


钟小言
致力于为您提供丰富而有趣的内容,旨在启发思考、分享知识。
-
 置顶 chatgpt-on-wechat 项目多种部署方式 chatgpt-on-wechat 项目提供了多种部署方式,以下是详细的部署步骤: 本地部署 1. 准备工作 系统要求:支持 Linux、MacOS、Windows 系统(可在Linux服务器上长期运行),同时需安装 Python。建议Python版本在 3.7.1 - 3.9.X 之间,推荐3.8版本,3.10及以上版本在 MacOS 可用,其他系统上不确定能否正常运行。 克隆项目代码: git clone https://github.com/zhayujie/chatgpt-on-wechat cd chatgpt-on-wechat/ 注:如遇到网络问题可选择国内镜像 https://gitee.com/zhayujie/chatgpt-on-wechat。 安装依赖: 核心依赖(必选):能够使用itchat创建机器人,并具有文字交流功能所需的最小依赖集合。 pip3 install -r requirements.txt 拓展依赖(可选,建议安装): pip3 install -r requirements-optional.txt 注意:如果某项依赖安装失败可注释掉对应的行再继续。 配置文件: 配置文件的模板在根目录的config-template.json中,需复制该模板创建最终生效的 config.json 文件: cp config-template.json config.json 然后在config.json中填入配置,以下是对默认配置的说明,可根据需要进行自定义修改(注意实际使用时请去掉注释,保证JSON格式的完整): { "model": "gpt-3.5-turbo", // 模型名称, 支持 gpt-3.5-turbo, gpt-4, gpt-4-turbo, wenxin, xunfei, glm-4, claude-3-haiku, moonshot "open_ai_api_key": "YOUR API KEY", // 如果使用openAI模型则填入上面创建的 OpenAI API KEY "open_ai_api_base": "https://api.openai.com/v1", // OpenAI接口代理地址 "proxy": "", // 代理客户端的ip和端口,国内环境开启代理的需要填写该项,如 "127.0.0.1:7890" "single_chat_prefix": , // 私聊时文本需要包含该前缀才能触发机器人回复 "single_chat_reply_prefix": " ", // 私聊时自动回复的前缀,用于区分真人 "group_chat_prefix": , // 群聊时包含该前缀则会触发机器人回复 "group_name_white_list": // 开启自动回复的群名称列表 } 2. 运行项目 使用nohup命令在后台运行程序: nohup python3 app.py & tail -f nohup.out # 在后台运行程序并通过日志输出二维码 扫码登录后程序即可运行于服务器后台,此时可通过 ctrl+c 关闭日志,不会影响后台程序的运行。使用 ps -ef | grep app.py | grep -v grep 命令可查看运行于后台的进程,如果想要重新启动程序可以先 kill 掉对应的进程。日志关闭后如果想要再次打开只需输入 tail -f nohup.out。此外,scripts 目录下有一键运行、关闭程序的脚本供使用。 多账号支持:将项目复制多份,分别启动程序,用不同账号扫码登录即可实现同时运行。 特殊指令:用户向机器人发送 #reset 即可清空该用户的上下文记忆。 Docker部署 前提条件:需要安装好 docker 及 docker-compose,安装成功的表现是执行 docker -v 和 docker-compose version (或 docker compose version) 可以查看到版本号,可前往 docker官网 进行下载。 步骤: 1.下载 docker-compose.yml 文件: wget https://open-1317903499.cos.ap-guangzhou.myqcloud.com/docker-compose.yml 下载完成后打开 docker-compose.yml 修改所需配置,如 OPEN_AI_API_KEY 和 GROUP_NAME_WHITE_LIST 等。 2.启动容器: 在 docker-compose.yml 所在目录下执行以下命令启动容器: sudo docker compose up -d 注意:如果 docker-compose 是 1.X 版本 则需要执行 sudo docker-compose up -d 来启动容器。 运行 sudo docker ps 能查看到 NAMES 为 chatgpt-on-wechat 的容器即表示运行成功。 3.查看容器运行日志: sudo docker logs -f chatgpt-on-wechat 扫描日志中的二维码即可完成登录。 4.插件使用: 如果需要在docker容器中修改插件配置,可通过挂载的方式完成,将 插件配置文件 重命名为 config.json,放置于 docker-compose.yml 相同目录下,并在 docker-compose.yml 中的 chatgpt-on-wechat 部分下添加 volumes 映射: volumes: - ./config.json:/app/plugins/config.json Railway部署 Railway 每月提供5刀和最多500小时的免费额度。 (07.11更新: 目前大部分账号已无法免费部署) 步骤: 进入 Railway。 点击 Deploy Now 按钮。 设置环境变量来重载程序运行的参数,例如open_ai_api_key, character_desc。 一键部署: https://railway.com/template/qApznZ?referralCode=RC3znh
置顶 chatgpt-on-wechat 项目多种部署方式 chatgpt-on-wechat 项目提供了多种部署方式,以下是详细的部署步骤: 本地部署 1. 准备工作 系统要求:支持 Linux、MacOS、Windows 系统(可在Linux服务器上长期运行),同时需安装 Python。建议Python版本在 3.7.1 - 3.9.X 之间,推荐3.8版本,3.10及以上版本在 MacOS 可用,其他系统上不确定能否正常运行。 克隆项目代码: git clone https://github.com/zhayujie/chatgpt-on-wechat cd chatgpt-on-wechat/ 注:如遇到网络问题可选择国内镜像 https://gitee.com/zhayujie/chatgpt-on-wechat。 安装依赖: 核心依赖(必选):能够使用itchat创建机器人,并具有文字交流功能所需的最小依赖集合。 pip3 install -r requirements.txt 拓展依赖(可选,建议安装): pip3 install -r requirements-optional.txt 注意:如果某项依赖安装失败可注释掉对应的行再继续。 配置文件: 配置文件的模板在根目录的config-template.json中,需复制该模板创建最终生效的 config.json 文件: cp config-template.json config.json 然后在config.json中填入配置,以下是对默认配置的说明,可根据需要进行自定义修改(注意实际使用时请去掉注释,保证JSON格式的完整): { "model": "gpt-3.5-turbo", // 模型名称, 支持 gpt-3.5-turbo, gpt-4, gpt-4-turbo, wenxin, xunfei, glm-4, claude-3-haiku, moonshot "open_ai_api_key": "YOUR API KEY", // 如果使用openAI模型则填入上面创建的 OpenAI API KEY "open_ai_api_base": "https://api.openai.com/v1", // OpenAI接口代理地址 "proxy": "", // 代理客户端的ip和端口,国内环境开启代理的需要填写该项,如 "127.0.0.1:7890" "single_chat_prefix": , // 私聊时文本需要包含该前缀才能触发机器人回复 "single_chat_reply_prefix": " ", // 私聊时自动回复的前缀,用于区分真人 "group_chat_prefix": , // 群聊时包含该前缀则会触发机器人回复 "group_name_white_list": // 开启自动回复的群名称列表 } 2. 运行项目 使用nohup命令在后台运行程序: nohup python3 app.py & tail -f nohup.out # 在后台运行程序并通过日志输出二维码 扫码登录后程序即可运行于服务器后台,此时可通过 ctrl+c 关闭日志,不会影响后台程序的运行。使用 ps -ef | grep app.py | grep -v grep 命令可查看运行于后台的进程,如果想要重新启动程序可以先 kill 掉对应的进程。日志关闭后如果想要再次打开只需输入 tail -f nohup.out。此外,scripts 目录下有一键运行、关闭程序的脚本供使用。 多账号支持:将项目复制多份,分别启动程序,用不同账号扫码登录即可实现同时运行。 特殊指令:用户向机器人发送 #reset 即可清空该用户的上下文记忆。 Docker部署 前提条件:需要安装好 docker 及 docker-compose,安装成功的表现是执行 docker -v 和 docker-compose version (或 docker compose version) 可以查看到版本号,可前往 docker官网 进行下载。 步骤: 1.下载 docker-compose.yml 文件: wget https://open-1317903499.cos.ap-guangzhou.myqcloud.com/docker-compose.yml 下载完成后打开 docker-compose.yml 修改所需配置,如 OPEN_AI_API_KEY 和 GROUP_NAME_WHITE_LIST 等。 2.启动容器: 在 docker-compose.yml 所在目录下执行以下命令启动容器: sudo docker compose up -d 注意:如果 docker-compose 是 1.X 版本 则需要执行 sudo docker-compose up -d 来启动容器。 运行 sudo docker ps 能查看到 NAMES 为 chatgpt-on-wechat 的容器即表示运行成功。 3.查看容器运行日志: sudo docker logs -f chatgpt-on-wechat 扫描日志中的二维码即可完成登录。 4.插件使用: 如果需要在docker容器中修改插件配置,可通过挂载的方式完成,将 插件配置文件 重命名为 config.json,放置于 docker-compose.yml 相同目录下,并在 docker-compose.yml 中的 chatgpt-on-wechat 部分下添加 volumes 映射: volumes: - ./config.json:/app/plugins/config.json Railway部署 Railway 每月提供5刀和最多500小时的免费额度。 (07.11更新: 目前大部分账号已无法免费部署) 步骤: 进入 Railway。 点击 Deploy Now 按钮。 设置环境变量来重载程序运行的参数,例如open_ai_api_key, character_desc。 一键部署: https://railway.com/template/qApznZ?referralCode=RC3znh -
