户的 kubectl 环境,使其能够与 Kubernetes 集群进行交互:: mkdir ~/.kube cp /etc/kubernetes/kubelet.conf ~/.kube/config 注意:如果扩容节点时,有以下报错: [!CAUTION] [preflight] Reading configuration from the cluster… [preflight] FYI: You can look at this config file with ‘kubectl -n kube-system get cm kubeadm-config -o yaml’ error execution phase preflight: One or more conditions for hosting a new control plane instance is not satisfied. unable to add a new control plane instance a cluster that doesn’t have a stable controlPlaneEndpoint address Please ensure that: The cluster has a stable controlPlaneEndpoint address. The certificates that must be shared among control plane instances are provided. To see the stack trace of this error execute with --v=5 or higher 解决方法为添加 controlPlaneEndpoint: kubectl -n kube-system edit cm kubeadm-config 添加如下 controlPlaneEndpoint: 192.168.116.141:6443 (Master01的IP地址) 即可解决: kind: ClusterConfiguration kubernetesVersion: v1.18.0 controlPlaneEndpoint: 192.168.116.141:6443 重新复制生成的这行命令到node主机执行(控制节点需要添加 --control-plane),提示为如下内容则为成功扩容: To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster. 5.安装k8s网络组件Calico Calico 是一个流行的开源网络解决方案,专为 Kubernetes 提供高效、可扩展和安全的网络连接。它采用了基于 IP 的网络模型,使每个 Pod 都能获得一个唯一的 IP 地址,从而简化了网络管理。Calico 支持多种网络策略,可以实现细粒度的流量控制和安全策略,例如基于标签的访问控制,允许用户定义哪些 Pod 可以相互通信。(简单来说就是给Pod和Service分IP的,还能通过网络策略做网络隔离) 1)四台主机分别安装calico: ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/cni:v3.25.0 ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/pod2daemon-flexvol:v3.25.0 ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/node:v3.25.0 ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/kube-controllers:v3.25.0 ctr image pull -n=k8s.io swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/typha:v3.25.0 2) 控制节点下载calico3.25.0的yaml配置文件(下载失败把URL复制到浏览器,手动复制粘贴内容到Master01节点效果相同) curl -O -L https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/calico.yaml 3)编辑calico.yaml,找到CLUSTER_TYPE行,在下面添加一对键值对,确保使用网卡接口(注意缩进): 原配置: - name: CLUSTER_TYPE value: "k8s,bgp" 新配置: - name: CLUSTER_TYPE value: "k8s,bgp" - name: IP_AUTODELECTION_METHOD value: "interface=ens160" 注:不同操作系统的网卡名称有差异,例:centos7.9的网卡名称为ens33,就要填写value: “interface=ens33”,需灵活变通。 注:如果出现calico拉取镜像错误问题,可能是没有修改imagePullPresent规则,可以修改官方源下载为华为源下载,如下: sed -i '1,$s|docker.io/calico/cni:v3.25.0|swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/cni:v3.25.0|g' calico.yaml sed -i '1,$s|docker.io/calico/node:v3.25.0|swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/node:v3.25.0|g' calico.yaml sed -i '1,$s|docker.io/calico/kube-controllers:v3.25.0|swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/kube-controllers:v3.25.0|g' calico.yaml 4)部署calico网络服务 kubectl apply -f calico.yaml 查看在 Kubernetes 集群中查看属于 kube-system 命名空间的所有 Pod 的详细信息(控制节点和工作节点都查的到): kubectl get pod --namespace kube-system -o wide calico安装成功的信息大概如下: [!IMPORTANT] NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-665548954f-5dgjw 1/1 Running 0 3m3s 10.255.112.131 master01 calico-node-4gb27 1/1 Running 0 3m3s 192.168.116.142 master02 calico-node-4kckd 1/1 Running 0 3m3s 192.168.116.144 node calico-node-cpnwp 1/1 Running 0 3m3s 192.168.116.141 master01 calico-node-hldt2 1/1 Running 0 3m3s 192.168.116.143 master03 coredns-66f779496c-8pzvp 1/1 Running 0 61m 10.255.112.129 master01 coredns-66f779496c-frsvq 1/1 Running 0 61m 10.255.112.130 master01 etcd-master01 1/1 Running 0 61m 192.168.116.141 master01 etcd-master02 1/1 Running 0 21m 192.168.116.142 master02 etcd-master03 1/1 Running 0 20m 192.168.116.143 master03 kube-apiserver-master01 1/1 