 置顶 DeepSeek本地部署,保姆级教程,带你打造最强AI deepseek本地部署 第一步:安装ollama https://ollama.com/download 第二步:在ollama 官网搜索 https://ollama.com/ 模型大小与显卡需求 第三步:在终端执行 命令 等待安装即可 第五步:基本命令 #退出模型 >>> /bye #查看模型 C:\Users\chk>ollama list NAME ID SIZE MODIFIED deepseek-r1:1.5b a42b25d8c10a 1.1 GB 3 minutes ago #启动模型 ollama run deepseek-r1:1.5b >>> #查看帮助 C:\Users\chk>ollama -h Large language model runner Usage: ollama ollama Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model stop Stop a running model pull Pull a model from a registry push Push a model to a registry list List models ps List running models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information Use "ollama --help" for more information about a command. 可视化部署Web UI 第一步:下载Chatbox AI https://chatboxai.app/zh 设置中文 第二步:将 Chatbox 连接到远程 Ollama 服务 1.在 Windows 上配置环境变量 在 Windows 上,Ollama 会继承你的用户和系统环境变量。 通过任务栏退出 Ollama。 打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。 点击编辑你账户的环境变量。 为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 *。 点击确定/应用以保存设置。 从 Windows 开始菜单启动 Ollama 应用程序。 2.服务 IP 地址 配置后,Ollama 服务将能在当前网络(如家庭 Wifi)中提供服务。你可以使用其他设备上的 Chatbox 客户端连接到此服务。Ollama 服务的 IP 地址是你电脑在当前网络中的地址。 3.注意事项 可能需要在防火墙中允许 Ollama 服务的端口(默认为 11434),具体取决于你的操作系统和网络环境。 为避免安全风险,请不要将 Ollama 服务暴露在公共网络中。家庭 Wifi 网络是一个相对安全的环境。 4.Chatbox配置模型
置顶 DeepSeek本地部署,保姆级教程,带你打造最强AI deepseek本地部署 第一步:安装ollama https://ollama.com/download 第二步:在ollama 官网搜索 https://ollama.com/ 模型大小与显卡需求 第三步:在终端执行 命令 等待安装即可 第五步:基本命令 #退出模型 >>> /bye #查看模型 C:\Users\chk>ollama list NAME ID SIZE MODIFIED deepseek-r1:1.5b a42b25d8c10a 1.1 GB 3 minutes ago #启动模型 ollama run deepseek-r1:1.5b >>> #查看帮助 C:\Users\chk>ollama -h Large language model runner Usage: ollama ollama Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model stop Stop a running model pull Pull a model from a registry push Push a model to a registry list List models ps List running models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information Use "ollama --help" for more information about a command. 可视化部署Web UI 第一步:下载Chatbox AI https://chatboxai.app/zh 设置中文 第二步:将 Chatbox 连接到远程 Ollama 服务 1.在 Windows 上配置环境变量 在 Windows 上,Ollama 会继承你的用户和系统环境变量。 通过任务栏退出 Ollama。 打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。 点击编辑你账户的环境变量。 为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 *。 点击确定/应用以保存设置。 从 Windows 开始菜单启动 Ollama 应用程序。 2.服务 IP 地址 配置后,Ollama 服务将能在当前网络(如家庭 Wifi)中提供服务。你可以使用其他设备上的 Chatbox 客户端连接到此服务。Ollama 服务的 IP 地址是你电脑在当前网络中的地址。 3.注意事项 可能需要在防火墙中允许 Ollama 服务的端口(默认为 11434),具体取决于你的操作系统和网络环境。 为避免安全风险,请不要将 Ollama 服务暴露在公共网络中。家庭 Wifi 网络是一个相对安全的环境。 4.Chatbox配置模型 -
 Browser-Use:让 AI 掌控浏览器帮你干活 在当今数字化的浪潮中,AI 技术正以前所未有的速度改变着我们的生活和工作方式。今天,我们要为大家介绍一款名为 Browser-Use 的开源项目,它能够让 AI 轻松控制浏览器,为我们带来全新的自动化体验。 项目简介 Browser-Use 是一个强大的工具,旨在帮助开发者将 AI 与浏览器无缝连接。它就像是一座桥梁,让 AI 能够像人类一样在浏览器中进行各种操作,如打开网页、查找信息、填写表单等。这个项目的出现,为自动化测试、数据采集、网页交互等领域带来了新的可能性。 部署方案 本地部署 1. 环境准备 确保你已经安装了 Python 3.11 或更高版本。可以使用以下命令检查 Python 版本: python --version 2. 安装依赖 使用 pip 安装 Browser-Use 及其相关依赖: pip install browser-use playwright install 3. 配置 API 密钥 在项目根目录下创建一个 .env 文件,并添加你使用的 AI 提供商的 API 密钥,例如: OPENAI_API_KEY=your_openai_api_key 4. 运行示例代码 以下是一个简单的示例代码,用于比较 gpt-4o 和 DeepSeek-V3 的价格: from langchain_openai import ChatOpenAI from browser_use import Agent import asyncio from dotenv import load_dotenv load_dotenv() async def main(): agent = Agent( task="Compare the price of gpt-4o and DeepSeek-V3", llm=ChatOpenAI(model="gpt-4o"), ) await agent.run() asyncio.run(main()) 云部署 如果你想跳过本地部署的繁琐步骤,可以尝试使用 Browser-Use 的云版本。只需访问 https://cloud.browser-use.com,即可立即开始使用浏览器自动化服务。 使用场景 自动化测试 在软件开发过程中,自动化测试是确保软件质量的重要环节。Browser-Use 可以帮助开发者编写自动化测试脚本,模拟用户在浏览器中的各种操作,如点击按钮、输入文本、提交表单等。例如,在测试一个电商网站时,可以使用 Browser-Use 自动添加商品到购物车、填写收货地址、完成支付流程,从而快速发现潜在的问题。 数据采集 在信息时代,数据是企业的重要资产。Browser-Use 可以用于自动化数据采集,从网页上提取所需的信息。例如,在市场调研中,可以使用 Browser-Use 自动访问各大电商平台,收集商品的价格、销量、评价等信息,为企业的决策提供有力支持。 网页交互自动化 对于一些重复性的网页操作,如登录、签到、发送消息等,Browser-Use 可以实现自动化,提高工作效率。例如,在社交媒体管理中,可以使用 Browser-Use 自动登录多个社交媒体账号,定时发布内容、回复评论,节省大量的时间和精力。 与 Slack 集成 Browser-Use 还支持与 Slack 集成,方便团队协作。以下是集成的具体步骤: 1. 创建 Slack 应用 访问 https://api.slack.com/apps,点击 “Create New App”。 选择 “From scratch”,并为你的应用命名,选择要使用的工作空间。 提供机器人的名称和描述。 2. 配置机器人 导航到 “OAuth & Permissions” 选项卡,在 “Scopes” 中添加必要的机器人令牌范围,如 “chat:write”、“channels:history”、“im:history”。 3. 启用事件订阅 导航到 “Event Subscriptions” 选项卡,启用事件并添加必要的机器人事件,如 “message.channels”、“message.im”。 添加你的请求 URL(可以使用 ngrok 暴露本地服务器)。 4. 获取签名密钥和机器人令牌 导航到 “Basic Information” 选项卡,复制 “Signing Secret”。 导航到 “OAuth & Permissions” 选项卡,复制 “Bot User OAuth Token”。 5. 配置环境变量 在项目根目录下的 .env 文件中添加以下内容: SLACK_SIGNING_SECRET=your-signing-secret SLACK_BOT_TOKEN=your-bot-token 6. 邀请机器人到频道 在 Slack 频道中使用 /invite @your-bot-name 命令邀请机器人。 7. 运行代码 运行 examples/slack_example.py 启动机器人,然后在 Slack 频道中输入 $bu whats the weather in Tokyo? 即可开始一个 Browser-Use 任务并获取响应。 总结 Browser-Use 是一个功能强大、易于使用的开源项目,它为 AI 与浏览器的交互提供了一种简单而有效的方式。通过本地部署或云部署,我们可以在各种场景中使用 Browser-Use 实现自动化操作,提高工作效率和质量。同时,与 Slack 的集成也为团队协作带来了便利。
Browser-Use:让 AI 掌控浏览器帮你干活 在当今数字化的浪潮中,AI 技术正以前所未有的速度改变着我们的生活和工作方式。今天,我们要为大家介绍一款名为 Browser-Use 的开源项目,它能够让 AI 轻松控制浏览器,为我们带来全新的自动化体验。 项目简介 Browser-Use 是一个强大的工具,旨在帮助开发者将 AI 与浏览器无缝连接。它就像是一座桥梁,让 AI 能够像人类一样在浏览器中进行各种操作,如打开网页、查找信息、填写表单等。这个项目的出现,为自动化测试、数据采集、网页交互等领域带来了新的可能性。 部署方案 本地部署 1. 环境准备 确保你已经安装了 Python 3.11 或更高版本。可以使用以下命令检查 Python 版本: python --version 2. 安装依赖 使用 pip 安装 Browser-Use 及其相关依赖: pip install browser-use playwright install 3. 配置 API 密钥 在项目根目录下创建一个 .env 文件,并添加你使用的 AI 提供商的 API 密钥,例如: OPENAI_API_KEY=your_openai_api_key 4. 运行示例代码 以下是一个简单的示例代码,用于比较 gpt-4o 和 DeepSeek-V3 的价格: from langchain_openai import ChatOpenAI from browser_use import Agent import asyncio from dotenv import load_dotenv load_dotenv() async def main(): agent = Agent( task="Compare the price of gpt-4o and DeepSeek-V3", llm=ChatOpenAI(model="gpt-4o"), ) await agent.run() asyncio.run(main()) 云部署 如果你想跳过本地部署的繁琐步骤,可以尝试使用 Browser-Use 的云版本。只需访问 https://cloud.browser-use.com,即可立即开始使用浏览器自动化服务。 使用场景 自动化测试 在软件开发过程中,自动化测试是确保软件质量的重要环节。Browser-Use 可以帮助开发者编写自动化测试脚本,模拟用户在浏览器中的各种操作,如点击按钮、输入文本、提交表单等。例如,在测试一个电商网站时,可以使用 Browser-Use 自动添加商品到购物车、填写收货地址、完成支付流程,从而快速发现潜在的问题。 数据采集 在信息时代,数据是企业的重要资产。Browser-Use 可以用于自动化数据采集,从网页上提取所需的信息。例如,在市场调研中,可以使用 Browser-Use 自动访问各大电商平台,收集商品的价格、销量、评价等信息,为企业的决策提供有力支持。 网页交互自动化 对于一些重复性的网页操作,如登录、签到、发送消息等,Browser-Use 可以实现自动化,提高工作效率。例如,在社交媒体管理中,可以使用 Browser-Use 自动登录多个社交媒体账号,定时发布内容、回复评论,节省大量的时间和精力。 与 Slack 集成 Browser-Use 还支持与 Slack 集成,方便团队协作。以下是集成的具体步骤: 1. 创建 Slack 应用 访问 https://api.slack.com/apps,点击 “Create New App”。 选择 “From scratch”,并为你的应用命名,选择要使用的工作空间。 提供机器人的名称和描述。 2. 配置机器人 导航到 “OAuth & Permissions” 选项卡,在 “Scopes” 中添加必要的机器人令牌范围,如 “chat:write”、“channels:history”、“im:history”。 3. 启用事件订阅 导航到 “Event Subscriptions” 选项卡,启用事件并添加必要的机器人事件,如 “message.channels”、“message.im”。 添加你的请求 URL(可以使用 ngrok 暴露本地服务器)。 4. 获取签名密钥和机器人令牌 导航到 “Basic Information” 选项卡,复制 “Signing Secret”。 导航到 “OAuth & Permissions” 选项卡,复制 “Bot User OAuth Token”。 5. 配置环境变量 在项目根目录下的 .env 文件中添加以下内容: SLACK_SIGNING_SECRET=your-signing-secret SLACK_BOT_TOKEN=your-bot-token 6. 邀请机器人到频道 在 Slack 频道中使用 /invite @your-bot-name 命令邀请机器人。 7. 运行代码 运行 examples/slack_example.py 启动机器人,然后在 Slack 频道中输入 $bu whats the weather in Tokyo? 即可开始一个 Browser-Use 任务并获取响应。 总结 Browser-Use 是一个功能强大、易于使用的开源项目,它为 AI 与浏览器的交互提供了一种简单而有效的方式。通过本地部署或云部署,我们可以在各种场景中使用 Browser-Use 实现自动化操作,提高工作效率和质量。同时,与 Slack 的集成也为团队协作带来了便利。 -
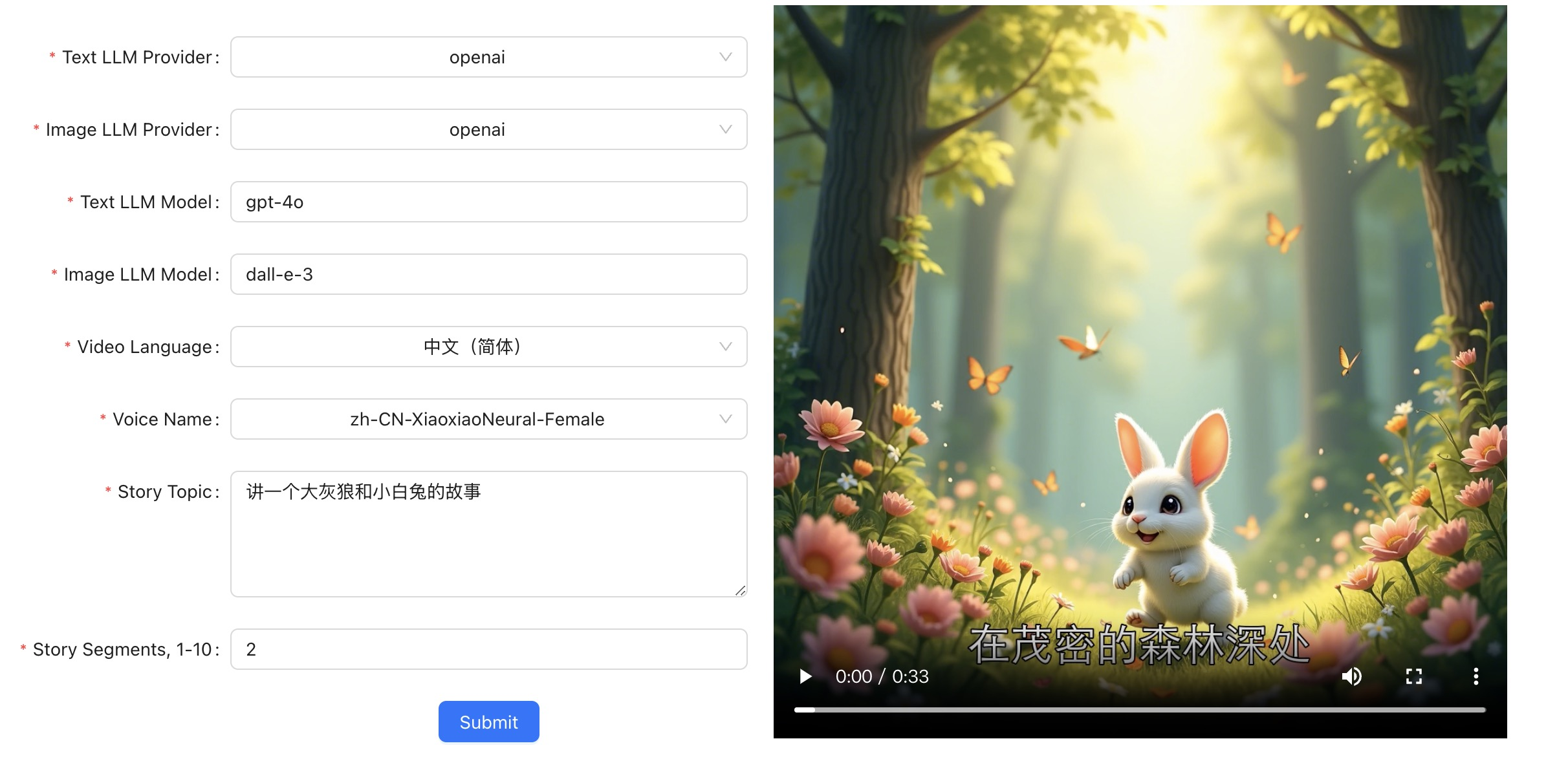 Story Flicks:一键生成故事视频的神器 在信息爆炸的时代,如何以生动有趣的方式呈现故事成为了许多人的追求。今天要给大家介绍的 Story Flicks 项目,就为我们提供了一个绝佳的解决方案。它能够让用户通过输入故事主题,利用大语言模型轻松生成包含 AI 图像、故事内容、音频和字幕的故事视频。 项目介绍 Story Flicks 是一个集故事创作与视频生成于一体的项目。用户只需输入一个故事主题,系统就能借助强大的大语言模型,自动生成精彩的故事内容,同时搭配 AI 生成的精美图片、合适的音频以及准确的字幕,最终合成一个完整的故事视频。 技术栈 后端:采用 Python + FastAPI 框架构建,保证了系统的高效性和稳定性,能够快速处理用户的请求并生成所需的故事内容。 前端:基于 React + Ant Design + Vite 搭建,提供了简洁美观、易于操作的用户界面,让用户能够轻松上手。 视频示例 项目提供了两个精彩的视频示例,让我们先来一睹为快。 如果你无法看到该视频,那么可能你的电脑不支持该文件格式。 如果你无法看到该视频,那么可能你的电脑不支持该文件格式。 部署方法及具体步骤 1. 下载项目 首先,我们需要将项目克隆到本地。打开终端,执行以下命令: git clone https://github.com/alecm20/story-flicks.git 2. 设置模型信息 2.1 切换到后端目录 cd backend 2.2 复制环境变量示例文件 cp .env.example .env 2.3 编辑 .env 文件 在 .env 文件中,我们需要设置模型的相关信息,以下是详细的参数说明: text_provider = "openai" # 文本生成模型的提供商,目前支持 openai、aliyun、deepseek、ollama 和 siliconflow # 阿里云文档:https://www.aliyun.com/product/bailian image_provider = "aliyun" # 图像生成模型的提供商,目前支持 openai、aliyun 和 siliconflow openai_base_url="https://api.openai.com/v1" # OpenAI 的基础 URL aliyun_base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云的基础 URL deepseek_base_url="https://api.deepseek.com/v1" # DeepSeek 的基础 URL ollama_base_url="http://localhost:11434/v1" # Ollama 的基础 URL siliconflow_base_url="https://api.siliconflow.cn/v1" # SiliconFlow 的基础 URL openai_api_key= # OpenAI 的 API 密钥,只需提供一个密钥 aliyun_api_key= # 阿里云百炼的 API 密钥,只需提供一个密钥 deepseek_api_key= # DeepSeek 的 API 密钥,目前仅支持文本生成 ollama_api_key= # 如果需要使用,将 api_key 设置为 “ollama”。目前,此 API 密钥仅支持文本生成,不能用于参数过少的模型。建议使用 qwen2.5:14b 或更大的模型。 siliconflow_api_key= # SiliconFlow 的 API 密钥,SiliconFlow 的文本模型目前仅支持与 OpenAI 格式兼容的大模型,如图像模型仅对 black-forest-labs/FLUX.1-dev 进行了测试。 text_llm_model=gpt-4o # 如果 text_provider 设置为 openai,只能使用 OpenAI 模型,如 gpt-4o。如果选择阿里云,可以使用阿里云模型,如 qwen-plus 或 qwen-max。Ollama 模型不能使用参数过少的模型,建议使用 qwen2.5:14b 或更大的模型。 image_llm_model=flux-dev # 如果 image_provider 设置为 openai,只能使用 OpenAI 模型,如 dall-e-3。如果选择阿里云,建议使用阿里云模型,如 flux-dev,目前可免费试用。更多详情:https://help.aliyun.com/zh/model-studio/getting-started/models#a1a9f05a675m4。 3. 启动项目 3.1 手动启动后端项目 # 首先,切换到项目根目录 cd backend # 创建并激活虚拟环境 conda create -n story-flicks python=3.10 conda activate story-flicks # 安装依赖 pip install -r requirements.txt # 启动后端服务 uvicorn main:app --reload 如果项目启动成功,终端将输出以下信息: INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) INFO: Started reloader process using StatReload INFO: Started server process INFO: Waiting for application startup. INFO: Application startup complete. 项目优势 简单易用 用户只需输入故事主题,无需复杂的操作,即可快速生成故事视频,大大节省了时间和精力。 多样化的模型支持 支持多种文本和图像生成模型,用户可以根据自己的需求选择合适的模型,满足不同场景的创作需求。 丰富的功能 生成的视频包含 AI 图像、故事内容、音频和字幕,内容丰富多样,能够吸引观众的注意力。 总的来说,Story Flicks 是一个非常实用的故事视频生成项目,无论是个人创作者还是企业宣传,都能借助它轻松打造出精彩的故事视频。赶快动手部署,开启你的故事创作之旅吧!