Running 0 61m 192.168.116.141 master01 kube-apiserver-master02 1/1 Running 0 22m 192.168.116.142 master02 kube-apiserver-master03 1/1 Running 1 (21m ago) 19m 192.168.116.143 master03 kube-controller-manager-master01 1/1 Running 1 (21m ago) 61m 192.168.116.141 master01 kube-controller-manager-master02 1/1 Running 0 22m 192.168.116.142 master02 kube-controller-manager-master03 1/1 Running 0 20m 192.168.116.143 master03 kube-proxy-jvt6w 1/1 Running 0 31m 192.168.116.144 node kube-proxy-lw8g4 1/1 Running 0 61m 192.168.116.141 master01 kube-proxy-mjw8h 1/1 Running 0 22m 192.168.116.142 master02 kube-proxy-rtlpz 1/1 Running 0 21m 192.168.116.143 master03 kube-scheduler-master01 1/1 Running 1 (21m ago) 61m 192.168.116.141 master01 kube-scheduler-master02 1/1 Running 0 22m 192.168.116.142 master02 kube-scheduler-master03 1/1 Running 0 19m 192.168.116.143 master03 6.配置Etcd的高可用 Etcd默认的yaml文件–initial-cluster只指定自己,所以需要修改为指定我们的三台Master节点主机: Master01节点 sed -i 's|--initial-cluster=master01=https://192.168.116.141:2380|--initial-cluster=master01=https://192.168.116.141:2380,master02=https://192.168.116.142:2380,master03=https://192.168.116.143:2380|' /etc/kubernetes/manifests/etcd.yaml Master02节点 sed -i 's|--initial-cluster=master01=https://192.168.116.141:2380|--initial-cluster=master01=https://192.168.116.142:2380,master02=https://192.168.116.142:2380,master03=https://192.168.116.143:2380|' /etc/kubernetes/manifests/etcd.yaml Master03节点 sed -i 's|--initial-cluster=master01=https://192.168.116.141:2380|--initial-cluster=master01=https://192.168.116.143:2380,master02=https://192.168.116.142:2380,master03=https://192.168.116.143:2380|' /etc/kubernetes/manifests/etcd.yaml 修改的目的是在 Kubernetes 高可用(HA)集群 中为 etcd 集群 提供节点的初始集群信息。简单来说就是,--initial-cluster 的配置作用是告诉 etcd 节点关于集群中的其他成员信息,这样它们可以相互通信、保持一致并提供高可用性保障。 7.k8s的apiserver证书续期 查看 Kubernetes API 服务器的证书有效期: openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text | grep Not [!CAUTION] Not Before: Oct 6 14:09:37 2024 GMT Not After : Oct 6 14:55:00 2025 GMT 使用kubeadm部署k8s自动创建的crt证书有效期是1年时间,为了确保证书长期有效,这里选择修改crt证书的过期时间为100年,下载官方提供的 update-kubeadm-cert.sh 脚本(在Master控制节点操作): git clone https://github.com/yuyicai/update-kube-cert.git cd update-kube-cert chmod 755 update-kubeadm-cert.sh sed -i '1,$s/CERT_DAYS=3650/CERT_DAYS=36500/g' update-kubeadm-cert.sh ./update-kubeadm-cert.sh all ./update-kubeadm-cert.sh all --cri containerd openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text | grep Not [!CAUTION] Not Before: Oct 6 15:43:28 2024 GMT Not After : Sep 12 15:43:28 2124 GMT 证书时效延长成功! -
 欧拉系统双Master高可用Kubernetes集群一键式部署指南 欧拉系统双Master高可用Kubernetes集群一键式部署指南 一、系统初始化(所有节点执行) # ===================== 基础配置 ===================== # 禁用防火墙与SELinux sudo systemctl stop firewalld && sudo systemctl disable firewalld sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config # 关闭Swap sudo swapoff -a sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab # 配置内核参数 cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sudo sysctl --system # 设置主机名解析(根据实际IP修改) cat <<EOF | sudo tee -a /etc/hosts 172.20.1.11 master01 172.20.1.12 master02 172.20.1.21 node01 172.20.1.10 lb-vip EOF # ===================== 时间同步 ===================== sudo yum install -y chrony sudo systemctl enable chronyd && sudo systemctl start chronyd chronyc sources -v # 验证输出包含^*表示同步正常 # ===================== 日志审计 ===================== sudo mkdir -p /var/log/kubernetes/audit 二、负载均衡层部署(lb01/lb02执行) # ===================== HAProxy安装 ===================== sudo yum install -y haproxy # 生成配置文件(注意替换实际Master IP) cat <<EOF | sudo tee /etc/haproxy/haproxy.cfg global log /dev/log local0 maxconn 20000 user haproxy group haproxy defaults log global mode tcp timeout connect 5s timeout client 50s timeout server 50s frontend k8s-api bind *:6443 default_backend k8s-api backend k8s-api balance roundrobin option tcp-check server master01 172.20.1.11:6443 check port 6443 inter 5s fall 3 rise 2 server master02 172.20.1.12:6443 check port 6443 inter 5s fall 3 rise 2 frontend k8s-http bind *:80 bind *:443 default_backend k8s-http backend k8s-http balance roundrobin server master01 172.20.1.11:80 check server master02 172.20.1.12:80 check EOF # 启动服务 sudo systemctl enable haproxy && sudo systemctl restart haproxy ss -ltnp | grep 6443 # 应显示HAProxy监听端口 # ===================== Keepalived配置 ===================== sudo yum install -y keepalived # 主节点配置(lb01) cat <<EOF | sudo tee /etc/keepalived/keepalived.conf vrrp_script chk_haproxy { script "pidof haproxy" interval 2 weight 2 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 172.20.1.10/24 } track_script { chk_haproxy } } EOF # 备节点配置(lb02): # 修改state为BACKUP,priority改为90 sudo systemctl enable keepalived && sudo systemctl restart keepalived ip addr show eth0 | grep '172.20.1.10' # 应看到VIP绑定 三、容器运行时安装(所有节点执行) # ===================== Containerd安装 ===================== cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf overlay br_netfilter EOF sudo modprobe overlay sudo modprobe br_netfilter sudo yum install -y containerd sudo containerd config default | sudo tee /etc/containerd/config.toml sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml sudo systemctl enable containerd && sudo systemctl restart containerd # 验证运行时状态 sudo ctr version # 应显示客户端和服务端版本 四、Kubernetes组件安装(所有节点执行) # ===================== 配置仓库 ===================== cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 EOF # ===================== 安装指定版本 ===================== sudo yum install -y kubeadm-1.28.2 kubelet-1.28.2 kubectl-1.28.2 sudo systemctl enable kubelet # 检查版本 kubeadm version -o short # 应输出v1.28.2 五、首个Master节点初始化(master01执行) # ===================== 生成初始化配置 ===================== cat <<EOF | tee kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta3 kind: InitConfiguration nodeRegistration: criSocket: "unix:///var/run/containerd/containerd.sock" --- apiVersion: kubeadm.k8s.io/v1beta3 kind: ClusterConfiguration kubernetesVersion: v1.28.2 controlPlaneEndpoint: "lb-vip:6443" networking: podSubnet: 10.244.0.0/16 apiServer: certSANs: - "lb-vip" - "172.20.1.10" imageRepository: registry.aliyuncs.com/google_containers EOF # ===================== 执行初始化 ===================== sudo kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log # 配置kubectl mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config # 获取加入命令 echo "Master加入命令:" grep 'kubeadm join' kubeadm-init.log -A2 echo "Worker加入命令:" kubeadm token create --print-join-command 六、第二个Master节点加入(master02执行) # 使用master01生成的control-plane加入命令 sudo kubeadm join lb-vip:6443 --token <your-token> \ --discovery-token-ca-cert-hash sha256:<your-hash> \ --control-plane --certificate-key <your-cert-key> \ --apiserver-advertise-address=172.20.1.12 # 验证etcd集群 sudo docker run --rm -it \ --net host \ -v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd \ registry.aliyuncs.com/google_containers/etcd:3.5.6-0 \ etcdctl --endpoints=https://172.20.1.11:2379 \ --cert=/etc/kubernetes/pki/etcd/peer.crt \ --key=/etc/kubernetes/pki/etcd/peer.key \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ endpoint health 