Story Flicks:一键生成故事视频的神器 在信息爆炸的时代,如何以生动有趣的方式呈现故事成为了许多人的追求。今天要给大家介绍的 Story Flicks 项目,就为我们提供了一个绝佳的解决方案。它能够让用户通过输入故事主题,利用大语言模型轻松生成包含 AI 图像、故事内容、音频和字幕的故事视频。 项目介绍 Story Flicks 是一个集故事创作与视频生成于一体的项目。用户只需输入一个故事主题,系统就能借助强大的大语言模型,自动生成精彩的故事内容,同时搭配 AI 生成的精美图片、合适的音频以及准确的字幕,最终合成一个完整的故事视频。 技术栈 后端:采用 Python + FastAPI 框架构建,保证了系统的高效性和稳定性,能够快速处理用户的请求并生成所需的故事内容。 前端:基于 React + Ant Design + Vite 搭建,提供了简洁美观、易于操作的用户界面,让用户能够轻松上手。 视频示例 项目提供了两个精彩的视频示例,让我们先来一睹为快。 如果你无法看到该视频,那么可能你的电脑不支持该文件格式。 如果你无法看到该视频,那么可能你的电脑不支持该文件格式。 部署方法及具体步骤 1. 下载项目 首先,我们需要将项目克隆到本地。打开终端,执行以下命令: git clone https://github.com/alecm20/story-flicks.git 2. 设置模型信息 2.1 切换到后端目录 cd backend 2.2 复制环境变量示例文件 cp .env.example .env 2.3 编辑 .env 文件 在 .env 文件中,我们需要设置模型的相关信息,以下是详细的参数说明: text_provider = "openai" # 文本生成模型的提供商,目前支持 openai、aliyun、deepseek、ollama 和 siliconflow # 阿里云文档:https://www.aliyun.com/product/bailian image_provider = "aliyun" # 图像生成模型的提供商,目前支持 openai、aliyun 和 siliconflow openai_base_url="https://api.openai.com/v1" # OpenAI 的基础 URL aliyun_base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云的基础 URL deepseek_base_url="https://api.deepseek.com/v1" # DeepSeek 的基础 URL ollama_base_url="http://localhost:11434/v1" # Ollama 的基础 URL siliconflow_base_url="https://api.siliconflow.cn/v1" # SiliconFlow 的基础 URL openai_api_key= # OpenAI 的 API 密钥,只需提供一个密钥 aliyun_api_key= # 阿里云百炼的 API 密钥,只需提供一个密钥 deepseek_api_key= # DeepSeek 的 API 密钥,目前仅支持文本生成 ollama_api_key= # 如果需要使用,将 api_key 设置为 “ollama”。目前,此 API 密钥仅支持文本生成,不能用于参数过少的模型。建议使用 qwen2.5:14b 或更大的模型。 siliconflow_api_key= # SiliconFlow 的 API 密钥,SiliconFlow 的文本模型目前仅支持与 OpenAI 格式兼容的大模型,如图像模型仅对 black-forest-labs/FLUX.1-dev 进行了测试。 text_llm_model=gpt-4o # 如果 text_provider 设置为 openai,只能使用 OpenAI 模型,如 gpt-4o。如果选择阿里云,可以使用阿里云模型,如 qwen-plus 或 qwen-max。Ollama 模型不能使用参数过少的模型,建议使用 qwen2.5:14b 或更大的模型。 image_llm_model=flux-dev # 如果 image_provider 设置为 openai,只能使用 OpenAI 模型,如 dall-e-3。如果选择阿里云,建议使用阿里云模型,如 flux-dev,目前可免费试用。更多详情:https://help.aliyun.com/zh/model-studio/getting-started/models#a1a9f05a675m4。 3. 启动项目 3.1 手动启动后端项目 # 首先,切换到项目根目录 cd backend # 创建并激活虚拟环境 conda create -n story-flicks python=3.10 conda activate story-flicks # 安装依赖 pip install -r requirements.txt # 启动后端服务 uvicorn main:app --reload 如果项目启动成功,终端将输出以下信息: INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) INFO: Started reloader process using StatReload INFO: Started server process INFO: Waiting for application startup. INFO: Application startup complete. 项目优势 简单易用 用户只需输入故事主题,无需复杂的操作,即可快速生成故事视频,大大节省了时间和精力。 多样化的模型支持 支持多种文本和图像生成模型,用户可以根据自己的需求选择合适的模型,满足不同场景的创作需求。 丰富的功能 生成的视频包含 AI 图像、故事内容、音频和字幕,内容丰富多样,能够吸引观众的注意力。 总的来说,Story Flicks 是一个非常实用的故事视频生成项目,无论是个人创作者还是企业宣传,都能借助它轻松打造出精彩的故事视频。赶快动手部署,开启你的故事创作之旅吧! -
 OpenManus 项目部署详细教程 一、项目简介 OpenManus 是一个功能强大的多功能智能代理项目,由来自 MetaGPT 等组织的开发者共同构建。其原型在 3 小时内就已推出,并且团队一直在持续完善。借助 OpenManus,用户无需邀请码就能利用各种工具解决各类任务,实现各种创意。此外,还有与之相关的 OpenManus - RL 开源项目,专注于基于强化学习(如 GRPO)的大语言模型代理调优方法。 二、部署前准备 (一)系统要求 确保你的系统已经安装了以下软件和工具: Python 3.12:OpenManus 项目要求 Python 版本至少为 3.12。 Conda 或 uv:Conda 是一个常用的环境管理工具,而 uv 是一个快速的 Python 包管理器,推荐使用 uv 进行部署。 (二)API 密钥 你需要准备好所使用的大语言模型(LLM)的 API 密钥,例如 OpenAI 的 API 密钥。 不同的大语言模型获取 API 密钥的方式有所不同,以下为你详细介绍几个常见大语言模型 API 密钥的获取方法: 1、OpenAI API 密钥获取 OpenAI 提供了强大的语言模型,如 GPT - 3.5、GPT - 4 等。 步骤 注册账号 访问 OpenAI 官网,点击右上角的 “Sign up” 按钮。 按照提示填写邮箱、设置密码等信息完成注册。注册过程中可能需要进行邮箱验证。 登录控制台 注册成功后,使用注册的账号和密码登录 OpenAI 控制台。 创建 API 密钥 登录控制台后,点击右上角的个人头像,在下拉菜单中选择 “API keys”。 在 API keys 页面,点击 “Create new secret key” 按钮。 输入一个密钥名称(可选),然后点击 “Create secret key”。 此时会弹出一个窗口显示新生成的 API 密钥,这个密钥只会显示一次,务必妥善保存,之后可以将其用于 OpenManus 项目的配置文件中。 注意事项 OpenAI 使用的是付费模式,在使用 API 时会根据使用的额度进行计费。可以在控制台的 “Usage” 页面查看使用情况和费用。 API 密钥是访问 OpenAI 服务的重要凭证,不要将其泄露给他人,以免造成不必要的费用损失。 2、百度千帆大模型平台(以文心一言为例) 百度千帆提供了多种大模型服务,文心一言是其中较为知名的。 步骤 注册并登录 访问 百度千帆大模型平台,点击右上角的 “注册” 按钮,使用百度账号进行注册登录。如果已有百度账号,直接登录即可。 创建应用 登录后,进入控制台,在左侧导航栏中找到 “应用管理” 并点击。 点击 “创建应用” 按钮,填写应用名称、描述等信息,选择所需的模型(如文心一言),点击 “创建”。 获取 API 信息 创建应用成功后,在应用列表中找到刚刚创建的应用,点击进入应用详情页。 在应用详情页中,可以看到 “API Key” 和 “Secret Key”,这两个密钥组合起来用于调用 API 服务。 注意事项 百度千帆平台也有不同的计费策略,使用前需要了解清楚费用情况。 同样要妥善保管好 API Key 和 Secret Key,避免泄露。 3、阿里云通义千问 阿里云的通义千问也是一款优秀的大语言模型。 步骤 注册并开通服务 访问 阿里云官网,注册并登录阿里云账号。 搜索 “通义千问”,进入通义千问的产品页面,点击 “立即开通” 按钮,按照提示完成服务开通流程。 创建 AccessKey 登录阿里云控制台,点击右上角的个人头像,在下拉菜单中选择 “AccessKey 管理”。 如果之前没有创建过 AccessKey,点击 “创建 AccessKey” 按钮,根据提示完成身份验证后生成 AccessKey ID 和 AccessKey Secret。 使用 API 通过阿里云的 SDK 或 API 调用通义千问服务时,使用生成的 AccessKey ID 和 AccessKey Secret 进行身份验证。 注意事项 阿里云的服务使用会根据具体的用量进行计费,需要关注费用情况。 AccessKey 是访问阿里云服务的重要凭证,要严格保密,定期更换。 三、部署步骤 (一)方式一:使用 Conda 部署 创建新的 Conda 环境 打开终端,执行以下命令创建一个名为 open_manus 的 Conda 环境,并激活该环境: bash conda create -n open_manus python=3.12 conda activate open_manus 注意事项: 确保你的 Conda 已经正确安装并且配置好了环境变量,否则可能会提示 conda 命令找不到。 如果创建环境时提示磁盘空间不足,需要清理磁盘或者更换磁盘空间充足的路径创建环境。 克隆仓库 使用 git 命令将 OpenManus 项目的仓库克隆到本地,并进入项目目录: bash git clone https://github.com/mannaandpoem/OpenManus.git cd OpenManus 注意事项: 确保你的网络可以正常访问 GitHub,否则可能会出现克隆失败的情况。你可以尝试使用代理或者切换网络环境。 如果本地已经存在同名的文件夹,克隆操作可能会失败,建议提前删除或者重命名该文件夹。 