七、Worker节点加入(node01执行) # 使用worker加入命令 sudo kubeadm join lb-vip:6443 --token <your-token> \ --discovery-token-ca-cert-hash sha256:<your-hash> # 在主节点验证 kubectl get nodes -o wide -w 八、网络插件部署(任一Master执行) # ===================== Calico安装 ===================== kubectl apply -f https://docs.projectcalico.org/v3.26/manifests/calico.yaml # 监控安装进度 watch kubectl get pods -n kube-system -l k8s-app=calico-node # 验证网络连通性 kubectl create deployment nginx --image=nginx:alpine kubectl expose deployment nginx --port=80 kubectl run test --image=busybox --rm -it -- ping nginx.default.svc.cluster.local 九、验证高可用性 # 模拟Master节点故障 ssh master01 "sudo systemctl stop kube-apiserver" kubectl get componentstatus # 观察服务状态切换 # 验证VIP漂移 ssh lb01 "sudo systemctl stop keepalived" ping -c 5 lb-vip # 应持续可达 十、部署后检查清单 # 集群状态检查 kubectl get componentstatus kubectl get nodes -o wide kubectl get pods -A -o wide # 网络策略验证 kubectl run test-pod --image=nginx:alpine --restart=Never --rm -it -- sh # 在容器内执行: curl -I http://kubernetes.default ping <其他节点Pod IP> # 存储验证 kubectl apply -f - <<EOF apiVersion: v1 kind: PersistentVolume metadata: name: test-pv spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: /data/test-pv EOF kubectl get pv 故障排查命令速查: # 查看kubelet日志 journalctl -u kubelet -f # 检查证书有效期 kubeadm certs check-expiration # 重置节点(危险!) kubeadm reset -f rm -rf /etc/cni/net.d /etc/kubernetes/ $HOME/.kube # 强制删除Pod kubectl delete pod <pod-name> --grace-period=0 --force 部署完成验证清单: 所有节点状态为Ready calico-node Pod全部Running coredns Pod正常运行 能跨节点访问Service VIP漂移测试成功 控制平面组件无警告信息
欧拉系统双Master高可用Kubernetes集群一键式部署指南 欧拉系统双Master高可用Kubernetes集群一键式部署指南 一、系统初始化(所有节点执行) # ===================== 基础配置 ===================== # 禁用防火墙与SELinux sudo systemctl stop firewalld && sudo systemctl disable firewalld sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config # 关闭Swap sudo swapoff -a sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab # 配置内核参数 cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sudo sysctl --system # 设置主机名解析(根据实际IP修改) cat <<EOF | sudo tee -a /etc/hosts 172.20.1.11 master01 172.20.1.12 master02 172.20.1.21 node01 172.20.1.10 lb-vip EOF # ===================== 时间同步 ===================== sudo yum install -y chrony sudo systemctl enable chronyd && sudo systemctl start chronyd chronyc sources -v # 验证输出包含^*表示同步正常 # ===================== 日志审计 ===================== sudo mkdir -p /var/log/kubernetes/audit 二、负载均衡层部署(lb01/lb02执行) # ===================== HAProxy安装 ===================== sudo yum install -y haproxy # 生成配置文件(注意替换实际Master IP) cat <<EOF | sudo tee /etc/haproxy/haproxy.cfg global log /dev/log local0 maxconn 20000 user haproxy group haproxy defaults log global mode tcp timeout connect 5s timeout client 50s timeout server 50s frontend k8s-api bind *:6443 default_backend k8s-api backend k8s-api balance roundrobin option tcp-check server master01 172.20.1.11:6443 check port 6443 inter 5s fall 3 rise 2 server master02 172.20.1.12:6443 check port 6443 inter 5s fall 3 rise 2 frontend k8s-http bind *:80 bind *:443 default_backend k8s-http backend k8s-http balance roundrobin server master01 172.20.1.11:80 check server master02 172.20.1.12:80 check EOF # 启动服务 sudo systemctl enable haproxy && sudo systemctl restart haproxy ss -ltnp | grep 6443 # 应显示HAProxy监听端口 # ===================== Keepalived配置 ===================== sudo yum install -y keepalived # 主节点配置(lb01) cat <<EOF | sudo tee /etc/keepalived/keepalived.conf vrrp_script chk_haproxy { script "pidof haproxy" interval 2 weight 2 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 172.20.1.10/24 } track_script { chk_haproxy } } EOF # 备节点配置(lb02): # 修改state为BACKUP,priority改为90 sudo systemctl enable keepalived && sudo systemctl restart keepalived ip addr show eth0 | grep '172.20.1.10' # 应看到VIP绑定 三、容器运行时安装(所有节点执行) # ===================== Containerd安装 ===================== cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf overlay br_netfilter EOF sudo modprobe overlay sudo modprobe br_netfilter sudo yum install -y containerd sudo containerd config default | sudo tee /etc/containerd/config.toml sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml sudo systemctl enable containerd && sudo systemctl restart containerd # 验证运行时状态 sudo ctr version # 应显示客户端和服务端版本 四、Kubernetes组件安装(所有节点执行) # ===================== 配置仓库 ===================== cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 EOF # ===================== 安装指定版本 ===================== sudo yum install -y kubeadm-1.28.2 kubelet-1.28.2 kubectl-1.28.2 sudo systemctl enable kubelet # 检查版本 kubeadm version -o short # 应输出v1.28.2 五、首个Master节点初始化(master01执行) # ===================== 生成初始化配置 ===================== cat <<EOF | tee kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta3 kind: InitConfiguration nodeRegistration: criSocket: "unix:///var/run/containerd/containerd.sock" --- apiVersion: kubeadm.k8s.io/v1beta3 kind: ClusterConfiguration kubernetesVersion: v1.28.2 controlPlaneEndpoint: "lb-vip:6443" networking: podSubnet: 10.244.0.0/16 apiServer: certSANs: - "lb-vip" - "172.20.1.10" imageRepository: registry.aliyuncs.com/google_containers EOF # ===================== 执行初始化 ===================== sudo kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log # 配置kubectl mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config # 获取加入命令 echo "Master加入命令:" grep 'kubeadm join' kubeadm-init.log -A2 echo "Worker加入命令:" kubeadm token create --print-join-command 六、第二个Master节点加入(master02执行) # 使用master01生成的control-plane加入命令 sudo kubeadm join lb-vip:6443 --token <your-token> \ --discovery-token-ca-cert-hash sha256:<your-hash> \ --control-plane --certificate-key <your-cert-key> \ --apiserver-advertise-address=172.20.1.12 # 验证etcd集群 sudo docker run --rm -it \ --net host \ -v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd \ registry.aliyuncs.com/google_containers/etcd:3.5.6-0 \ etcdctl --endpoints=https://172.20.1.11:2379 \ --cert=/etc/kubernetes/pki/etcd/peer.crt \ --key=/etc/kubernetes/pki/etcd/peer.key \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ endpoint health 七、Worker节点加入(node01执行) # 使用worker加入命令 sudo kubeadm join lb-vip:6443 --token <your-token> \ --discovery-token-ca-cert-hash sha256:<your-hash> # 在主节点验证 kubectl get nodes -o wide -w 八、网络插件部署(任一Master执行) # ===================== Calico安装 ===================== kubectl apply -f https://docs.projectcalico.org/v3.26/manifests/calico.yaml # 监控安装进度 watch kubectl get pods -n kube-system -l k8s-app=calico-node # 验证网络连通性 kubectl create deployment nginx --image=nginx:alpine kubectl expose deployment nginx --port=80 kubectl run test --image=busybox --rm -it -- ping nginx.default.svc.cluster.local 九、验证高可用性 # 模拟Master节点故障 ssh master01 "sudo systemctl stop kube-apiserver" kubectl get componentstatus # 观察服务状态切换 # 验证VIP漂移 ssh lb01 "sudo systemctl stop keepalived" ping -c 5 lb-vip # 应持续可达 十、部署后检查清单 # 集群状态检查 kubectl get componentstatus kubectl get nodes -o wide kubectl get pods -A -o wide # 网络策略验证 kubectl run test-pod --image=nginx:alpine --restart=Never --rm -it -- sh # 在容器内执行: curl -I http://kubernetes.default ping <其他节点Pod