安装依赖 在项目目录下,使用 pip 安装项目所需的依赖: bash pip install -r requirements.txt 注意事项: 安装依赖可能需要一些时间,具体取决于你的网络速度和服务器响应情况。 如果安装过程中出现依赖冲突的错误,可能是因为某些依赖版本不兼容。可以尝试更新 pip 到最新版本,或者手动指定依赖的版本。 (二)方式二:使用 uv 部署(推荐) 安装 uv 在终端中运行以下命令安装 uv: bash curl -LsSf https://astral.sh/uv/install.sh | sh 注意事项: 确保你的系统中已经安装了 curl 工具,否则命令会执行失败。可以使用 sudo apt-get install curl(Ubuntu/Debian)或者 brew install curl(macOS)来安装。 安装过程可能需要管理员权限,根据提示输入密码进行确认。 克隆仓库 同样使用 git 命令克隆项目仓库并进入项目目录: bash git clone https://github.com/mannaandpoem/OpenManus.git cd OpenManus 注意事项:与使用 Conda 部署时克隆仓库的注意事项相同,确保网络和本地文件夹情况正常。 3. 创建并激活虚拟环境 使用 uv 命令创建虚拟环境,并根据不同的操作系统激活该环境: bash uv venv source .venv/bin/activate # Unix/macOS 系统 Windows 系统使用: .venv\Scripts\activate 注意事项: 对于 Windows 系统,确保在命令提示符或者 PowerShell 中以管理员身份运行,否则可能会出现权限不足的错误。 如果激活虚拟环境后,命令行前缀没有显示虚拟环境名称,可能是激活失败,可以尝试重新执行激活命令。 安装依赖 使用 uv 安装项目所需的依赖: bash uv pip install -r requirements.txt 注意事项:与使用 pip 安装依赖的注意事项类似,关注网络和依赖冲突问题。 四、配置项目 OpenManus 项目需要对所使用的大语言模型(LLM)API 进行配置,具体步骤如下: 创建配置文件 在 config 目录下创建 config.toml 文件,你可以从示例文件复制一份: bash cp config/config.example.toml config/config.toml 注意事项: 确保 config 目录存在,并且你有足够的权限在该目录下创建文件。 复制文件时,要注意文件路径是否正确,避免复制到错误的位置。 编辑配置文件 使用文本编辑器打开 config/config.toml 文件,添加你的 API 密钥并自定义相关设置。以下是一个示例配置: toml #Global LLM configuration [ llm ] model = "gpt-4o" base_url = "https://api.openai.com/v1" api_key = "sk-..." # Replace with your actual API key max_tokens = 4096 temperature = 0.0 #Optional configuration for specific LLM models [ llm.vision ] model = "gpt-4o" base_url = "https://api.openai.com/v1" api_key = "sk-..." # Replace with your actual API key 注意事项: 确保 API 密钥的准确性,任何错误或者遗漏都可能导致 API 认证失败。 不要将包含 API 密钥的配置文件公开分享,以免造成安全风险。 五、启动项目 完成部署和配置后,就可以启动 OpenManus 项目了。 (一)稳定版本启动 在终端中输入以下命令启动稳定版本: bash python main.py 启动后,你可以通过终端输入你的创意,即可开始使用 OpenManus 解决任务。 注意事项: 如果启动过程中出现 ModuleNotFoundError 错误,说明可能有依赖没有正确安装,需要检查并重新安装依赖。 确保你的 API 密钥有效且具有足够的权限,否则可能会在使用过程中遇到请求失败的问题。 (二)开发中版本启动 如果想体验开发中版本,可以运行以下命令: bash python run_flow.py 注意事项:开发中版本可能存在一些不稳定因素,遇到问题可以及时反馈给项目开发者。 六、常见问题及解决方法 (一)依赖安装失败 问题描述:在使用 pip 或 uv 安装依赖时出现错误。 解决方法:检查网络连接是否正常,确保可以访问所需的软件源。如果使用的是国内网络,可以考虑更换为国内的镜像源,例如使用清华大学的 PyPI 镜像源: bash pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple (二)API 密钥配置错误 问题描述:启动项目后提示 API 认证失败。 解决方法:检查 config.toml 文件中的 API 密钥是否正确,确保没有遗漏或输入错误。同时,要注意 API 密钥的有效期和权限。 七、总结 希望本教程能帮助你顺利部署 OpenManus 项目,享受智能代理带来的便利!
OpenManus 项目部署详细教程 一、项目简介 OpenManus 是一个功能强大的多功能智能代理项目,由来自 MetaGPT 等组织的开发者共同构建。其原型在 3 小时内就已推出,并且团队一直在持续完善。借助 OpenManus,用户无需邀请码就能利用各种工具解决各类任务,实现各种创意。此外,还有与之相关的 OpenManus - RL 开源项目,专注于基于强化学习(如 GRPO)的大语言模型代理调优方法。 二、部署前准备 (一)系统要求 确保你的系统已经安装了以下软件和工具: Python 3.12:OpenManus 项目要求 Python 版本至少为 3.12。 Conda 或 uv:Conda 是一个常用的环境管理工具,而 uv 是一个快速的 Python 包管理器,推荐使用 uv 进行部署。 (二)API 密钥 你需要准备好所使用的大语言模型(LLM)的 API 密钥,例如 OpenAI 的 API 密钥。 不同的大语言模型获取 API 密钥的方式有所不同,以下为你详细介绍几个常见大语言模型 API 密钥的获取方法: 1、OpenAI API 密钥获取 OpenAI 提供了强大的语言模型,如 GPT - 3.5、GPT - 4 等。 步骤 注册账号 访问 OpenAI 官网,点击右上角的 “Sign up” 按钮。 按照提示填写邮箱、设置密码等信息完成注册。注册过程中可能需要进行邮箱验证。 登录控制台 注册成功后,使用注册的账号和密码登录 OpenAI 控制台。 创建 API 密钥 登录控制台后,点击右上角的个人头像,在下拉菜单中选择 “API keys”。 在 API keys 页面,点击 “Create new secret key” 按钮。 输入一个密钥名称(可选),然后点击 “Create secret key”。 此时会弹出一个窗口显示新生成的 API 密钥,这个密钥只会显示一次,务必妥善保存,之后可以将其用于 OpenManus 项目的配置文件中。 注意事项 OpenAI 使用的是付费模式,在使用 API 时会根据使用的额度进行计费。可以在控制台的 “Usage” 页面查看使用情况和费用。 API 密钥是访问 OpenAI 服务的重要凭证,不要将其泄露给他人,以免造成不必要的费用损失。 2、百度千帆大模型平台(以文心一言为例) 百度千帆提供了多种大模型服务,文心一言是其中较为知名的。 步骤 注册并登录 访问 百度千帆大模型平台,点击右上角的 “注册” 按钮,使用百度账号进行注册登录。如果已有百度账号,直接登录即可。 创建应用 登录后,进入控制台,在左侧导航栏中找到 “应用管理” 并点击。 点击 “创建应用” 按钮,填写应用名称、描述等信息,选择所需的模型(如文心一言),点击 “创建”。 获取 API 信息 创建应用成功后,在应用列表中找到刚刚创建的应用,点击进入应用详情页。 在应用详情页中,可以看到 “API Key” 和 “Secret Key”,这两个密钥组合起来用于调用 API 服务。 注意事项 百度千帆平台也有不同的计费策略,使用前需要了解清楚费用情况。 同样要妥善保管好 API Key 和 Secret Key,避免泄露。 3、阿里云通义千问 阿里云的通义千问也是一款优秀的大语言模型。 步骤 注册并开通服务 访问 阿里云官网,注册并登录阿里云账号。 搜索 “通义千问”,进入通义千问的产品页面,点击 “立即开通” 按钮,按照提示完成服务开通流程。 创建 AccessKey 登录阿里云控制台,点击右上角的个人头像,在下拉菜单中选择 “AccessKey 管理”。 如果之前没有创建过 AccessKey,点击 “创建 AccessKey” 按钮,根据提示完成身份验证后生成 AccessKey ID 和 AccessKey Secret。 使用 API 通过阿里云的 SDK 或 API 调用通义千问服务时,使用生成的 AccessKey ID 和 AccessKey Secret 进行身份验证。 注意事项 阿里云的服务使用会根据具体的用量进行计费,需要关注费用情况。 AccessKey 是访问阿里云服务的重要凭证,要严格保密,定期更换。 三、部署步骤 (一)方式一:使用 Conda 部署 创建新的 Conda 环境 打开终端,执行以下命令创建一个名为 open_manus 的 Conda 环境,并激活该环境: bash conda create -n open_manus python=3.12 conda activate open_manus 注意事项: 确保你的 Conda 已经正确安装并且配置好了环境变量,否则可能会提示 conda 命令找不到。 如果创建环境时提示磁盘空间不足,需要清理磁盘或者更换磁盘空间充足的路径创建环境。 克隆仓库 使用 git 命令将 OpenManus 项目的仓库克隆到本地,并进入项目目录: bash git clone https://github.com/mannaandpoem/OpenManus.git cd OpenManus 注意事项: 确保你的网络可以正常访问 GitHub,否则可能会出现克隆失败的情况。你可以尝试使用代理或者切换网络环境。 如果本地已经存在同名的文件夹,克隆操作可能会失败,建议提前删除或者重命名该文件夹。 安装依赖 在项目目录下,使用 pip 安装项目所需的依赖: bash pip install -r requirements.txt 注意事项: 安装依赖可能需要一些时间,具体取决于你的网络速度和服务器响应情况。 如果安装过程中出现依赖冲突的错误,可能是因为某些依赖版本不兼容。可以尝试更新 pip 到最新版本,或者手动指定依赖的版本。 (二)方式二:使用 uv 部署(推荐) 安装 uv 在终端中运行以下命令安装 uv: bash curl -LsSf https://astral.sh/uv/install.sh | sh 注意事项: 确保你的系统中已经安装了 curl 工具,否则命令会执行失败。可以使用 sudo apt-get install curl(Ubuntu/Debian)或者 brew install curl(macOS)来安装。 安装过程可能需要管理员权限,根据提示输入密码进行确认。 