IP> # 存储验证 kubectl apply -f - <<EOF apiVersion: v1 kind: PersistentVolume metadata: name: test-pv spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: /data/test-pv EOF kubectl get pv 故障排查命令速查: # 查看kubelet日志 journalctl -u kubelet -f # 检查证书有效期 kubeadm certs check-expiration # 重置节点(危险!) kubeadm reset -f rm -rf /etc/cni/net.d /etc/kubernetes/ $HOME/.kube # 强制删除Pod kubectl delete pod <pod-name> --grace-period=0 --force 部署完成验证清单: 所有节点状态为Ready calico-node Pod全部Running coredns Pod正常运行 能跨节点访问Service VIP漂移测试成功 控制平面组件无警告信息 -
 Browser-Use:让 AI 掌控浏览器帮你干活 在当今数字化的浪潮中,AI 技术正以前所未有的速度改变着我们的生活和工作方式。今天,我们要为大家介绍一款名为 Browser-Use 的开源项目,它能够让 AI 轻松控制浏览器,为我们带来全新的自动化体验。 项目简介 Browser-Use 是一个强大的工具,旨在帮助开发者将 AI 与浏览器无缝连接。它就像是一座桥梁,让 AI 能够像人类一样在浏览器中进行各种操作,如打开网页、查找信息、填写表单等。这个项目的出现,为自动化测试、数据采集、网页交互等领域带来了新的可能性。 部署方案 本地部署 1. 环境准备 确保你已经安装了 Python 3.11 或更高版本。可以使用以下命令检查 Python 版本: python --version 2. 安装依赖 使用 pip 安装 Browser-Use 及其相关依赖: pip install browser-use playwright install 3. 配置 API 密钥 在项目根目录下创建一个 .env 文件,并添加你使用的 AI 提供商的 API 密钥,例如: OPENAI_API_KEY=your_openai_api_key 4. 运行示例代码 以下是一个简单的示例代码,用于比较 gpt-4o 和 DeepSeek-V3 的价格: from langchain_openai import ChatOpenAI from browser_use import Agent import asyncio from dotenv import load_dotenv load_dotenv() async def main(): agent = Agent( task="Compare the price of gpt-4o and DeepSeek-V3", llm=ChatOpenAI(model="gpt-4o"), ) await agent.run() asyncio.run(main()) 云部署 如果你想跳过本地部署的繁琐步骤,可以尝试使用 Browser-Use 的云版本。只需访问 https://cloud.browser-use.com,即可立即开始使用浏览器自动化服务。 使用场景 自动化测试 在软件开发过程中,自动化测试是确保软件质量的重要环节。Browser-Use 可以帮助开发者编写自动化测试脚本,模拟用户在浏览器中的各种操作,如点击按钮、输入文本、提交表单等。例如,在测试一个电商网站时,可以使用 Browser-Use 自动添加商品到购物车、填写收货地址、完成支付流程,从而快速发现潜在的问题。 数据采集 在信息时代,数据是企业的重要资产。Browser-Use 可以用于自动化数据采集,从网页上提取所需的信息。例如,在市场调研中,可以使用 Browser-Use 自动访问各大电商平台,收集商品的价格、销量、评价等信息,为企业的决策提供有力支持。 网页交互自动化 对于一些重复性的网页操作,如登录、签到、发送消息等,Browser-Use 可以实现自动化,提高工作效率。例如,在社交媒体管理中,可以使用 Browser-Use 自动登录多个社交媒体账号,定时发布内容、回复评论,节省大量的时间和精力。 与 Slack 集成 Browser-Use 还支持与 Slack 集成,方便团队协作。以下是集成的具体步骤: 1. 创建 Slack 应用 访问 https://api.slack.com/apps,点击 “Create New App”。 选择 “From scratch”,并为你的应用命名,选择要使用的工作空间。 提供机器人的名称和描述。 2. 配置机器人 导航到 “OAuth & Permissions” 选项卡,在 “Scopes” 中添加必要的机器人令牌范围,如 “chat:write”、“channels:history”、“im:history”。 3. 启用事件订阅 导航到 “Event Subscriptions” 选项卡,启用事件并添加必要的机器人事件,如 “message.channels”、“message.im”。 添加你的请求 URL(可以使用 ngrok 暴露本地服务器)。 4. 获取签名密钥和机器人令牌 导航到 “Basic Information” 选项卡,复制 “Signing Secret”。 导航到 “OAuth & Permissions” 选项卡,复制 “Bot User OAuth Token”。 5. 配置环境变量 在项目根目录下的 .env 文件中添加以下内容: SLACK_SIGNING_SECRET=your-signing-secret SLACK_BOT_TOKEN=your-bot-token 6. 邀请机器人到频道 在 Slack 频道中使用 /invite @your-bot-name 命令邀请机器人。 7. 运行代码 运行 examples/slack_example.py 启动机器人,然后在 Slack 频道中输入 $bu whats the weather in Tokyo? 即可开始一个 Browser-Use 任务并获取响应。 总结 Browser-Use 是一个功能强大、易于使用的开源项目,它为 AI 与浏览器的交互提供了一种简单而有效的方式。通过本地部署或云部署,我们可以在各种场景中使用 Browser-Use 实现自动化操作,提高工作效率和质量。同时,与 Slack 的集成也为团队协作带来了便利。
Browser-Use:让 AI 掌控浏览器帮你干活 在当今数字化的浪潮中,AI 技术正以前所未有的速度改变着我们的生活和工作方式。今天,我们要为大家介绍一款名为 Browser-Use 的开源项目,它能够让 AI 轻松控制浏览器,为我们带来全新的自动化体验。 项目简介 Browser-Use 是一个强大的工具,旨在帮助开发者将 AI 与浏览器无缝连接。它就像是一座桥梁,让 AI 能够像人类一样在浏览器中进行各种操作,如打开网页、查找信息、填写表单等。这个项目的出现,为自动化测试、数据采集、网页交互等领域带来了新的可能性。 部署方案 本地部署 1. 环境准备 确保你已经安装了 Python 3.11 或更高版本。可以使用以下命令检查 Python 版本: python --version 2. 安装依赖 使用 pip 安装 Browser-Use 及其相关依赖: pip install browser-use playwright install 3. 配置 API 密钥 在项目根目录下创建一个 .env 文件,并添加你使用的 AI 提供商的 API 密钥,例如: OPENAI_API_KEY=your_openai_api_key 4. 运行示例代码 以下是一个简单的示例代码,用于比较 gpt-4o 和 DeepSeek-V3 的价格: from langchain_openai import ChatOpenAI from browser_use import Agent import asyncio from dotenv import load_dotenv load_dotenv() async def main(): agent = Agent( task="Compare the price of gpt-4o and DeepSeek-V3", llm=ChatOpenAI(model="gpt-4o"), ) await agent.run() asyncio.run(main()) 云部署 如果你想跳过本地部署的繁琐步骤,可以尝试使用 Browser-Use 的云版本。只需访问 https://cloud.browser-use.com,即可立即开始使用浏览器自动化服务。 使用场景 自动化测试 在软件开发过程中,自动化测试是确保软件质量的重要环节。Browser-Use 可以帮助开发者编写自动化测试脚本,模拟用户在浏览器中的各种操作,如点击按钮、输入文本、提交表单等。例如,在测试一个电商网站时,可以使用 Browser-Use 自动添加商品到购物车、填写收货地址、完成支付流程,从而快速发现潜在的问题。 数据采集 在信息时代,数据是企业的重要资产。Browser-Use 可以用于自动化数据采集,从网页上提取所需的信息。例如,在市场调研中,可以使用 Browser-Use 自动访问各大电商平台,收集商品的价格、销量、评价等信息,为企业的决策提供有力支持。 网页交互自动化 对于一些重复性的网页操作,如登录、签到、发送消息等,Browser-Use 可以实现自动化,提高工作效率。例如,在社交媒体管理中,可以使用 Browser-Use 自动登录多个社交媒体账号,定时发布内容、回复评论,节省大量的时间和精力。 与 Slack 集成 Browser-Use 还支持与 Slack 集成,方便团队协作。以下是集成的具体步骤: 1. 创建 Slack 应用 访问 https://api.slack.com/apps,点击 “Create New App”。 选择 “From scratch”,并为你的应用命名,选择要使用的工作空间。 提供机器人的名称和描述。 2. 配置机器人 导航到 “OAuth & Permissions” 选项卡,在 “Scopes” 中添加必要的机器人令牌范围,如 “chat:write”、“channels:history”、“im:history”。 3. 启用事件订阅 导航到 “Event Subscriptions” 选项卡,启用事件并添加必要的机器人事件,如 “message.channels”、“message.im”。 添加你的请求 URL(可以使用 ngrok 暴露本地服务器)。 4. 获取签名密钥和机器人令牌 导航到 “Basic Information” 选项卡,复制 “Signing Secret”。 导航到 “OAuth & Permissions” 选项卡,复制 “Bot User OAuth Token”。 5. 配置环境变量 在项目根目录下的 .env 文件中添加以下内容: SLACK_SIGNING_SECRET=your-signing-secret SLACK_BOT_TOKEN=your-bot-token 6. 邀请机器人到频道 在 Slack 频道中使用 /invite @your-bot-name 命令邀请机器人。 7. 运行代码 运行 examples/slack_example.py 启动机器人,然后在 Slack 频道中输入 $bu whats the weather in Tokyo? 即可开始一个 Browser-Use 任务并获取响应。 总结 Browser-Use 是一个功能强大、易于使用的开源项目,它为 AI 与浏览器的交互提供了一种简单而有效的方式。通过本地部署或云部署,我们可以在各种场景中使用 Browser-Use 实现自动化操作,提高工作效率和质量。同时,与 Slack 的集成也为团队协作带来了便利。 -
 Story Flicks:一键生成故事视频的神器 在信息爆炸的时代,如何以生动有趣的方式呈现故事成为了许多人的追求。今天要给大家介绍的 Story Flicks 项目,就为我们提供了一个绝佳的解决方案。它能够让用户通过输入故事主题,利用大语言模型轻松生成包含 AI 图像、故事内容、音频和字幕的故事视频。 项目介绍 Story Flicks 是一个集故事创作与视频生成于一体的项目。用户只需输入一个故事主题,系统就能借助强大的大语言模型,自动生成精彩的故事内容,同时搭配 AI 生成的精美图片、合适的音频以及准确的字幕,最终合成一个完整的故事视频。 技术栈 后端:采用 Python + FastAPI 框架构建,保证了系统的高效性和稳定性,能够快速处理用户的请求并生成所需的故事内容。 前端:基于 React + Ant Design + Vite 搭建,提供了简洁美观、易于操作的用户界面,让用户能够轻松上手。 视频示例 项目提供了两个精彩的视频示例,让我们先来一睹为快。 如果你无法看到该视频,那么可能你的电脑不支持该文件格式。 如果你无法看到该视频,那么可能你的电脑不支持该文件格式。 部署方法及具体步骤 1. 下载项目 首先,我们需要将项目克隆到本地。打开终端,执行以下命令: git clone https://github.com/alecm20/story-flicks.git 2. 设置模型信息 2.1 切换到后端目录 cd backend 2.2 复制环境变量示例文件 cp .env.example .env 2.3 编辑 .env 文件 在 .env 文件中,我们需要设置模型的相关信息,以下是详细的参数说明: text_provider = "openai" # 文本生成模型的提供商,目前支持 openai、aliyun、deepseek、ollama 和 siliconflow # 阿里云文档:https://www.aliyun.com/product/bailian image_provider = "aliyun" # 图像生成模型的提供商,目前支持 openai、aliyun 和 siliconflow openai_base_url="https://api.openai.com/v1" # OpenAI 的基础 URL aliyun_base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云的基础 URL deepseek_base_url="https://api.deepseek.com/v1" # DeepSeek 的基础 URL ollama_base_url="http://localhost:11434/v1" # Ollama 的基础 URL siliconflow_base_url="https://api.siliconflow.cn/v1" # SiliconFlow 的基础 URL openai_api_key= # OpenAI 的 API 密钥,只需提供一个密钥 aliyun_api_key= # 阿里云百炼的 API 密钥,只需提供一个密钥 deepseek_api_key= # DeepSeek 的 API 密钥,目前仅支持文本生成 ollama_api_key= # 如果需要使用,将 api_key 设置为 “ollama”。目前,此 API 密钥仅支持文本生成,不能用于参数过少的模型。建议使用 qwen2.5:14b 或更大的模型。 siliconflow_api_key= # SiliconFlow 的 API 密钥,SiliconFlow 的文本模型目前仅支持与 OpenAI 格式兼容的大模型,如图像模型仅对 black-forest-labs/FLUX.1-dev 进行了测试。 text_llm_model=gpt-4o # 如果 text_provider 设置为 openai,只能使用 OpenAI 模型,如 gpt-4o。如果选择阿里云,可以使用阿里云模型,如 qwen-plus 或 qwen-max。Ollama 模型不能使用参数过少的模型,建议使用 qwen2.5:14b 或更大的模型。 image_llm_model=flux-dev # 如果 image_provider 设置为 openai,只能使用 OpenAI 模型,如 dall-e-3。