克隆仓库 同样使用 git 命令克隆项目仓库并进入项目目录: bash git clone https://github.com/mannaandpoem/OpenManus.git cd OpenManus 注意事项:与使用 Conda 部署时克隆仓库的注意事项相同,确保网络和本地文件夹情况正常。 3. 创建并激活虚拟环境 使用 uv 命令创建虚拟环境,并根据不同的操作系统激活该环境: bash uv venv source .venv/bin/activate # Unix/macOS 系统 Windows 系统使用: .venv\Scripts\activate 注意事项: 对于 Windows 系统,确保在命令提示符或者 PowerShell 中以管理员身份运行,否则可能会出现权限不足的错误。 如果激活虚拟环境后,命令行前缀没有显示虚拟环境名称,可能是激活失败,可以尝试重新执行激活命令。 安装依赖 使用 uv 安装项目所需的依赖: bash uv pip install -r requirements.txt 注意事项:与使用 pip 安装依赖的注意事项类似,关注网络和依赖冲突问题。 四、配置项目 OpenManus 项目需要对所使用的大语言模型(LLM)API 进行配置,具体步骤如下: 创建配置文件 在 config 目录下创建 config.toml 文件,你可以从示例文件复制一份: bash cp config/config.example.toml config/config.toml 注意事项: 确保 config 目录存在,并且你有足够的权限在该目录下创建文件。 复制文件时,要注意文件路径是否正确,避免复制到错误的位置。 编辑配置文件 使用文本编辑器打开 config/config.toml 文件,添加你的 API 密钥并自定义相关设置。以下是一个示例配置: toml #Global LLM configuration [ llm ] model = "gpt-4o" base_url = "https://api.openai.com/v1" api_key = "sk-..." # Replace with your actual API key max_tokens = 4096 temperature = 0.0 #Optional configuration for specific LLM models [ llm.vision ] model = "gpt-4o" base_url = "https://api.openai.com/v1" api_key = "sk-..." # Replace with your actual API key 注意事项: 确保 API 密钥的准确性,任何错误或者遗漏都可能导致 API 认证失败。 不要将包含 API 密钥的配置文件公开分享,以免造成安全风险。 五、启动项目 完成部署和配置后,就可以启动 OpenManus 项目了。 (一)稳定版本启动 在终端中输入以下命令启动稳定版本: bash python main.py 启动后,你可以通过终端输入你的创意,即可开始使用 OpenManus 解决任务。 注意事项: 如果启动过程中出现 ModuleNotFoundError 错误,说明可能有依赖没有正确安装,需要检查并重新安装依赖。 确保你的 API 密钥有效且具有足够的权限,否则可能会在使用过程中遇到请求失败的问题。 (二)开发中版本启动 如果想体验开发中版本,可以运行以下命令: bash python run_flow.py 注意事项:开发中版本可能存在一些不稳定因素,遇到问题可以及时反馈给项目开发者。 六、常见问题及解决方法 (一)依赖安装失败 问题描述:在使用 pip 或 uv 安装依赖时出现错误。 解决方法:检查网络连接是否正常,确保可以访问所需的软件源。如果使用的是国内网络,可以考虑更换为国内的镜像源,例如使用清华大学的 PyPI 镜像源: bash pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple (二)API 密钥配置错误 问题描述:启动项目后提示 API 认证失败。 解决方法:检查 config.toml 文件中的 API 密钥是否正确,确保没有遗漏或输入错误。同时,要注意 API 密钥的有效期和权限。 七、总结 希望本教程能帮助你顺利部署 OpenManus 项目,享受智能代理带来的便利! -
 DeepSeek 满血版本地化傻瓜式可视化部署方案 DeepSeek满血版本地化傻瓜式可视化部署方案 一、方案背景与目标 背景 DeepSeek作为先进的大语言模型,具备强大的语言理解和生成能力。将其进行本地化部署,能够在保障数据安全和隐私的同时,满足特定场景下的高效使用需求。本方案旨在为非专业技术人员提供一种简单、直观的方式,实现DeepSeek满血版的本地部署与使用。 目标 通过傻瓜式、可视化的部署流程,让用户能够轻松在本地环境搭建DeepSeek模型,并通过可视化界面与之交互,完成文本生成、问答等任务。 二、准备工作 硬件要求 硬件组件 推荐配置 说明 CPU Intel Core i7 及以上或 AMD Ryzen 7 及以上 多核心处理器可加速模型推理过程 内存 16GB 及以上 足够的内存可避免因内存不足导致的程序崩溃 硬盘 512GB 及以上 SSD 快速的读写速度可加快模型文件加载和数据处理 GPU NVIDIA GeForce RTX 3060 及以上 支持 CUDA 加速,显著提升模型运行效率 网络 稳定的宽带网络 用于下载软件、代码和模型文件 软件准备 Anaconda Anaconda 是一个开源的 Python 发行版本,包含了 Python、众多科学计算库以及包管理工具 conda。 下载:访问 Anaconda 官网(https://www.anaconda.com/download ),根据自己的操作系统(Windows、Mac OS、Linux)选择对应的安装包进行下载。 安装:运行下载好的安装包,按照安装向导的提示进行操作。在安装过程中,建议勾选“Add Anaconda to my PATH environment variable”选项,以便在命令行中可以直接使用 conda 命令。 Git 客户端 Git 是一种分布式版本控制系统,用于管理代码的版本和协作开发。 下载:访问 Git 官网(https://git-scm.com/downloads ),选择适合自己操作系统的版本进行下载。 安装:运行下载好的安装包,按照默认设置完成安装。安装完成后,在命令行中输入 git --version 验证安装是否成功。 NVIDIA 驱动 如果你的计算机配备了 NVIDIA GPU,需要安装相应的驱动程序以支持 CUDA 加速。 下载:访问 NVIDIA 官网(https://www.nvidia.com/Download/index.aspx ),根据自己的 GPU 型号、操作系统和 CUDA 版本选择合适的驱动程序进行下载。 安装:运行下载好的驱动程序安装包,按照安装向导的提示完成安装。安装完成后,在命令行中输入 nvidia-smi 验证驱动是否安装成功。 CUDA 和 cuDNN(可选但推荐) CUDA 是 NVIDIA 推出的并行计算平台和编程模型,cuDNN 是 NVIDIA 提供的深度神经网络库,它们可以显著加速基于 GPU 的深度学习模型训练和推理。 CUDA 安装:访问 NVIDIA CUDA 官网(https://developer.nvidia.com/cuda-downloads ),选择适合自己操作系统的 CUDA 版本进行下载和安装。安装过程中按照提示进行操作,注意记录安装路径。 cuDNN 安装:访问 NVIDIA cuDNN 官网(https://developer.nvidia.com/cudnn ),注册并登录后下载与 CUDA 版本兼容的 cuDNN 库。将下载的压缩包解压后,将其中的文件复制到 CUDA 安装目录对应的文件夹中。 三、部署步骤 1. 创建并激活 Anaconda 环境 打开 Anaconda Prompt(Windows)或终端(Mac OS、Linux)。 输入以下命令创建一个名为 deepseek_env 的 Python 3.8 环境: conda create -n deepseek_env python=3.8 输入以下命令激活该环境: conda activate deepseek_env 2. 获取 DeepSeek 代码 在激活的 Anaconda 环境下,打开 Git Bash(Windows)或终端(Mac OS、Linux)。 输入以下命令将 DeepSeek 代码克隆到本地: git clone <DeepSeek代码仓库地址> 请将 <DeepSeek代码仓库地址> 替换为 DeepSeek 官方提供的真实代码仓库链接。如果代码仓库是私有的,可能需要输入用户名和密码进行身份验证。 3. 安装依赖包 进入克隆下来的 DeepSeek 代码目录,例如: cd deepseek 输入以下命令安装运行所需的依赖包: pip install -r requirements.txt 安装过程可能会持续一段时间,具体时间取决于网络速度和依赖包的数量。如果在安装过程中遇到问题,可以尝试使用国内镜像源加速下载,例如: pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple 4. 下载模型文件 从 DeepSeek 官方指定的模型下载地址获取满血版模型文件。这些文件可能包含模型权重、配置文件等。 创建一个 models 文件夹用于存放模型文件: mkdir models 将下载好的模型文件解压到 models 文件夹中。确保文件路径与代码中配置的模型路径一致。 5. 配置环境变量(可选) 如果安装了 CUDA 和 cuDNN,需要配置相应的环境变量,以便程序能够正确找到这些库。 在 Windows 系统中,右键点击“此电脑”,选择“属性” -> “高级系统设置” -> “环境变量”,在系统变量中添加以下变量: CUDA_PATH:指向 CUDA 安装目录,例如 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7 PATH:在原有的 PATH 变量中添加 %CUDA_PATH%\bin 和 %CUDA_PATH%\libnvvp 在 Linux 或 Mac OS 系统中,编辑 ~/.bashrc 或 ~/.zshrc 文件,添加以下内容: export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH 然后执行 source ~/.bashrc 或 source ~/.zshrc 使配置生效。 6. 启动可视化界面 在代码目录下,输入以下命令启动可视化界面: python app.py 启动成功后,会在命令行中显示一个本地链接,如 http://127.0.0.1:7860。 打开浏览器,输入该链接,即可看到 DeepSeek 的可视化界面。 四、测试与优化 简单测试 在可视化界面中输入一些测试文本,例如:“介绍一下人工智能”,然后点击生成按钮。 观察生成结果是否符合预期,包括文本的逻辑性、语法正确性和相关性。 如果生成结果出现错误或不符合要求,可以尝试调整输入文本的表述方式或修改模型的参数设置。 性能优化 调整模型参数 在可视化界面的设置选项中,通常可以找到一些模型参数,如生成的最大长度、采样温度等。 