如果选择阿里云,建议使用阿里云模型,如 flux-dev,目前可免费试用。更多详情:https://help.aliyun.com/zh/model-studio/getting-started/models#a1a9f05a675m4。 3. 启动项目 3.1 手动启动后端项目 # 首先,切换到项目根目录 cd backend # 创建并激活虚拟环境 conda create -n story-flicks python=3.10 conda activate story-flicks # 安装依赖 pip install -r requirements.txt # 启动后端服务 uvicorn main:app --reload 如果项目启动成功,终端将输出以下信息: INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) INFO: Started reloader process [78259] using StatReload INFO: Started server process [78261] INFO: Waiting for application startup. INFO: Application startup complete. 项目优势 简单易用 用户只需输入故事主题,无需复杂的操作,即可快速生成故事视频,大大节省了时间和精力。 多样化的模型支持 支持多种文本和图像生成模型,用户可以根据自己的需求选择合适的模型,满足不同场景的创作需求。 丰富的功能 生成的视频包含 AI 图像、故事内容、音频和字幕,内容丰富多样,能够吸引观众的注意力。 总的来说,Story Flicks 是一个非常实用的故事视频生成项目,无论是个人创作者还是企业宣传,都能借助它轻松打造出精彩的故事视频。赶快动手部署,开启你的故事创作之旅吧!
Story Flicks:一键生成故事视频的神器 在信息爆炸的时代,如何以生动有趣的方式呈现故事成为了许多人的追求。今天要给大家介绍的 Story Flicks 项目,就为我们提供了一个绝佳的解决方案。它能够让用户通过输入故事主题,利用大语言模型轻松生成包含 AI 图像、故事内容、音频和字幕的故事视频。 项目介绍 Story Flicks 是一个集故事创作与视频生成于一体的项目。用户只需输入一个故事主题,系统就能借助强大的大语言模型,自动生成精彩的故事内容,同时搭配 AI 生成的精美图片、合适的音频以及准确的字幕,最终合成一个完整的故事视频。 技术栈 后端:采用 Python + FastAPI 框架构建,保证了系统的高效性和稳定性,能够快速处理用户的请求并生成所需的故事内容。 前端:基于 React + Ant Design + Vite 搭建,提供了简洁美观、易于操作的用户界面,让用户能够轻松上手。 视频示例 项目提供了两个精彩的视频示例,让我们先来一睹为快。 如果你无法看到该视频,那么可能你的电脑不支持该文件格式。 如果你无法看到该视频,那么可能你的电脑不支持该文件格式。 部署方法及具体步骤 1. 下载项目 首先,我们需要将项目克隆到本地。打开终端,执行以下命令: git clone https://github.com/alecm20/story-flicks.git 2. 设置模型信息 2.1 切换到后端目录 cd backend 2.2 复制环境变量示例文件 cp .env.example .env 2.3 编辑 .env 文件 在 .env 文件中,我们需要设置模型的相关信息,以下是详细的参数说明: text_provider = "openai" # 文本生成模型的提供商,目前支持 openai、aliyun、deepseek、ollama 和 siliconflow # 阿里云文档:https://www.aliyun.com/product/bailian image_provider = "aliyun" # 图像生成模型的提供商,目前支持 openai、aliyun 和 siliconflow openai_base_url="https://api.openai.com/v1" # OpenAI 的基础 URL aliyun_base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云的基础 URL deepseek_base_url="https://api.deepseek.com/v1" # DeepSeek 的基础 URL ollama_base_url="http://localhost:11434/v1" # Ollama 的基础 URL siliconflow_base_url="https://api.siliconflow.cn/v1" # SiliconFlow 的基础 URL openai_api_key= # OpenAI 的 API 密钥,只需提供一个密钥 aliyun_api_key= # 阿里云百炼的 API 密钥,只需提供一个密钥 deepseek_api_key= # DeepSeek 的 API 密钥,目前仅支持文本生成 ollama_api_key= # 如果需要使用,将 api_key 设置为 “ollama”。目前,此 API 密钥仅支持文本生成,不能用于参数过少的模型。建议使用 qwen2.5:14b 或更大的模型。 siliconflow_api_key= # SiliconFlow 的 API 密钥,SiliconFlow 的文本模型目前仅支持与 OpenAI 格式兼容的大模型,如图像模型仅对 black-forest-labs/FLUX.1-dev 进行了测试。 text_llm_model=gpt-4o # 如果 text_provider 设置为 openai,只能使用 OpenAI 模型,如 gpt-4o。如果选择阿里云,可以使用阿里云模型,如 qwen-plus 或 qwen-max。Ollama 模型不能使用参数过少的模型,建议使用 qwen2.5:14b 或更大的模型。 image_llm_model=flux-dev # 如果 image_provider 设置为 openai,只能使用 OpenAI 模型,如 dall-e-3。如果选择阿里云,建议使用阿里云模型,如 flux-dev,目前可免费试用。更多详情:https://help.aliyun.com/zh/model-studio/getting-started/models#a1a9f05a675m4。 3. 启动项目 3.1 手动启动后端项目 # 首先,切换到项目根目录 cd backend # 创建并激活虚拟环境 conda create -n story-flicks python=3.10 conda activate story-flicks # 安装依赖 pip install -r requirements.txt # 启动后端服务 uvicorn main:app --reload 如果项目启动成功,终端将输出以下信息: INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) INFO: Started reloader process [78259] using StatReload INFO: Started server process [78261] INFO: Waiting for application startup. INFO: Application startup complete. 项目优势 简单易用 用户只需输入故事主题,无需复杂的操作,即可快速生成故事视频,大大节省了时间和精力。 多样化的模型支持 支持多种文本和图像生成模型,用户可以根据自己的需求选择合适的模型,满足不同场景的创作需求。 丰富的功能 生成的视频包含 AI 图像、故事内容、音频和字幕,内容丰富多样,能够吸引观众的注意力。 总的来说,Story Flicks 是一个非常实用的故事视频生成项目,无论是个人创作者还是企业宣传,都能借助它轻松打造出精彩的故事视频。赶快动手部署,开启你的故事创作之旅吧!