最大长度:适当降低最大长度可以减少生成时间,但可能会导致生成的文本不够完整。 采样温度:降低采样温度可以使生成的文本更加确定和保守,提高采样温度可以使生成的文本更加多样化和随机。 资源管理 定期清理缓存文件,释放硬盘空间。可在代码目录下找到缓存文件夹进行清理。 关闭不必要的后台程序,以确保计算机有足够的资源用于运行 DeepSeek 模型。 硬件升级 如果在使用过程中发现性能仍然无法满足需求,可以考虑升级硬件,如增加内存、更换更强大的 GPU 等。 五、常见问题及解决方法 依赖包安装失败 问题描述:在执行 pip install -r requirements.txt 时,部分依赖包安装失败。 解决方法: 检查网络连接是否稳定,尝试使用国内镜像源加速下载。 查看错误信息,可能是某些依赖包版本不兼容。可以尝试手动安装指定版本的依赖包,例如 pip install package_name==version_number。 模型文件加载失败 问题描述:启动可视化界面时,提示模型文件加载失败。 解决方法: 检查模型文件是否完整下载并解压到正确的目录。 确保代码中配置的模型路径与实际模型文件路径一致。 GPU 加速未生效 问题描述:计算机配备了 NVIDIA GPU,但在运行过程中未使用 GPU 加速。 解决方法: 检查 NVIDIA 驱动、CUDA 和 cuDNN 是否正确安装并配置。 在代码中添加相应的 GPU 配置代码,例如: import torch device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device) 六、总结 通过以上步骤,你可以轻松地在本地环境实现 DeepSeek 满血版的傻瓜式、可视化部署。在部署过程中,按照准备工作的要求确保硬件和软件环境的正确性,严格遵循部署步骤进行操作。遇到问题时,参考常见问题及解决方法进行排查和修复。
DeepSeek 满血版本地化傻瓜式可视化部署方案 DeepSeek满血版本地化傻瓜式可视化部署方案 一、方案背景与目标 背景 DeepSeek作为先进的大语言模型,具备强大的语言理解和生成能力。将其进行本地化部署,能够在保障数据安全和隐私的同时,满足特定场景下的高效使用需求。本方案旨在为非专业技术人员提供一种简单、直观的方式,实现DeepSeek满血版的本地部署与使用。 目标 通过傻瓜式、可视化的部署流程,让用户能够轻松在本地环境搭建DeepSeek模型,并通过可视化界面与之交互,完成文本生成、问答等任务。 二、准备工作 硬件要求 硬件组件 推荐配置 说明 CPU Intel Core i7 及以上或 AMD Ryzen 7 及以上 多核心处理器可加速模型推理过程 内存 16GB 及以上 足够的内存可避免因内存不足导致的程序崩溃 硬盘 512GB 及以上 SSD 快速的读写速度可加快模型文件加载和数据处理 GPU NVIDIA GeForce RTX 3060 及以上 支持 CUDA 加速,显著提升模型运行效率 网络 稳定的宽带网络 用于下载软件、代码和模型文件 软件准备 Anaconda Anaconda 是一个开源的 Python 发行版本,包含了 Python、众多科学计算库以及包管理工具 conda。 下载:访问 Anaconda 官网(https://www.anaconda.com/download ),根据自己的操作系统(Windows、Mac OS、Linux)选择对应的安装包进行下载。 安装:运行下载好的安装包,按照安装向导的提示进行操作。在安装过程中,建议勾选“Add Anaconda to my PATH environment variable”选项,以便在命令行中可以直接使用 conda 命令。 Git 客户端 Git 是一种分布式版本控制系统,用于管理代码的版本和协作开发。 下载:访问 Git 官网(https://git-scm.com/downloads ),选择适合自己操作系统的版本进行下载。 安装:运行下载好的安装包,按照默认设置完成安装。安装完成后,在命令行中输入 git --version 验证安装是否成功。 NVIDIA 驱动 如果你的计算机配备了 NVIDIA GPU,需要安装相应的驱动程序以支持 CUDA 加速。 下载:访问 NVIDIA 官网(https://www.nvidia.com/Download/index.aspx ),根据自己的 GPU 型号、操作系统和 CUDA 版本选择合适的驱动程序进行下载。 安装:运行下载好的驱动程序安装包,按照安装向导的提示完成安装。安装完成后,在命令行中输入 nvidia-smi 验证驱动是否安装成功。 CUDA 和 cuDNN(可选但推荐) CUDA 是 NVIDIA 推出的并行计算平台和编程模型,cuDNN 是 NVIDIA 提供的深度神经网络库,它们可以显著加速基于 GPU 的深度学习模型训练和推理。 CUDA 安装:访问 NVIDIA CUDA 官网(https://developer.nvidia.com/cuda-downloads ),选择适合自己操作系统的 CUDA 版本进行下载和安装。安装过程中按照提示进行操作,注意记录安装路径。 cuDNN 安装:访问 NVIDIA cuDNN 官网(https://developer.nvidia.com/cudnn ),注册并登录后下载与 CUDA 版本兼容的 cuDNN 库。将下载的压缩包解压后,将其中的文件复制到 CUDA 安装目录对应的文件夹中。 三、部署步骤 1. 创建并激活 Anaconda 环境 打开 Anaconda Prompt(Windows)或终端(Mac OS、Linux)。 输入以下命令创建一个名为 deepseek_env 的 Python 3.8 环境: conda create -n deepseek_env python=3.8 输入以下命令激活该环境: conda activate deepseek_env 2. 获取 DeepSeek 代码 在激活的 Anaconda 环境下,打开 Git Bash(Windows)或终端(Mac OS、Linux)。 输入以下命令将 DeepSeek 代码克隆到本地: git clone <DeepSeek代码仓库地址> 请将 <DeepSeek代码仓库地址> 替换为 DeepSeek 官方提供的真实代码仓库链接。如果代码仓库是私有的,可能需要输入用户名和密码进行身份验证。 3. 安装依赖包 进入克隆下来的 DeepSeek 代码目录,例如: cd deepseek 输入以下命令安装运行所需的依赖包: pip install -r requirements.txt 安装过程可能会持续一段时间,具体时间取决于网络速度和依赖包的数量。如果在安装过程中遇到问题,可以尝试使用国内镜像源加速下载,例如: pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple 4. 下载模型文件 从 DeepSeek 官方指定的模型下载地址获取满血版模型文件。这些文件可能包含模型权重、配置文件等。 创建一个 models 文件夹用于存放模型文件: mkdir models 将下载好的模型文件解压到 models 文件夹中。确保文件路径与代码中配置的模型路径一致。 5. 配置环境变量(可选) 如果安装了 CUDA 和 cuDNN,需要配置相应的环境变量,以便程序能够正确找到这些库。 在 Windows 系统中,右键点击“此电脑”,选择“属性” -> “高级系统设置” -> “环境变量”,在系统变量中添加以下变量: CUDA_PATH:指向 CUDA 安装目录,例如 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7 PATH:在原有的 PATH 变量中添加 %CUDA_PATH%\bin 和 %CUDA_PATH%\libnvvp 在 Linux 或 Mac OS 系统中,编辑 ~/.bashrc 或 ~/.zshrc 文件,添加以下内容: export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH 然后执行 source ~/.bashrc 或 source ~/.zshrc 使配置生效。 6. 启动可视化界面 在代码目录下,输入以下命令启动可视化界面: python app.py 启动成功后,会在命令行中显示一个本地链接,如 http://127.0.0.1:7860。 打开浏览器,输入该链接,即可看到 DeepSeek 的可视化界面。 四、测试与优化 简单测试 在可视化界面中输入一些测试文本,例如:“介绍一下人工智能”,然后点击生成按钮。 观察生成结果是否符合预期,包括文本的逻辑性、语法正确性和相关性。 如果生成结果出现错误或不符合要求,可以尝试调整输入文本的表述方式或修改模型的参数设置。 性能优化 调整模型参数 在可视化界面的设置选项中,通常可以找到一些模型参数,如生成的最大长度、采样温度等。 最大长度:适当降低最大长度可以减少生成时间,但可能会导致生成的文本不够完整。 采样温度:降低采样温度可以使生成的文本更加确定和保守,提高采样温度可以使生成的文本更加多样化和随机。 资源管理 定期清理缓存文件,释放硬盘空间。可在代码目录下找到缓存文件夹进行清理。 关闭不必要的后台程序,以确保计算机有足够的资源用于运行 DeepSeek 模型。 硬件升级 如果在使用过程中发现性能仍然无法满足需求,可以考虑升级硬件,如增加内存、更换更强大的 GPU 等。 五、常见问题及解决方法 依赖包安装失败 问题描述:在执行 pip install -r requirements.txt 时,部分依赖包安装失败。 解决方法: 检查网络连接是否稳定,尝试使用国内镜像源加速下载。 查看错误信息,可能是某些依赖包版本不兼容。可以尝试手动安装指定版本的依赖包,例如 pip install package_name==version_number。 模型文件加载失败 问题描述:启动可视化界面时,提示模型文件加载失败。 解决方法: 检查模型文件是否完整下载并解压到正确的目录。 确保代码中配置的模型路径与实际模型文件路径一致。 GPU 加速未生效 问题描述:计算机配备了 NVIDIA GPU,但在运行过程中未使用 GPU 加速。 解决方法: 检查 NVIDIA 驱动、CUDA 和 cuDNN 是否正确安装并配置。 在代码中添加相应的 GPU 配置代码,例如: import torch device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device) 六、总结 通过以上步骤,你可以轻松地在本地环境实现 DeepSeek 满血版的傻瓜式、可视化部署。在部署过程中,按照准备工作的要求确保硬件和软件环境的正确性,严格遵循部署步骤进行操作。遇到问题时,参考常见问题及解决方法进行排查和修复。 -
 DeepSeek 本地部署AI对话网页版 DeepSeek 本地部署AI对话网页版 安装指南 安装 ollama 访问 https://www.ollama.com/ ,下载安装包,安装 ollama 安装deepseek-r1:7b模型 访问 https://www.ollama.com/library/deepseek-r1 ,在命令行执行如下命令,安装deepseek-r1:7b模型 ollama run deepseek-r1:14b 下载本项目代码,DeepSeek 本地部署AI对话网页版 下载本项目代码。 git clone https://gitee.com/deepseeklocal/deepseek-local.git 安装nodejs 访问 https://nodejs.org/zh-cn/download ,下载安装包,安装nodejs 进入deepseek-local目录,运行如下命令,启动nodejs服务 npm install node app.js 访问 http://localhost:8888 ,即可看到DeepSeek 本地部署AI对话网页版 管理员默认登录账号: admin 密码:111111 点击“聊天”,即可看到DeepSeek 本地部署AI对话网页版
DeepSeek 本地部署AI对话网页版 DeepSeek 本地部署AI对话网页版 安装指南 安装 ollama 访问 https://www.ollama.com/ ,下载安装包,安装 ollama 安装deepseek-r1:7b模型 访问 https://www.ollama.com/library/deepseek-r1 ,在命令行执行如下命令,安装deepseek-r1:7b模型 ollama run deepseek-r1:14b 下载本项目代码,DeepSeek 本地部署AI对话网页版 下载本项目代码。 git clone https://gitee.com/deepseeklocal/deepseek-local.git 安装nodejs 访问 https://nodejs.org/zh-cn/download ,下载安装包,安装nodejs 进入deepseek-local目录,运行如下命令,启动nodejs服务 npm install node app.js 访问 http://localhost:8888 ,即可看到DeepSeek 本地部署AI对话网页版 管理员默认登录账号: admin 密码:111111 点击“聊天”,即可看到DeepSeek 本地部署AI对话网页版 -
 如何将 Chatbox 连接到远程 Ollama 服务 现在有越来越多的开源模型,可以让你在自己的电脑或服务器上运行。使用本地模型有许多优势: 完全离线运行,保护隐私数据安全 无需支付在线 API 费用 完全离线,服务稳定,无网络延迟 可以自由调整和定制模型参数 Chatbox 可以很好地连接到 Ollama 服务,让你在使用本地模型时可以获取 Chatbox 提供的更多强大功能,比如 Artifact Preview、文件解析、会话话题管理、Prompt 管理等。 (注意:运行本地模型对你的电脑配置有一定要求,包括内存、GPU 等。如果出现卡顿,请尝试降低模型参数。) 安装 Ollama Ollama 是一个开源的本地模型运行工具,可以方便地下载和运行各种开源模型,比如 Llama、Qwen、DeepSeek 等。这个工具支持 Windows、MacOS、Linux 等操作系统。 Ollama 下载地址 https://ollama.com/ 下载并运行本地模型 下载并安装 Ollama 后,请打开命令行终端,输入命令下载并运行本地模型。你可以在这里查看到所有 ollama 支持的模型列表:Ollama 模型列表。 举例1:下载并运行 llama3.2 模型 ollama run llama3.2 举例2:下载并运行 deepseek-r1:8b 模型(注意:Ollama 上的 DeepSeek R1 模型实际上是蒸馏模型) ollama run deepseek-r1:8b 在 Chatbox 中连接本地 Ollama 服务 在 Chatbox 中打开设置,在模型提供方中选择 Ollama,即可在模型下拉框中看见你运行的本地模型。 点击保存,即可正常聊天使用。 在 Chatbox 中连接远程 Ollama 服务 除了可以轻松连接本地 Ollama 服务,Chatbox 也支持连接到运行在其他机器上的远程 Ollama 服务。 例如,你可以在家中的电脑上运行 Ollama 服务,并在手机或其他电脑上使用 Chatbox 客户端连接到这个服务。 你需要确保远程 Ollama 服务正确配置并暴露在当前网络中,以便 Chatbox 可以访问。默认情况下,需要对远程 Ollama 服务进行简单的配置。 如何配置远程 Ollama 服务? 默认情况下,Ollama 服务仅在本地运行,不对外提供服务。要使 Ollama 服务能够对外提供服务,你需要设置以下两个环境变量: OLLAMA_HOST=0.0.0.0 OLLAMA_ORIGINS=* 在 MacOS 上配置 1、打开命令行终端,输入以下命令: launchctl setenv OLLAMA_HOST "0.0.0.0" launchctl setenv OLLAMA_ORIGINS "*" 2、重启 Ollama 应用,使配置生效。 在 Windows 上配置 在 Windows 上,Ollama 会继承你的用户和系统环境变量。 1、通过任务栏退出 Ollama。 2、打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。 3、点击编辑你账户的环境变量。 为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 *。 4、点击确定/应用以保存设置。 5、从 Windows 开始菜单启动 Ollama 应用程序。 在 Linux 上配置 如果 Ollama 作为 systemd 服务运行,应使用 systemctl 设置环境变量: 1、调用 systemctl edit ollama.service 编辑 systemd 服务配置。这将打开一个编辑器。 2、在 部分下为每个环境变量添加一行 Environment: Environment="OLLAMA_HOST=0.0.0.0" Environment="OLLAMA_ORIGINS=*" 3、保存并退出。 4、重新加载 systemd 并重启 Ollama: systemctl daemon-reload systemctl restart ollama 服务 IP 地址 配置后,Ollama 服务将能在当前网络(如家庭 Wifi)中提供服务。你可以使用其他设备上的 Chatbox 客户端连接到此服务。 Ollama 服务的 IP 地址是你电脑在当前网络中的地址,通常形式如下: 192.168.XX.XX 在 Chatbox 中,将 API Host 设置为: http://192.168.XX.XX:11434 注意事项 可能需要在防火墙中允许 Ollama 服务的端口(默认为 11434),具体取决于你的操作系统和网络环境。 为避免安全风险,请不要将 Ollama 服务暴露在公共网络中。家庭 Wifi 网络是一个相对安全的环境。
如何将 Chatbox 连接到远程 Ollama 服务 现在有越来越多的开源模型,可以让你在自己的电脑或服务器上运行。使用本地模型有许多优势: 完全离线运行,保护隐私数据安全 无需支付在线 API 费用 完全离线,服务稳定,无网络延迟 可以自由调整和定制模型参数 Chatbox 可以很好地连接到 Ollama 服务,让你在使用本地模型时可以获取 Chatbox 提供的更多强大功能,比如 Artifact Preview、文件解析、会话话题管理、Prompt 管理等。 (注意:运行本地模型对你的电脑配置有一定要求,包括内存、GPU 等。如果出现卡顿,请尝试降低模型参数。) 安装 Ollama Ollama 是一个开源的本地模型运行工具,可以方便地下载和运行各种开源模型,比如 Llama、Qwen、DeepSeek 等。这个工具支持 Windows、MacOS、Linux 等操作系统。 Ollama 下载地址 https://ollama.com/ 下载并运行本地模型 下载并安装 Ollama 后,请打开命令行终端,输入命令下载并运行本地模型。你可以在这里查看到所有 ollama 支持的模型列表:Ollama 模型列表。 举例1:下载并运行 llama3.2 模型 ollama run llama3.2 举例2:下载并运行 deepseek-r1:8b 模型(注意:Ollama 上的 DeepSeek R1 模型实际上是蒸馏模型) ollama run deepseek-r1:8b 在 Chatbox 中连接本地 Ollama 服务 在 Chatbox 中打开设置,在模型提供方中选择 Ollama,即可在模型下拉框中看见你运行的本地模型。 点击保存,即可正常聊天使用。 在 Chatbox 中连接远程 Ollama 服务 除了可以轻松连接本地 Ollama 服务,Chatbox 也支持连接到运行在其他机器上的远程 Ollama 服务。 例如,你可以在家中的电脑上运行 Ollama 服务,并在手机或其他电脑上使用 Chatbox 客户端连接到这个服务。 你需要确保远程 Ollama 服务正确配置并暴露在当前网络中,以便 Chatbox 可以访问。默认情况下,需要对远程 Ollama 服务进行简单的配置。 如何配置远程 Ollama 服务? 默认情况下,Ollama 服务仅在本地运行,不对外提供服务。要使 Ollama 服务能够对外提供服务,你需要设置以下两个环境变量: OLLAMA_HOST=0.0.0.0 OLLAMA_ORIGINS=* 在 MacOS 上配置 1、打开命令行终端,输入以下命令: launchctl setenv OLLAMA_HOST "0.0.0.0" launchctl setenv OLLAMA_ORIGINS "*" 2、重启 Ollama 应用,使配置生效。 在 Windows 上配置 在 Windows 上,Ollama 会继承你的用户和系统环境变量。 1、通过任务栏退出 Ollama。 2、打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。 3、点击编辑你账户的环境变量。 为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 *。 4、点击确定/应用以保存设置。 5、从 Windows 开始菜单启动 Ollama 应用程序。 在 Linux 上配置 如果 Ollama 作为 systemd 服务运行,应使用 systemctl 设置环境变量: 1、调用 systemctl edit ollama.service 编辑 systemd 服务配置。这将打开一个编辑器。 2、在 部分下为每个环境变量添加一行 Environment: Environment="OLLAMA_HOST=0.0.0.0" Environment="OLLAMA_ORIGINS=*" 3、保存并退出。 4、重新加载 systemd 并重启 Ollama: systemctl daemon-reload systemctl restart ollama 服务 IP 地址 配置后,Ollama 服务将能在当前网络(如家庭 Wifi)中提供服务。你可以使用其他设备上的 Chatbox 客户端连接到此服务。 Ollama 服务的 IP 地址是你电脑在当前网络中的地址,通常形式如下: 192.168.XX.XX 在 Chatbox 中,将 API Host 设置为: http://192.168.XX.XX:11434 注意事项 可能需要在防火墙中允许 Ollama 服务的端口(默认为 11434),具体取决于你的操作系统和网络环境。 为避免安全风险,请不要将 Ollama 服务暴露在公共网络中。家庭 Wifi 网络是一个相对安全的环境。